Chapter Three Sampling methods and external validity
Introduction
Research in the health sciences usually involves the collection of information from a sample of participants, rather than on the entire population in which the investigator is interested. Studies that involve an entire population or group are called census studies but these are relatively rare and generally expensive to perform. A sample drawn from the target population is studied because it is usually impossible or too costly to study entire populations. For instance, when individuals who have conditions such as diabetes, cerebral palsy or emphysema are being studied, it is not possible to study everyone because of the large size of such populations. Also because many people do not seek treatment or may be wrongly diagnosed, we may not be able to identify all members of the entire population in order to study them. Therefore, in most research, the researcher studies a subset or sample of the target population, and then attempts to generalize the findings to the population from which the participants were drawn. This general principle applies to both qualitative and quantitative studies.
The aim of this chapter is to examine ways that samples can be drawn to permit the investigator to make valid generalizations from the study sample to the target population. We will also consider the question of generalizing the findings of an investigation to other samples and situ-ations. This is referred to as ‘external validity’ or ‘generalizability’.
What is sampled in a study
While this chapter will focus on the selection of the research participants in a study, many other things are also selected or sampled. These include:
Many researchers focus on the selection of the research participants as the key or only issue in maximizing the generalizability of their research, and they do not pay enough attention to the other factors they are sampling or the context in which the research is being conducted. It is not at all unusual to see studies that employ large and sophisticated participant samples, yet with only one or two highly selected clinicians involved in the research in perhaps only one health setting. While the study sample may be highly representative, the context in which the research is conducted may not be and it may be that the researchers and clinicians involved in the study have a particularly unusual or idiosyncratic approach to their work that is not reflective of others. It is our contention that in many qualitative studies there is strong consider-ation of the research context and its impact upon the research findings. However, there is often less emphasis upon sampling of research participants. This impacts upon the ability to generalize the findings more broadly from the actual research participants to other groups.
Basic issues in sampling
As we have discussed, often, because of the numbers involved, it is not within the resources of the researcher to study the whole target population. In any event, in most situations it would be wasteful to study all of the population. If a sample is representative, one can generalize validly from the sample’s results to the population without going to the expense of studying everyone.
The population is the target group of individ-uals or cases in which the researcher is interested. Examples of valid study populations include: all English women under 25; all children with diagnosed spina bifida in the state of Alberta; all the students at a particular Australian college. The researcher defines the population to which he/she wishes to generalize. Note that a population need not consist of human or animal subjects. Objects or events can also be sampled, as shown in Table 3.1.
Table 3.1 Examples of populations and samples
| Population | Possible sample selection |
|---|---|
| All working podiatrists in a state | 50 podiatrists selected for a study of job satisfaction |
| All working pathologists in a state | 25 pathologists selected for detailed tax evaluation by an inspector |
| The temperature of a patient during a 24-hour period | Hourly measurements of the patient’s temperature recorded by staff |
| Stuttering in a child’s speech | Number of stutters made during 5 minutes of reading a standard piece of material |
| All patients in a state with frontal lobe damage | 30 patients with frontal lobe damage selected for evaluating a rehabilitation programme |
| All surgical gauzes held by a given hospital | 10 gauzes selected by a bacteriologist to test for sterility |
As shown in Table 3.1, a population is an entire set of persons, objects or events which the researcher intends to study. A sample is a subset of the population. Sampling involves the selection of the sample from the population.
Representative samples
There is a variety of different ways by which one can select the sample from the population. These are called sampling methods.
The ultimate aim of all sampling methods is to draw a representative sample from the population. The advantage of a representative sample is clear: one can confidently generalize from a representative sample to the rest of the population without having to take the trouble of studying the rest of the population. If the sample is biased (not representative of the population) one can generalize less validly from the sample to the population. This might lead to quite incorrect conclusions or inferences about the population. This would mean that the results obtained in the study would not neces-sarily generalize to other studies using the same population. Figure 3.1 illustrates the concept of a representative sample.
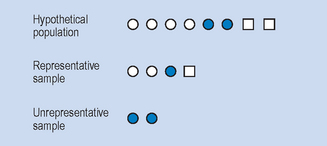
Figure 3.1 illustrates a hypothetical population composed of three different types of study participants or categories of participants. A representative sample is a precise miniaturized representation of the population. An unrepresentative or biased sample does not adequately represent the key groups or characteristics in the population, and this may lead to mistaken conclusions about the state of the population.
The selection of the appropriate sampling method depends upon the aims and resources of the researchers. For instance, if someone is designing a very expensive health or social welfare programme on the basis of a survey of clients’ needs, it is imperative that the researcher uses a good sampling method and obtains a representative sample of the clients, so that appropriate conclusions may be reached about the population. Good sampling methods are somewhat more expensive and more difficult to implement than poor methods but they are worth it. The main sampling methods used in health research are incidental and random sampling.
Incidental samples
Incidental sampling is the cheapest, easiest and most commonly used sampling method in clin-ical studies. It involves the selection of the most accessible and available members of the target population. For example, a researcher who stands in the middle of a city street and quizzes people about their health status is practising incidental sampling. However, it is quite likely that this sample would not be representative of the general voting population. There would probably be an over-representation of businessmen and white-collar workers, and an under-representation of factory workers and housewives. The sample is likely to be unrepresentative and biased.
A further example of incidental sampling might involve a researcher surveying the needs of a group of spina bifida children at a local community health centre. Their measured needs may be representative of those of other spina bifida children, but then again they may not if these children are not typical of the wider population of children with spina bifida.
Thus, incidental sampling is cheap and easy to implement but may give a biased sample that is not representative of the population.
Quota sampling
Sometimes it is known in advance that there are important subgroups within the population that need to be included in the sample. Two such important groups within the human population are males and females. Further, it is known that they occur in the ratio of approximately 49:51 in the general population. Our researcher might decide that it is very important that the sexes are proportionally represented in the sample. Thus, the researcher would set two quotas (of 49 male and 51 female respondents in a sample of 100) and sample accordingly in a city street. This is still a form of incidental sampling but has some significant advantages over simple incidental sampling because the study sample’s composition on this key demographic variable is guaranteed to match that of the target population.
More sophisticated examples involving more than two groups can be accommodated as shown in Table 3.2. We can see from Table 3.2 that if our sample were to be representative regarding both sex and occupational status, in a sample of 100 people we would need 19 blue-collar males, 15 blue-collar females, and so on.
Table 3.2 Distribution of percentages of gender and occupational variables in the general population
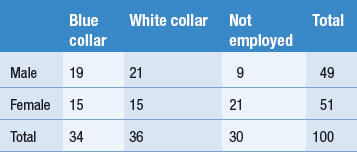
Quota sampling still has a number of shortcomings: before it can be used, one has to know which population groups are likely to be important to a particular question and the exact proportions of the various groups in the population. Sometimes we may not know these proportions. Also, the members of the sample within the quotas are still incidentally chosen. The blue-collar males, for example, selected in a city centre on a weekday may still be quite different from those working elsewhere. However, quota sampling is better than simple incidental sampling.
Random and systematic samples
Random sampling
This is one of the best but probably more expensive sampling methods to implement in drawing a study sample. A random sample is one in which all members of the population have an equal chance of selection. Thus a random sample is more likely to be representative of the relevant population than an incidental sample.
The procedure for drawing a random sample involves:
A simple example of a random sample is provided by a common raffle, where names on (preferably!) equal-size papers are put in a hat, shaken and selected ‘blind’. Many national and state lotteries use numbered balls that are drawn randomly from a barrel. Another way to draw a random sample is to construct a list of all the members of the population and assign a number to each element. Then a table of random numbers, generated by a com-puter, could be used to select a random sample.
Cases that are selected from a list using a random selection method constitute a random sample. Sometimes, because of issues such as refusal to participate in the study, dropping out and failure to satisfy the sample inclusion criteria, it is necessary to select replacements for some cases that are unavailable for the study. This can introduce bias into the sample, as the people who refuse may differ consistently from those who accept or volunteer. This impact on sampling validity is sometimes called the volunteer effect.
However, random sampling methods have a number of important advantages over incidental or non-random methods:
The major disadvantages of random sampling methods are:
Stratified random sampling
This involves the same approach as quota sampling with set quotas from specific subgroups, except that each quota is filled by randomly sampling from each subgroup, rather than sampling incidentally. For example, if one was drawing a sample stratified with respect to sex, one would prepare a list of all females and all males in the target population and then sample randomly from these lists with the numbers of each group in the sample corresponding to the population proportions. These groups collectively are called the strata.
The advantages of stratified random sampling are:
Area sampling
In area sampling, one samples on the basis of location of cases. For example, on the basis of census data the investigator may select several areas in a city or county with known characteristics, such as high or low unemployment rates. The areas could then be further divided into specific streets and the occupants of, say, every third house contacted for participation in the study. In other words, the locations are randomly selected and then one interviews the occupants of those locations. This can be a very effective, cheap method of sampling in social surveys. It does not require a list of the individual members of the population, merely the location where they live. Recent research has shown that where people live can be an important factor in their health status and their use of health services. The study of the impact of where people live upon health and social issues is sometimes called (geo-) spatial analysis.
Systematic sampling
This involves working through a list of the population and choosing, say, every 10th or 20th case for inclusion in the sample. It is not a truly random technique but it will usually give a representative sample. It is based on the (usually justified) supposition that cases are not added to the list in a systematic way which coincides with the sampling system. Provided a list of cases is available, systematic sampling is an easy and convenient sampling method. In clinical practice we are using systematic sampling when, for instance, we measure temperature and blood pressure every hour.
Sample size
One of the most poorly understood aspects of sampling is the number of cases that should be included in a study sample. The whole issue of sampling is conceptualized somewhat differently for qualitative and quantitative studies, although the issue of to what extent the results of a study are generalizable is the same whatever the study design.
It is obvious that in one sense the more cases selected the merrier (or the better the sample representativeness), but the costs associated with the sampling and data collection must be weighed up against the greater generalizability that is generally associated with larger samples. Also, some studies may involve discomfort, pain or even danger to patients or laboratory animals. Therefore, in this case it is ethically and logistically desirable to ensure that no more than the bare minimum of subjects is used to achieve the desired sample accuracy. Health researchers ‘walk a tightrope’ in deciding the optimum sample sizes for their studies. However, there are some principles available to guide the researcher.
First of all, let us say quite definitely that there is no magic number that we can point to as an ‘optimum’ sample size. Rather, the optimum sample size depends on the characteristics of an investigation in the context of which the sample is drawn. In general, the optimum sample size is one which is adequate for making correct generalizations from the sample to the target population. Let us discuss these issues by introducing the concept of sampling error.
Sampling error
In the quantitative research framework, sampling error is the discrepancy between the true population parameter and the sample statistic. For example, if I happen to know from census data that the actual average age of males in a district is 35 years and the average age of a sample of males I have surveyed from the district is 30 years, then I have a sampling error of 5 years. However, if we do not know the actual population parameters (which is commonly the case), we can only estimate the probable sampling error.
Sampling error is related to sample size by the following relationship:

What the above equation claims is that the greater the sample size (n), the smaller the probability sampling error. In fact, the sampling error in a study sample is inversely proportional to the square root of the sample size.
From this relationship it can be seen that doub-ling the sample size would only result in a reduction of the error by a factor of the square root of 2 (1.414). Similarly, a ninefold increase in sample size would result in only a threefold reduction in the sampling error. Figure 3.2 illustrates this point by showing the graphical relationship between probable sampling error and sample size.
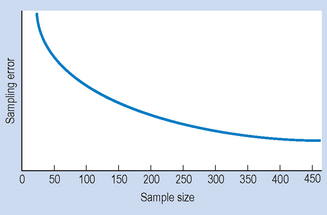
Figure 3.2 The relationship between sample size and sampling error. The scaling but not the form of the curve will alter with the variability of the data.
It can be seen from this graph that not much is gained from a sample size of over, say, n1. Yet the cost of the sampling and data collection can be very high with large numbers (such as n2), for relatively little gain in reducing sampling error. In some research situations, even large probable sampling errors have relatively little potential influence on our decisions. In such situations, we can live with a relatively small sample size. In other situations, we need large samples to justify our confidence in the truth of our decisions.
As an illustration, suppose that we are attempting to predict the outcome of an election fought between two political parties, A and B. A representative sample of 100 respondents is polled before the election. Say the outcome is as follows:
| Intends to vote for A | Intends to vote for B | Estimated sampling error |
|---|---|---|
| 25% | 75% | 10% |
In this instance, the estimated sampling error is very small in relation to the size of the effect (that is, the difference between the percentage of intended votes for the two parties). We can predict confidently, assuming that the respondents were truthful and don’t change their minds before the elections, that political party B will romp into government. Increasing sample size, say to 10 000, would enormously increase the cost of the survey. The corresponding reduction in sampling error would not justify this cost, as we would still come to the same conclusion. However, say the following sample statistics were obtained in the pre-election poll of n = 100 respondents:
| Intends to vote for A | Intends to vote for B | Estimated sampling error |
|---|---|---|
| 48% | 58% | 10% |
Now the same level of estimated sampling error is too large, in relation to the apparent size of the effect, to make a decision concerning which party is likely to win the election. The poll would have to be repeated using a substantially increased sample size to reduce the sampling error.
The example illustrates the notion that the adequacy of the sample size is affected by the specific situation that we are trying to research. A sample size which is adequate in one situation may be inadequate in another. One benefit of a previous pilot study is that it allows the researcher to estimate the size of the phenomenon under study, and thereby make a more educated guess concerning the sample size required. The concept of statistical ‘power’ or the ability to detect real effects or differences is discussed later in this text.
Sampling issues in qualitative research
Qualitative research shares with quantitative research a concern with the extent to which findings from one study can be generalized to other settings and people. Therefore the representativeness of the information obtained from the sample is important in qualitative research. However, there are differences in the way in which a representative sample is conceptualized in qualitative research.
The key difference is the way in which the population is defined. In quantitative research we make the assumption that there is a true knowable state of the population. The true state of the population is represented by an actual parameter, such as ‘49% of the Australian population are females’ or ‘the average IQ of Canadian high school students is 104’. Qualitative research is not concerned with measuring quantities or counting frequencies but with the experiences and meanings of these experiences for individuals and communities. Sampling in qualitative research is referred to as purposive; the researchers deliberately select the participants who are best placed to provide the information for understanding the personal meanings of health-related events. For example, what is it like to survive a heart attack? What does it mean for patients to undergo transplantation surgery? Our sample provides the information which enables us to understand the emotional processes of coping with a heart attack or the psychological demands of being an organ recipient.
Let us consider an example of this approach. Say that you are intending to conduct qualitative research for clarifying issues relevant to the problem of family or ‘domestic’ violence. The first step would be to clarify the specific aspect of the problem you were studying and define the issues in which you were interested. For example, say that you wanted to collect data concerning the impact of physical violence on the lives of women. A key issue in defining the population is the cultural and historical setting in which it is enmeshed. The moral, legal and health-related problems involved in domestic violence are varied across cultures and change with time. In Western societies it is only relatively recently that violence in domestic settings has been recognized as a serious crime and this influences the experiences of the people involved in the events. Therefore, it is essential to define carefully the cultural characteristics of the group being studied and to keep in mind that we must be very cautious in generalizing the findings from one study to other settings and people.
Purposive sampling
Qualitative sampling is designed to be purposive, i.e. to select cases for inclusion in the research that are likely to be illustrative of particular issues or circumstances. Patton (1990) has proposed a typology of sampling that is widely used in qualitative research. Table 3.3 shows nine of the commonly used purposive sampling methods. Interested readers can follow up in Patton (1990) or Liamputtong Rice & Ezzy (1999) for more detailed information.
Table 3.3 Nine of the commonly used purposive sampling methods
| Sampling method | Brief description of sampling strategy |
|---|---|
| Extreme or deviant case sampling | The cases in these methods are chosen because of their deviance and the hope that this deviance may illustrate issues about more regular or mainstream cases |
| Maximum variation sampling | Purposefully picking a wide range of variation on dimensions of interest. Documents unique or diverse variations that have emerged in adapting to different conditions. Identifies important common patterns that cut across variations |
| Homogenous sampling | Focuses, reduces variation, simplifies analysis, facilitates group interviewing |
| Stratified purposeful sampling | Illustrates characteristics of particular subgroups previously found to be of interest. Facilitates comparisons of issues across groups |
| Snowball or chain sampling | Identifies cases of interest from contacts who know of suitable interview participants; that is, people who are likely to be good sources of information |
| Theory-based or operational construct sampling | Finding manifestations of theoretical construct of interest so as to elaborate and examine the construct |
| Opportunistic sampling | Following new leads during fieldwork, taking advantage of the unexpected, flexibility for discovering new issues |
| Random purposive sampling | (Still small sample size.) Adds credibility to sample when potential purposeful sample is larger than one can handle. Reduces judgment within a purposeful category. Unlike qualitative research, this strategy is not used for generalizations or representativeness |
| Convenience sampling | Similarly to quantitative sampling, this strategy saves time, money and effort. Poorest rationale, lowest credibility for findings. Yields information-poor cases |
To illustrate qualitative sampling we have selected four strategies. Considering the example of physical violence against women in domestic settings, what would be the researcher’s purpose for selecting the following strategies?
To summarize, we want to make sure the people we are interviewing or the situations we are observing are representative of the targeted issues. We want to gain as complete a picture of the issues from the perspectives of our participants as possible. The usual approach to qualitative sampling is to interview or observe people in situations that fit our criteria until we have reached a point where little or no new observations are being made. This is called saturation.
External validity and sampling
The term external validity refers to the extent to which the results of an investigation can be generalized to other samples or situations. External validity can be classified into two types: population and ecological (Huck et al 1974).
Population validity
This refers to generalizing the findings from the sample to the population from which it was drawn. We have already examined the importance of having a representative sample in the generalizing of results from a sample to a population. However, an investigator in the health sciences might face another problem; that the accessible population from which the sample was taken might not be the same as the target population, that is, the one of general interest.
Let us illustrate this point with an example. A physiotherapist working in a large private maternity hospital intends to examine the effectiveness of a new antenatal exercise procedure for pregnant women for controlling levels of pain during delivery. A random sample of 50 pregnant women is chosen for the investigation from the population attending the hospital. The sample is then randomly assigned into two groups: one receiving the new antenatal exercise procedure, the other receiving the traditional programme. The researcher finds a statistically and clinically significant difference between the two procedures, such that the new programme is shown to be effective.
Strictly speaking, these findings can be generalized only to the population of women who attend the hospital. If the target population is all women who are having babies, then the generalization will lack external validity, because women attending different hospitals or having children at home had no chance of being included in the study sample. They might have different characteristics and these different characteristics may interact with the treatment in different ways to that of the sample. For instance, women who chose to deliver at home might respond better than those who chose to go to hospital but we would not know this from this study.
Ecological validity
There is another facet of external validity: the situation in which an investigation is carried out might not be generalizable to other situations. This is called ecological validity. Consider the following examples:
The above examples illustrate the caution necessary in generalizing findings.
Summary
Appropriate sampling strategies ensure the external validity of studies and their findings. The aim of sampling strategies is to ensure the selection of a sample that is representative of the population of objects, persons or events the investigator aims to study. Incidental and quota samples are chosen for convenience, but these sampling strategies do not guarantee a representative sample. Random and stratified random sampling methods ensure that all important groups and characteristics in the population have the best chance to be selected and included in the study sample. Random sampling strategies are the most desirable to obtain a representative sample, although random sampling is not always feasible or desirable in health research. Area sampling and systematic sampling are also strategies that can be used to obtain representative samples.
An adequate sample size reduces the chance of large sampling errors. The probable sampling error is inversely proportional to the square root of the sample size. It was argued that optimum sample size is not the maximum number of obtainable subjects or a constant number or proportion. Rather, it has to be estimated for a specific investigation on the basis of the parameters of the phenomenon being studied and the study circumstances. Two types of external validity were discussed: population and ecological. External validity is related to inference, which involves using evidence from a limited set of elements to formulate general propositions.
Various approaches to purposive sampling in qualitative research were reviewed and an example of their application to a hypothetical study situation was presented.
Self-assessment
Explain the meaning of the following terms: