32: Confidence intervals, p-values, effect size and statistical significance
Alexander Olaussen, Gerard O’Reilly
Learning outcomes
Definitions
- • Confidence intervals: The range of potential effect sizes.
- • p-value: The probability of observing an equal or more extreme result given the null hypothesis is true (i.e. assuming no difference between groups).
- • Effect size: The magnitude of the measure of association or difference.
- • Statistical significance: The confidence in the effect being real (i.e. not occurring by chance).
Introduction
When we compare two things, how can we tell if that difference is likely to be true or just random variation between the samples, and how confident are we in our conclusion about this? These questions form the foundation for common statistical concepts such as p-values and confidence intervals covered in this chapter. The following concepts are described in a variety of ways across the literature and it has been demonstrated that 89% of textbooks incorrectly define or explain statistical significance—so be cautious.1
Steps in hypothesis testing
Before discussing p-values and statistical significance, it is worth revising the steps in hypothesis testing—which to the novice researcher can seem somewhat counterintuitive. Let’s say we hypothesise that ketamine is effective in reducing the respiratory rate (RR) in asthma. We would do the following steps in statistical methods. First, we would create our null hypothesis (H0), which is that there is no difference in the RR between the patients given ketamine and those that are given placebo (or something else). As the ketamine may both increase and decrease the RR, we should choose a two-tailed test (because we are agnostic as to which direction the impact of ketamine may be). We would then collect data on patients who received and did not receive ketamine (ideally in a randomised controlled trial, but the statistics would be the same for observational studies). We would decide our significance level (i.e. alpha) below which we will reject the H0 (thus making our initial or alternate hypothesis true). The alpha for the vast majority of articles is arbitrarily and conventionally set at 5% or 0.05. This means that we accept a 1 in 20 probability that what we observe may be due to chance.
Confidence intervals
Let’s say we have 200 patients in our ketamine trial. When reporting the age of the cohort, we would first look at a histogram of the age and determine if that data is distributed normally (i.e. parametric) or skewed to one side (i.e. non-parametric) (see Figure 32.1).

For parametric distributions (of continuous data) we should report the mean (i.e. the point estimate) and the standard deviation.
Now, for the 95% confidence interval (CI) of the difference in mean age (i.e. the effect size or measure of association between the two groups)—which is 1.96 standard deviations (of the effect size) either side of the calculated difference in mean age (also named as the ‘1.96 standard errors of the difference in means’)—describes a range within which 95% of the real (population) effect size will lie (e.g. for a difference in mean age of xx, the 95%CI = a difference in mean age between xx and xx years). See Figure 32.2.

p-value
The p-value can be defined as follows: ‘the p-value is the probability of obtaining our results, or something more extreme, if the null hypothesis is true’.2 While p-values are calculated on statistical software, it is valuable to understand the formulas which underpins them. First, consider the variance—a measure of spread which is calculated by considering how far away from the mean each observation is. If the spread of RR observations in either group (ketamine or placebo) is small in either direction, then the variance would be small, but if the spread of RR observations is large, then the variance is large.
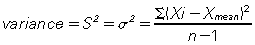
Now that we have the variance, we can calculate the t statistic, which is worked out as follows:
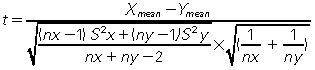
Where Xmean and Ymean are the mean (RRs) in the ketamine group and the non-ketamine group, respectively; nx and ny is the number of patients in each of those two groups; and S2x and S2y is the variance in each group. The resultant t-value can then be located in a ‘t-test table’ and the p-value revealed.
Although the above formulae may appear daunting, be reassured by the fact that very few researchers know these automatically. The reason for presenting the formulae here is to highlight the importance of sample size. With increasing sample size, the variance will shrink and thus be producing statistically significant p-values more often. This is particularly relevant in the setting of large volumes of data (i.e. big data) and repeated testing (e.g. with artificial intelligence). Since there is nothing in this world that is identical to another thing—even two snowflakes—the only relevant question then is clinical relevance.3
p-values have attracted much debate, emotions and misuse in the medical literature.4 In 2016, the American Statistical Association published six guiding principles regarding the reporting of p-values to alleviate some of the confusion and misuses.5
- 1. p-values can indicate how incompatible the data are with a specified statistical model.
- 2. p-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.
- 3. Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold.
- 4. Proper inference requires full reporting and transparency.
- 5. A p-value, or statistical significance, does not measure the size of an effect or the importance of a result.
- 6. By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.
Statistical significance versus clinical significance
When considering the word significance, synonyms such as important and meaningful come to mind. The concept of clinical significance or clinical importance—but not statistical significance—deals with these concepts. For instance, if drug A lowers the blood pressure by 2 mmHg more than drug B (i.e. the effect size is a difference in mean systolic blood pressure of 2 mmHg), that is probably not clinically meaningful or significant, although with enough patient data this difference would be reported as statistically significant. On the other hand, statistical significance deals with whether or not the observed difference between drug A and drug B are likely to have arisen by chance or whether the difference is truly present. As mentioned previously—since nothing is identical—the latter will always be the case.
Examples
The PARAMEDIC2 trial, which compared adrenaline/epinephrine to placebo in cardiac arrest, reported that ‘in the epinephrine group, 130 patients (3.2%) were alive at 30 days, as compared with 94 patients (2.4%) in the placebo group (unadjusted odds ratio for survival, 1.39; 95% confidence interval [CI], 1.06 to 1.82; p = 0.02)’.6
This means that if we repeated the trial many times, the odds ratio (i.e. the effect size) of adrenaline/epinephrine would end up being somewhere between 1.06 and 1.82, 95% of the time. Another acceptable way of interpreting this is that we are 95% certain that the true (i.e. population) results lie somewhere between 1.06 (the lower confidence limit) and 1.82 (the upper confidence limit). The p-value of 0.02 tells us the result is statistically significant (i.e. less than 5% chance of obtaining this result by chance). We can also conclude that the result (odds ratio) is statistically significant because the CI did not cross one.
Conclusion
Null-hypothesis significance testing is a critical component of research. p-values and CIs provide suggestions as to whether or not we should reject the null hypothesis (i.e. whether or not what we have observed is true or not). If the probability of obtaining the result (or something even more extreme) is less than our pre-determined significance level (typically 0.05, or 5%), then we reject the null hypothesis and conclude there is evidence to support the alternative hypothesis.
Review questions
- 1. Consider the difference between statistical and clinical significance. Think of examples that may be statistically significant but not clinically significant. And conversely, is it possible to have clinically significant findings that are not statistically significant?
- 2. Given the fact that an increasing sample size decreases the variance and tightens the confidence interval, what implications does this carry in terms of calculating and interpreting statistical significance for small and large studies?
- 3. How do you decide what a clinically significant change is?
Suggested further reading
Ioannidis JPA. Why most published research findings are false PLOS Medicine. 8, 2005;2: e124.
Kirkwood B. & Sterne J. Essentials of Medical Statistics 2nd ed 2003; Blackwell Publishing Oxford.
Wasserstein RL & Lazar NA. The ASA Statement on p-Values: Context, Process, and Purpose The American Statistician. 2, 2016;70: 129-133.
References
1. Cassidy SA, Dimova R, Giguère B, Spence JR & Stanley DJ. Failing grade: 89% of introduction-to-psychology textbooks that define or explain statistical significance do so incorrectly Advances in Methods and Practices in Psychological Science. 3, 2019;2: 233-239.
2. Petrie A & Sabin C. Medical statistics at a glance 3rd ed 2009; Wiley-Blackwell Singapore.
3. Krevat, E Tucek, J Ganger & GR. Disks are like snowflakes: no two are alike 2011; HotOS.
4. Olaussen A, Abetz J, Qin KR, Mitra B & O’Reilly G. Misleading medical literature: an observational study Emerg Med Australas. 2021.
5. Wasserstein RL & Lazar NA. The ASA Statement on p-Values: Context, Process, and Purpose The American Statistician. 2, 2016;70: 129-133.
6. Perkins GD, Ji C, Deakin CD & et al. A randomized trial of epinephrine in out-of-hospital cardiac arrest New England Journal of Medicine. 8, 2018;379: 711-721.
7. Ioannidis JPA. Why most published research findings are false PLOS Medicine. 8, 2005;2: e124.