Appendix E Herbal clinical trial papers: how to read them
Clinicians are faced with an ever-increasing amount of reading material as more research that is clinical is published on herbal medicine. This appendix is designed to assist in the reading of clinical trials and covers the following issues:
• What a randomised controlled trial is
• Why they are important (but are not without limitations)
• A comparison between herbal and conventional medicine in published literature
• The structure of a clinical trial paper
• How to identify a badly written paper
• What to look for when you decide to keep reading
• How to interpret the trial dosages and their relevance to the products you use.
What are randomised controlled trials?
In the hierarchy of generating scientific evidence, randomised controlled trials (RCTs) are considered the gold standard.1 A randomised clinical trial involves at least one test treatment (such as a herbal medicine) and one control treatment (a placebo or standard treatment, such as a drug). Patients are allocated to the treatment groups by a random process (use of a random-numbers table) to eliminate selection bias and confounding variables. (Note: the toss of a coin, patient social security numbers, days of the week and medical record numbers are considered unacceptable methods for randomisation). For randomisation to be successful, the allocation must remain concealed. In RCTs, some form of blinding or masking is also usually applied. Although the definitions vary, a trial can be considered double blind when the patient, investigators and outcome assessors are unaware of a patient’s assigned treatment throughout the duration of the trial. Blinding helps eliminate biases other than selection bias, such as differences in the care provided to the two groups, withdrawals from the trial and how the outcome is assessed and analysed. In some cases, double blinding cannot be implemented and a single blind design may be used.
There are numerous reasons suggested as to why phytotherapy should be subjected to the same degree of scientific scrutiny as conventional medicine. Such reasons include the need to become accepted by governments and conventional medicine, to help us determine if the therapy is safe and effective and to give patients a reasonable idea of the potential success rate.1,2,3
This is not to say RCTs are without criticism. There are circumstances in which such a trial would be unethical. RCTs do not address why a treatment works, how participants are experiencing the treatment and/or how they give meaning to these experiences. They may not illustrate benefits other than the specific effects measured, explain the effects of the patient-practitioner relationship or take into consideration the patients’ beliefs and expectations. Statistically significant results may be produced that have no clinical significance or importance to patients or their caregivers. Outcome measures may focus on the physical while ignoring issues related to meaning, purpose and spirituality (for example, quality of life measures in terminally ill patients). This is also not to say that RCTs are the ‘only game in town’. Epidemiological and social research methods with appropriate designs also provide valuable information.1,2,4–7
Despite its gold standard status, there is also no guarantee that a RCT will be well conducted, or will produce meaningful results (see later) and often once published results are open to distortion and misinterpretation.8
CAM versus conventional medicine in the published literature
Before looking at the structure of clinical trials and how they should be read, it is worth examining the published literature in perspective: what can be said about the quality of information that is published and is there a difference between how complementary and alternative medicine (CAM) is handled compared with conventional/orthodox/mainstream medicine?
An analysis of 207 randomised trials found that trials of complementary therapies often have relevant methodological weaknesses. Reporting and handling of drop-outs and withdrawals was a major problem in all therapies reviewed. (The data analysed here was originally collected for previously published systematic reviews on homeopathy (published 1997), herbal medicine (St John’s wort for depression (1998), Echinacea for common cold (1999), acupuncture (for asthma (1996) and recurrent headaches (1999).) Larger trials published more recently in journals listed in Medline and in English exhibited better methodological quality, but stringent quality restrictions would result in the exclusion of a majority of trials. However, the average methodological quality of the complementary medicine trials reviewed was not necessarily worse than trials in conventional medicine.9 (It would be interesting to have this analysis repeated using more recent systematic reviews containing more rigorous trials of herbal medicines such as for Ginkgo and St John’s wort.)
A randomised, controlled, double blind study investigated the hypothesis that the process of peer review favours an orthodox form of treatment over an unconventional therapy. A short report describing a randomised, placebo-controlled trial of appetite suppressants (‘orthodox’=hydroxycitrate, ‘alternative’=homeopathic sulphur) was randomly sent to 398 reviewers. Reviewers showed a wide range of responses to both versions of the paper, with a significant bias in favour of the orthodox version. Authors of technically good unconventional papers may therefore be at a disadvantage when subject to the peer review process. However, the effect is probably too small to preclude publication of their work in peer-reviewed orthodox journals.10
Publication bias is a recognised phenomenon in mainstream medicine (MM), so does it exist in complementary and alternative medicine (CAM)? An analysis of controlled trials of CAM found that more positive outcome trials than negative outcome trials are published. (The analysis looked at journals aimed specifically at a CAM readership and journals that specialised primarily in mainstream medical topics.) The only exception to this was in the highest impact factor MM-journals (this means that the publication bias in favour of a positive outcome for CAM clinical trials did not occur in those mainstream medicine journals with the highest citation rate). In non-impact factor CAM-journals, positive studies were of poorer methodological quality than the corresponding negative studies. (CAM therapies in this investigation included herbal medicine, homeopathy, chiropractic, osteopathy, spinal manipulation and acupuncture. The analysis used systematic reviews and meta-analyses from 1990 to October 1997.) Considerable bias may also be caused by using Medline as a single source of information, although this is not unique to CAM (an investigation of mainstream medicine publications found that European journals may be underrepresented in Medline).11 An investigation of trials published in four prominent Medline-indexed CAM journals from 1995 to 2000 found that the bias towards the publication of a positive outcome persisted in 2000, although it was less strong than in 1995.12
What to look for when reading a clinical trial paper
A trial often seeks to question, rather than confirm, its own hypothesis. The authors of a study set out to demonstrate a difference between the two arms of their study (e.g. a herbal medicine compared with placebo, herbal medicine compared with a drug or a comparison of two different dosages of herb) and do it in the following way ‘Let’s assume there’s no difference; now let’s try to disprove that theory’.13 This is why the results are presented as ‘there was/was not a statistically significant difference between [the herb] and placebo’.
The standard (and best) presentation for papers published in medical journals includes:14
• Introduction (why the authors decided to do this particular piece of research)
• Methods (how they did it and how they chose to analyse their results)
The design of the methods section is important in estimating the quality of the trial. Having worked through the methods section, you should be able to tell yourself:14,15
• What sort of study was performed
• Where the participants came from
When scanning clinical trials (abstracts and full papers!) it is best to start with the conclusion section: was the outcome positive or negative? What herb was trialled? Then go to the method: what objective parameter was measured? What was the form and dosage of the herb? In the methods section it really helps when it is spelled out as ‘the aim of this randomised study was to [assess the effectiveness of …], the secondary objectives were to assess …’.
Some characteristics of poorly conducted/written clinical trials:
• Abstract/summary not clearly written, conclusion not easy to find
• Who received what and when; was there a washout period (crossover trials) and when did it occur? Was there a follow-up and when did it occur?
 Not clearly outlined; e.g. dried herb equivalent not outlined – only the extract or concentrate or active constituent dosage given; ‘patients received one capsule of the plant extract’ Placebo not clearly outlined or inappropriate:
Not clearly outlined; e.g. dried herb equivalent not outlined – only the extract or concentrate or active constituent dosage given; ‘patients received one capsule of the plant extract’ Placebo not clearly outlined or inappropriate:
 misleading information, e.g. ‘ginger extract is a preparation (250 mg of Zingiberis Rhizoma per capsule)’ when further investigation of the product (e.g. via company/product website) indicates ‘capsules contain 250 mg of a concentrated pure ginger material’
misleading information, e.g. ‘ginger extract is a preparation (250 mg of Zingiberis Rhizoma per capsule)’ when further investigation of the product (e.g. via company/product website) indicates ‘capsules contain 250 mg of a concentrated pure ginger material’ Duration of treatment not specified
Raw data presented but not summarised or the numbers do not add up (e.g. numbers conflicting between results and discussion/conclusion sections)Checklist for reading RCTs
The following points illustrate the type of questions to ask from a clinical trial paper. Examples are outlined below.
(a) What clinical question did the study address?
(b) Was the study conducted with patients with pre-existing disease or healthy volunteers?
(c) Were the participants studied in the trial relevant to your practice?
(d) What treatment was considered?
(e) What parameters were measured and what is the clinical relevance?
(The best quality papers outline why that parameter is relevant, so you do not have to go searching to understand the connection).
In a clinical trial assessing the efficacy of a standardised willow bark extract, the primary outcome measure was the pain dimension of the WOMAC Osteoarthritis Index, a reduction in this score indicates an analgesic effect. It would be useful to compare the reduction observed from willow bark (14%) with that obtained from a standard drug (diclofenac, 19%).
‘Softer’ outcome measures include patient and physician assessments, although it is better if this information is also objectively evaluated.
Here are some examples where the measured parameter may not be clinically relevant:
only measuring serum PSA (prostate-specific antigen) in a trial investigating saw palmetto liposterolic extract for benign prostatic hyperplasia would not be as useful as measuring urinary symptoms, pain and quality of life in HIV, CD4 count alone has been found not to correlate with survival – a combination of several markers gives a better indication.16 measurement of biological markers (TNF alpha and IL-1beta) in patients treated with saw palmetto liposterolic extract to test the hypothesis that infiltrating cells are associated with progression of benign prostatic hyperplasia after 6 months of saw palmetto treatment a difference occurred in nuclear morphometric descriptors, suggesting the herbal blend alters the DNA chromatin structure and organisation in prostate epithelial cells→a possible molecular basis for tissue changes and therapeutic effect of the compound is suggested serum of women given phyto-oestrogens to ingest stimulated prostacyclin release in human endothelial cells (ex vivo)→phyto-oestrogens might produce a beneficial cardiovascular effect in vivo gene expression within peripheral leukocytes evaluated in healthy nonsmoking subjects who consumed Echinacea→pattern showing an anti-inflammatory and antiviral response Panax ginseng, at doses of 200 mg of the extract daily, increases the QTc interval (an electrocardiographic (ECG) parameter, not immediately clinically significant) and decreases diastolic blood pressure 2 h after ingestion in healthy adults on the first day of therapy→increases in ECG parameters may have clinical implications as they increase the risk of ventricular tachyarrhythmias. high-dose treatment with St John’s wort extract induced CYP3A activity in healthy volunteers as evidenced by increased 6-beta-hydroxycortisol excretion. Induction of this enzyme most likely contributes to the decreased bioavailability observed upon co-administration of various drugs with St John’s wort extract. The D-glucuronic acid pathway appeared unaffected by St John’s wort. (Note: Although this trial did not tell us anything immediately clinically relevant, some trials investigating cytochrome P450 enzymes are relevant, such as those that demonstrate an interaction between St John’s wort and specific drugs such as omeprazole, irinotecan, verapamil). oral treatment with a Ginkgo biloba extract (Gibidyl Forte(R)) dilated forearm blood vessels causing increments in regional blood flow without changing blood pressure levels in healthy participants→the increments in blood flow may be used as a biological signal for pharmacokinetic studies.(f) Was the route of administration relevant to herbal practice?
(g) Was the preparation relevant to the products you use?
(h) Was the dosage relevant to herbal practice?
Note: A clinical trial does not necessarily determine the optimum dose, but provides information that for a given dose of a given herbal preparation a certain percentage of patients will be likely to respond i.e. [herbal preparation] at xx mg/day given for a period of yy weeks improved [the disease/disorder] in ZZ% of patients.
(i) Was the choice of placebo suitable?
(j) Was the blinding successful?
A well-designed trial will report the methods used to produce the double blinding. An analysis of the methodological quality of controlled trials published in 1995 found that trials for which no double blinding was reported produced larger estimates of effects.17 It is not enough for the trial to describe itself as double blind, the success of the blinding should be evaluated and reported. (One way would be to ask the patients and clinicians at the end of trial which treatment they thought they had received.) Evaluation of blinding is rarely done in trials of conventional medicine (a recent analysis found only 7% for general medicine trials)18 let alone in CAM trials. The evaluation of blinding has also been questioned. Trial participants asked to guess their treatment might be influenced by outcome (e.g. marked therapeutic or adverse effects). Assessments of blinding success would be more reliable if carried out before the clinical outcome has been determined. But in the case of a comparative treatment (no placebo) clinicians’ predictions may be a measure of pre-trial hunches and inseparable from the blinding effectiveness.19,20
An example of evaluation of blinding in a randomised, comparative trial between St John’s wort (Hypericum perforatum) and sertraline for major depressive disorder is outlined below.21
At the end of 8 weeks, the proportion of patients guessing their treatment correctly was 55% for sertraline, 29% for Hypericum, and 31% for placebo (p=0.02 for differences between treatment groups). Correct guesses for clinicians totalled 66% for sertraline, 29% for Hypericum, and 36% for placebo (p=0.001 for differences between treatment groups). The change (mean) in HAM-D total score from baseline to week 8 did not differ for patients who were in the sertraline group and either had guessed the correct treatment (−11.6; 95% CI, −13.1 to −10.1) or had not (−11.9; 95% CI, −13.9 to −9.9).
This assessment was criticised, with the conclusion that the blinding was compromised. Clinicians who believed in the strength of sertraline treatment may have inadvertently let this bias affect their ratings. HAM-D is regarded as a clinician-rated measure (it would have been better to measure this against the clinician’s guesses rather than the patient’s guesses) – better yet, assess the other score (CGI-I, Clinical Global Impressions) which is a better measure of treatment effect).22,23
(k) Was the treatment beneficial?
This will be a comparison of the results of the two groups, but most well-designed clinical trials now also report the difference between the two treatments using statistics, which is often expressed with a p value. The p value is the probability that any particular outcome would have arisen by chance. Standard practice usually regards a p value less than one in twenty (expressed as p<0.05) as ‘statistically significant’ and a p value less than one in 100 (p<0.01) as ‘statistically highly significant’, and p<0.001 more highly significant again. So if you read 20 clinical papers that reported a significant outcome of p<0.05 then it is likely that the outcome for one trial was not significant but due to chance:24
(A cautionary note about statistics. A recent analysis found that statistical errors occurred in two leading scientific and medical journals. In 12% of cases, the significance level could have changed by one or more orders of magnitude. The conclusion would change from significant to nonsignificant in about 4% of the errors.25)
(l) What was the side effect rate, side effect severity and drop-out rate?
More information
The above checklist helps the reader to obtain information from the clinical trial paper, but critical appraisal (such as assessing the scientific validity and practical relevance) of the trial involves a whole lot more and is beyond the scope of this discussion. More information on critical appraisal can be found from well written books devoted to the topic,26,27 and some examples include:
• did the study enrol too few patients?
• were the trial participants representative of all those with the disease or all those for whom the therapy is intended?
• was the treatment duration too short or the follow up period too long?
• have confounding variables been eliminated?
• did the efficacy result from the treatment or from another factor?
• was the drop-out rate too high?
• what do the statistics really tell you? A p value in the non-significant range tells you that either there is no difference between the groups or there were too few participants to demonstrate the difference if it existed.
Published research of other designs have not been discussed here (e.g. controlled (nonrandomised) trials, postmarketing surveillance trials, uncontrolled trials, cohort and case-controlled trials, surveys, case reports, pharmacokinetic studies and herb-drug interactions) but many of the same principles apply. A higher level of rigour (and regarded as a higher level of evidence) can be found in systematic reviews and meta-analyses. (A systematic review summarises the available evidence on a specific clinical question with attention to methodological quality. A meta-analysis is a quantitative systematic review involving the application of statistics to the numerical results of several trials which all addressed the same question.) Systematic reviews and meta-analyses are useful in that they summarise the available clinical trial results. Meta-analyses are particularly valuable because by pooling the trial results they provide greater statistical power to measure a difference between the treatment and the control group.28 Narrative (nonsystematic) reviews, as employed for the monographs in this book, may provide a useful overview of the literature but do not employ the same rigour as systematic reviews (they are not standardised or as objective). But even these more rigorous studies (systematic reviews and meta-analyses) are not beyond criticism and subjectivity.29
Clinical trial papers: how to calculate dosage
Extraction or concentration ratio
The strength of a herbal liquid preparation is usually expressed as a ratio.
Example:
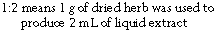
For solid dose preparations, the concentration ratio is the ratio of the starting herbal raw material to the resultant finished concentrated extract (also known as a concentrate or dry extract or native extract). The finished extract is always expressed as 1 and comes second.
Example:

| 1:1 liquid extract | 1 g dried herb produced 1 mL of 1:1 liquid extract |
| 1:2 liquid extract | 1 g dried herb produced 2 mL of 1:2 liquid extract |
| 1:3 tincture | 1 g dried herb produced 3 mL of 1:3 tincture |
| 1:5 tincture | 1 g dried herb produced 5 mL of 1:5 tincture |
| 2:1 concentrated extract | 2 g dried herb produced 1 g of 2:1 concentrated extract also written as: |
| 1 g of 2:1 concentrated extract was produced from 2 g dried herb |
Note: These ratios apply to extracts made from dried herb (not fresh herb).
Converting back to the dried herb (known as ‘dried herb equivalent’) is a useful way for comparing doses between different strengths of herbal liquids or between liquids and tablets.
Note: This conversion is commonly done when reviewing clinical papers for example, or comparing herbal products, but does not apply to standard texts such as the British Herbal Pharmacopoeia (BHP) 1983. The reason for the latter inconsistency relates to how the information was gathered (a survey of dosage recommendations by those practising at the time, and the reproduction of earlier pharmacopoeial information). For more information, refer to Chapter 6 or A Clinical Guide to Blending Liquid Herbs (pages 20 to 22).30 This discrepancy in the BHP, however, does not negate the validity of using the dried herb equivalent.
Often there is insufficient information provided to accurately determine the dose of herb evaluated in a trial. Many trial authors seem to think that a trade name is sufficient for defining a product (despite the fact that unlike drugs, information about the content of the herbal products is not always readily available). In response to a question, one author said he could not define the product (even by name), as he had merely requested the herb from the hospital pharmacy.
Worse still, authors may not even indicate that a concentrated extract was administered, with readers assuming the dosage to be equivalent to dried herb. A clinical trial published in JAMA (Journal of the American Medical Association) 2002 indicated in the abstract that ‘the daily dose of H. perforatum could range from 900 to 1500 mg’, implying a dried herb dosage. The Methods section indicated ‘Hypericum and matching placebo were provided by Lichtwer Pharma (Berlin) … The Lichtwer extract (LI-160) was selected … ‘. The extract was standardised to between 0.12% and 0.28% hypericin, but unfortunately for readers the concentration ratio was not defined. Given it was the Lichtwer extract, this is likely to have a concentration ratio of 6:1. So the 900 to 1500 mg daily dose range referred to above probably translates to the equivalent of 5.4 to 9 g of dried herb. Products often change over time also, so the concentration ratio of a particular product needs to be determined at the time it was evaluated.
It is best to assume that clinical trials are evaluating concentrated extracts and look for the product definition (most often in the Methods section if not in the abstract) before considering how to use the information in the clinic.
Rules to consider before calculating dosage
When working out extraction and concentration factors, first consider the dosage form (starting with dried herb, liquid extract or concentrated extract).
If the amount of concentrated extract is known, first work out the dried herb equivalent and then calculate a relevant liquid extract or tablet dosage. Multiply the weight of concentrate by the first number in the ratio:
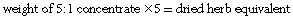
Once the dried herb equivalent is known this can be converted to a liquid extract by multiplying by the second number of the ratio:
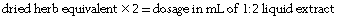
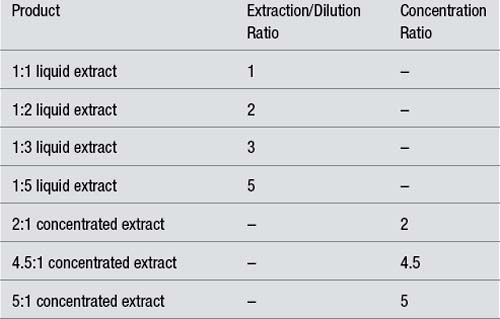
Examples:
| Product | Extraction/Dilution Ratio | Concentration Ratio |
|---|---|---|
| 1:1 liquid extract | 1 | – |
| 1:2 liquid extract | 2 | – |
| 1:3 liquid extract | 3 | – |
| 1:5 liquid extract | 5 | – |
| 2:1 concentrated extract | – | 2 |
| 4.5:1 concentrated extract | – | 4.5 |
| 5:1 concentrated extract | – | 5 |
The table below illustrates how to calculate doses cited in clinical trials and convert them to products, such as standardised liquid extracts and tablets. The first column contains a statement from the methods section of the cited clinical trial and the subsequent columns show how to convert the dosage first to the dried herb equivalent (or active constituent level) and then to liquid extract or tablet dosages where relevant. Notes explaining the calculations are provided in italics.
References
1. Levin JS, Glass TA, Kushi LH, et al. Med Care. 1997;35(11):1079–1094.
2. Verhoef MJ, Casebeer AL, Hilsden RJ. J Altern Complement Med. 2002;8(3):275–281.
3. Harlan WR, Jr. J Altern Complement Med. 2001;7(suppl 1):S45–S52.
4. Cohen SR, Mount BM. J Palliat Care. 1992;8(3):40–45.
5. Jonas WB, Goertz C, Ives J, et al. JAMA. 2004;291(18):2192.
6. Herman J. J Clin Epidemiol. 1995;48(7):985–988.
7. Riegelman RK, Hirsch RP. Studying a Study and Testing a Test: How to Read the Health Science Literature, 3rd ed. Boston: Little Brown, 1996. p. 73
8. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. p. 48
9. Linde K, Jonas WB, Melchart D, et al. Int J Epidemiol. 2001;30(3):526–531.
10. Resch KI, Ernst E, Garrow J. J R Soc Med. 2000;93(4):164–167.
11. Pittler MH, Abbot NC, Harkness EF, et al. J Clin Epidemiol. 2000;53:485–489.
12. Schmidt K, Pittler MH, Ernst E. Swiss Med Wkly. 2001;131(39–40):588–591.
13. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. pp. 42, 47
14. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. p. 39
15. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. p. 73
16. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. p. 100
17. Schulz KF, Chalmers I, Hayes RJ, et al. JAMA. 1995;273(5):408–412.
18. Fergusson D, Glass KC, Waring D, et al. BMJ. 2004;328(7437):432.
19. Altman DG, Schulz KF, Moher D. BMJ. 2004;328(7448):1135.
20. Sackett DL. BMJ. 2004;328(7448):1136.
21. Hypericum Depression Trial Study Group. JAMA. 2002;287(14):1807–1814.
22. Jonas W. JAMA. 2002;288(4):446.
23. Spielmans GI. JAMA. 2002;288(4):446–447.
24. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. p. 87
25. Garcia–Berthou E, Alcaraz C. BMC Med Res Methodol. 2004;4(1):13.
26. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001.
27. Riegelman RK, Hirsch RP. Studying a Study and Testing a Test: How to Read the Health Science Literature, 3rd ed. Boston: Little Brown, 1996.
28. Greenhalgh T. How to Read a Paper. London: BMJ Books, 2001. pp. 120–122, 128–133
29. Teagarden JR. Pharmacotherapy. 1989;9(5):274–281.
30. Bone K. A Clinical Guide to Blending Liquid Herbs: Herbal Formulations for the Individual Patient. In St. Louis. Churchill Livingstone; 2003. pp. 20–22
31. Anderson JW, Davidson MH, Blonde L, et al. Am J Clin Nutr. 2000;71(6):1433–1438.
32. Walker AF, Middleton RW, Petrowicz O. Phytother Res. 2001;15(1):58–61.
33. Schmid B, Ludtke R, Selbmann HK, et al. Phytother Res. 2001;15(4):344–350.
34. Zapfe G, Jr. Phytomedicine. 2001;8(4):266–272.
35. Javidnia K, Dastgheib L, Mohammadi Samani S, et al. Phytomedicine. 2003;10(6–7):455–458.