14 Assessing learners
Assessment See main Glossary, p 339.
Assessment; formative See main Glossary, p 337.
Competency See main Glossary, p 340.
Context specificity Commonly defined by the observation that an individual’s performance on a particular problem or in a particular situation is only weakly predictive of the same individual’s performance on a different problem or in a different situation.
Educational impact The effect of assessments on learning.
Evaluation See main Glossary, p 340.
Reliability See main Glossary, p 342.
Summative assessment See main Glossary, p 343.
Triangulate Comparing and integrating observations made using different assessment methodologies to form an overall judgement of competency.
Utility of an assessment method A conceptual design model using multiplicative, differentially weighted functions of five variables (educational impact, validity, reliability, acceptability, and cost) to define the utility of an assessment method, or a programme of assessment, in a given situation.
Validity See main Glossary, p 343.
Outline
This chapter first explores theoretical frameworks and concepts underpinning our understanding of assessing learners in medicine. The rationale for the current philosophy, which moves clinical competency assessment away from examinations alone towards a more developmental formative approach to assessment, is explained. The principles needed to understand test design are then reviewed to provide a framework for the development of assessment programmes. The range of available assessment tools and the evidence base for their use is subsequently discussed. Basic psychometric principles essential to the evaluation and quality assurance of the assessment process are outlined. The chapter concludes with a look to the future.
A fundamental truth
Assessment drives learning. As educationalists, we may be uncomfortable with this statement. The curriculum learning outcomes and teaching delivery should be decided before the appropriate assessment methods are selected. Yet, we face a reality. What influences any student most is not the teaching but the assessment. The dominant impact of assessment has long been recognised. Derek Rowntree stated, ‘If we wish to discover the truth about an educational system we must first look to its assessment procedures’ (Rowntree, 1987). That does not negate the content of other chapters in this book. Assessment must mirror the philosophy and learning intent of the curriculum. The importance of harnessing assessment design to achieve appropriate learning cannot be too strongly emphasised. All assessments must have intrinsic educational impact on learners and teachers.
The challenge of assessing learners in medicine: important theoretical concepts
It is important to understand how to maximise the educational influence of assessment. Views on how to measure the competency of health professionals are changing in an attempt to do this. The increasing acknowledgement that assessment is integral to learning, and not a process that happens at the conclusion of learning, creates potentially conflicting issues for the health professions. We highlight four: (i) balancing competence with aspiration to excellence, (ii) recognition of the learner’s rate of progression from novice to expert, (iii) the balance between formative and summative agendas, and (iv) difficulties in weighing reliability and validity within clinical assessment methodology.
Competence versus excellence
Competency-based curricula are increasingly being introduced in medical education, as outlined in Chapter 6, and there is an increased focus on technical qualifications. Some believe that this approach undermines medical professionalism and fails to provide the appropriate learning platform for continuing professional development. Instead, it fosters a ‘tick box’, ‘can do’ mentality. Trainees perceive that they have achieved competence when they pass an assessment and do not recognise that they need to improve their skills further through apprenticeship and practice. The aim to ‘do better’ may be lost. The United Kingdom Royal College of Physician’s (RCPs) report (RCP, 2005) reviewing the challenges to the medical profession in the twenty-first century emphasised the need to aspire continually to excellence. It raised serious concerns that current assessment trends towards competency were failing us. Even more seriously, there is a risk of generating ‘incompetency’ if learners perceive prematurely that they have achieved ‘competency’. They can fail to recognise that the judgement of competency pertains only to a point in time. The need to set goals for further development is lost (Hodges, 2006). That tension has to be acknowledged as you read through the content of this chapter.
To achieve a new developmental culture and move away from end point examinations and final competency assessments, we need to bring assessment more into the centre of the learning process (Shepard, 2000), as argued above. That would concur with Vygotsky’s (1978) concept of a ‘zone of proximal development’. Each learner is on a progressive, developmental pathway of expertise. At a particular moment in time, with a mentor’s guidance, they need to understand not only what they are capable of performing independently but also how they can improve. Continually resetting their goals can foster an aspiration to do better. This requires a change in assessment culture for both students and tutors. In a competitive assessment world, high scores are of paramount importance; in a more developmental world, which encourages educational feedback, students will not necessarily score high. In the current culture, they can be uncomfortable with low scores. Tutors who are used to linking judgements with a numerical grade that can be defended will have to review their approach to assessment. Emerging evidence shows many tutors have difficulty giving constructive feedback rather than assigning a score or ticking off a competency. A fundamental change in practice is needed, which requires time and training resources.
There is increasing recognition, according to Lave and Wenger’s theory (1991), that learning and the development of an identity of mastery occur simultaneously as students become increasingly adept at participating in a community of practice. If we are to understand why some students struggle to achieve competence and how to motivate others towards goals of excellence, then attention should be paid to the concept of legitimate peripheral participation. More theoretical understanding is needed of how students socialise into and communicate within a community of practice and how they develop competence as part of a social group. This almost certainly impacts on how they develop the institutional socially acceptable language, become accustomed to explaining their reasoning, and receive the feedback necessary to move across competency towards excellence. Herein may also lie an explanation of differences seen in performance across gender and ethnicity (Wass et al, 2003a).
Novice to expert
Clinical competence is a complex construct. We define competency as ‘the ability to handle a complex professional task by integrating the relevant cognitive, psychomotor, and affective skills’. Inevitably, by the very nature of these three components, ‘knowledge, skills, and attitudes’, multiple assessment methods must be used. The resulting observations can then be compared and integrated to create an overall picture of an individual’s competence: a process termed ‘triangulation’. This is not that easy, particularly if assessment is set in the context of continuous professional development, as discussed above.
Vygotsky’s concept of a zone of proximal development highlights the importance of interactive assessments to explore where the student is placed in their progression from novice to expert. The pathway of learning diagnostic reasoning is, to a significant extent, dependent on expertise resultant on clinical experience. The move from a novice to an expert involves a complex cognitive process (Schmidt and Norman, 2007). The rather laborious data gathering process, on which hypothetico-deductive diagnostic reasoning is initially built, changes with time. A shift in the structuring of knowledge is intrinsic to the growth of expertise. For novices, a clinical case appears as a series of isolated symptoms and signs, which must be related to finite pathophysiological concepts. Similarly, a skill is learnt as a stepwise series of distinct procedural steps. Knowledge then becomes progressively assimilated into diagnostic labels, a process termed ‘encapsulation’. As more clinical experience is gained, a further shift occurs as patterns of disease recognition, called ‘illness scripts’, develop. These are more narrative than factual, derive from everyday clinical practice, and almost completely ‘bypass’ the original building stones with which a novice works. They are cognitive entities containing relatively little basic knowledge and scaffolded from direct patient encounters, a product of growing clinical experience. Not surprisingly, ‘illness scripts’ can be very individual as clinical experience is so varied. If, for example, you have witnessed a significant thromboembolic episode in a young girl on the contraceptive pill, then pattern recognition when dealing with patients with headaches taking the pill will weigh towards more serious causes than for clinicians who have not. Similarly when learning skills, practice is essential to allow the initial rather pedantic stepwise checklist of tasks to become automatic and integrated.
A learner’s position on the novice to expert pathway affects both their performance and the judgements of those assessing them. A medical student just starting clinical placements will be in the first stage of diagnostic reasoning, using a checklist of items to gather data, examine a patient, or demonstrate a skill. An experienced assessor will have developed a global, integrated approach and have difficulty reverting to explicit analysis of inexpert performance. As Eraut (2004) points out: ‘expert performance is often tacit; identifying aspects of different disciplinary practices is in itself a significant task’. A useful model in understanding the novice to expert pathway, which provides a framework for assessing across the undergraduate postgraduate continuum, is that of Dreyfus and Dreyfus (1986). Table 14.1 outlines the stages and implications for testing as knowledge and skills move from basic knowledge, where there is little situational perception and situational judgement, through to the holistic, intuitive approach of experts. This ‘mismatch’ between reasoning processes of a novice and those of an expert explains some of the dilemmas faced when assessing learners in medicine.
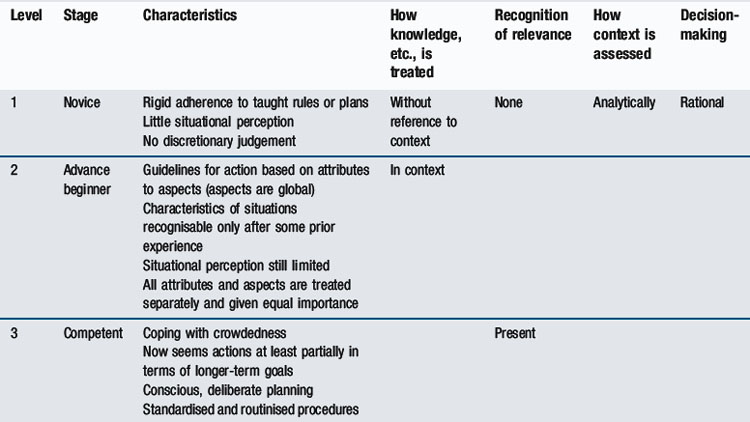

Assessment methods must be tailored to accommodate shifts in reasoning which develop implicitly with experience. Although medical students and residents are among the most frequently tested groups in higher education, it is surprising how often the assessment methods still focus primarily on low-level skills. If we expect our future clinicians to be excellent, we must begin to test across the education continuum at increasingly higher skill levels or, indeed, use assessment to drive its development. It is important both to identify a trainee’s position on the novice to expert pathway and encourage a higher level of reasoning.
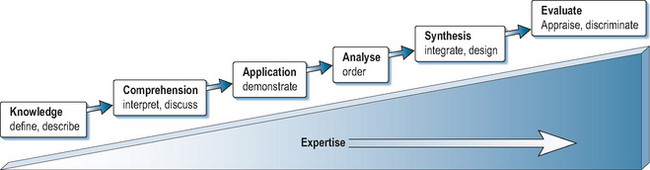
Bloom’s taxonomy of knowledge (Figure 14.1) provides a means of illustrating why this is important. Bloom (1965) defines increasing levels of complexity; initially defining basic facts, then applying these to clinical situations, before progressing towards analysis, and finally evaluating clinical events. It is relatively easy to test basic factual knowledge; it is not uncommon to find postgraduate examinations still assessing at this level. Yet, even at undergraduate level, novices need encouragement to ‘interpret’ basic facts in a clinical context and apply them to simple clinical scenarios. Assessment should be designed at increasingly higher levels of the taxonomy towards ‘synthesis’ and ‘evaluation’. In the postgraduate arena, audit and critical appraisal become more appropriate assessment tools. Designing assessments to achieve this can be challenging. It is essential to ask the question repeatedly: ‘Is this assessment appropriate to the cognitive level of the trainee as they progress towards clinical expertise?’
Summative versus formative
There are conflicting commitments within medical curricula. Throughout undergraduate and postgraduate ‘training’, there is a strong obligation on the part of institutions to ensure that their learners become ‘safe’ to practise in health care. There is an absolute necessity to protect patients. Minimum levels of competency for progression in training are required. This summative approach is potentially threatening and, as we have discussed, may be counter-productive in supporting learners’ progression from novice to expert. Some are concerned that ‘licensing tests’ can impact negatively on learning because they detract from the safe educational environments we strive to create. Examinations drive learning too narrowly towards the licensing test. Training towards minimum competency can conflict with the overriding commitment to education and lifelong learning. The latter requires a more ‘formative’ approach to assessment, with regular constructive feedback to trainees to ensure that they set personal goals for improvement.
The focus in the past has been very much on serial examinations and the summative assessment of learners. The need for a social constructivist approach to the assessment of clinicians is increasingly acknowledged (Rust et al, 2005). This view argues that knowledge evolves and is shaped through increasing participation within communities of practice (Lave and Wenger, 1991). Assessment needs to be constructively aligned with the environment in which trainees learn, that is, the apprenticeship foundation of medicine. We face a compelling need to change to a formative approach and foster continuous professional development in workplaces. There has been a strong initiative to replace summative examinations with more formative assessment programmes, which reflect the socio-cultural milieu of the curriculum (van der Vleuten and Schuwirth, 2005). The socio-cultural approach creates a further tension for tutors within the pressures of their working day. Tutors are being asked to collaborate formatively with trainees and give regular feedback on performance. At the same time, they may be asked to make summative judgements on the trainee’s competence to practise. These roles entail very different power relations, which can be difficult to enact side by side, a dilemma that cannot be ignored.
There have been two significant consequences of this increasing move towards formative assessment. First, in an attempt to acknowledge assessment as developmental, confusion has evolved in the assessment discourse. Appraisal (see Chapter 13), essentially a confidential process focused on personal professional development, is increasingly seen as a potential vehicle for summative assessment. This is potentially damaging, threatening the educational potential of a feedback culture across the medical education continuum. The fundamental principle of supporting learning through feedback is in the systematic, supportive manner in which it is facilitated (Jamtvedt et al, 2003). Introducing a summative element threatens this. Learners can be confused by a language that uses appraisal outcomes, understood as confidential, to inform assessment processes such as revalidation. Whereas assessment can usefully inform appraisal, we believe appraisal cannot realistically inform assessment, by the very nature of its confidentiality. A second consequence is the use of ‘formative’ and ‘summative’ as dichotomous terms. Formative assessment risks are aimed only at the generation of educational feedback to support and develop learners, with little emphasis on psychometric principles. Psychometric preoccupation with reliability is viewed as the preserve of summative assessment – ensuring that pass/fail decisions are robust. As a result, feedback on performance is rarely given after summative assessment beyond a pass/fail decision. Continuing to view formative and summative assessment as separate processes is not progressive. Learners, whether they pass or fail, are entitled to expect detailed feedback on their performance. We argue that all assessments must be able to demonstrate reliable psychometric properties, whatever their purpose, so more attention must be paid to the development of psychometrically robust formative tools. If the main aim is to provide feedback, then the information given must be both valid and reliable. Research is urgently needed to address this cultural change as we move away from the formative–summative dichotomy.
Validity and reliability
The fourth challenge lies in addressing tensions that exist when ensuring that an assessment is both valid and reliable. There are trade-offs between reliability and validity, which inevitably impact on developing more formative assessment programmes. It is important to explore theoretical understanding of these two concepts and how they relate to each other. Intrinsically, by the very nature of assessment, a test cannot be valid unless it is reliable. Yet, without validity, the purpose and value we place on the educational impact of assessment would have little meaning.
Validity
Validity is defined as ‘the strength of conclusions and inferences which can be drawn from the outcomes of an assessment’; that is, ‘Has the test effectively measured what it was intended to measure?’ All assessments require evidence of validity. It is a conceptual term though, based on hypothesis. Its interpretation can be potentially confusing for two reasons. First, validity can only be evaluated retrospectively once performance data on a test have been collected. It cannot be measured at the planning stage, a common misconception. For example, an objective structured clinical examination (OSCE) station on the physical examination of a real patient’s varicose veins may be designed and perceived as a valid test of a skill. If, on the day, the patient cancels and an adult with normal legs is substituted, the station has inadvertently lost its validity. Various pieces of information on a test can only be collated and analysed when the assessment has been completed. Whether the original intentions (as hypothesised) have been met or not must be decided after a test. Moreover, any conclusions are only applicable to that particular test in that specific cohort of learners.
Second, a series of facets were identified (Table 14.2) against which the validity of a test could traditionally be assessed. That rather pragmatist view of validity is now changing. According to a more contemporary conceptualisation, one unitary concept, ‘construct validity’, is offered (Downing, 2003b). The single term embraces all the multiple sources of evidence needed to evaluate and interpret the outcomes of an assessment. This approach was originally conceptualised by Messick (1989). It enables us to move away from the traditional individual descriptive ‘facets’ outlined in more detail below and focus more on sources of evidence available to validate assessment processes. This approach will be outlined in more detail later in the chapter.
Table 14.2 Traditional facets of validity
| Type of validity | Test facet being measured | Questions being asked |
|---|---|---|
| Face validity | Compatibility with the curriculum’s educational philosophy | What is the test’s face value? |
| Does it match up with the educational intentions? | ||
| Content validity | The content of the curriculum | Does the test include a representative sample of the subject matter? |
| Construct validity | The ability to differentiate between groups with known difference in ability (beginners versus experts) | Does the test differentiate at the level of ability expected of candidates at that stage in training? |
| Predictive validity | The ability to predict an outcome in the future: for example, professional success after graduation | Does the test predict future performance and level of competency? |
| Consequential validity | The educational consequence of the test | Does the test produce the desired educational outcome? |
Reliability
Reliability is, by comparison, a more ‘concrete’ parameter. It can be measured quantitatively, as described later in the chapter. It can be defined as the reproducibility of assessment data or scores, over time or occasions (Downing, 2004). Although usually distinguished from validity, reliability is a pre-condition for validity. If an assessment is not sufficiently reliable, then the evidence required to establish validity becomes inaccurate. Reliability is usually (and correctly) said to be a necessary but not ‘sufficient’ condition for validity. Measurements or judgements may be reliable in the sense of being consistent over time or over judges but still be off-target (or invalid) if they have not actually measured what you set out to measure. Reliability and validity are, in a sense, intertwined and need to be balanced against each other, along with other parameters discussed above (Figure 14.2).
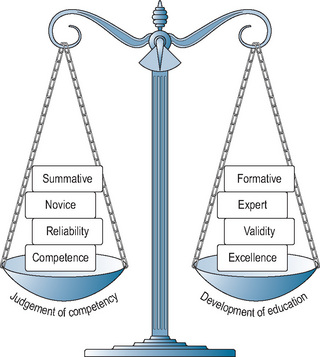
The traditional, artificial separation of validity and reliability fuels the formative versus summative debate. Where educational supervision and feedback are of paramount importance, as in formative assessment, attention to the validity of judgements made by tutors and the constructive potential of their feedback takes precedence. Yet, this must not be entirely to the exclusion of reliability. The emphasis on improvement must be based on robust as well as valid feedback. If a decision-making function is also placed on the process, then the defensibility required of the judgements places greater weight on reliability. Little is known to date on how assessments can be combined (if indeed they can) to balance validity with reliability. The importance of trying to achieve a greater understanding of this might well emerge as we move away from the defensibility of examinations to explore more developmental assessment programmes in workplaces.
These theoretical concepts (Figure 14.2) should be kept in mind as the chapter proceeds to outline the fundamentals of assessment design. There is no gold standard for the assessment of any facet of clinical competence. At best, robust frameworks balance the formative approach needed to inform self-monitoring with the stringent judgements required to assure that trainees are competent for safe clinical practice. Increasingly, programmes must be designed to offer more flexibility, more formative feedback, and longitudinal assessment. Testing must adapt to levels of expertise and involve all stakeholders in setting standards and quality assurance.
The principles of designing assessments
This chapter opened by stating the fundamental, if uncomfortable, truth that assessment drives learning and must mirror the philosophy and learning intent of a curriculum. This truth is often lost as assessment methodology is driven by convenience, cost, or the latest fad. To avoid losing that truth, assessments must be carefully designed, following key principles.
Context specificity
Perhaps the most important evidence to emerge over the years is that all competencies are context bound and not generic, a principle that is fundamental to assessment design. It was once assumed that some skills, such as communication, were generic. If you communicated well on one occasion, you were ‘a good communicator’. The ability to communicate was a personality trait. There is now ample evidence that this is not the case. Professionals do not perform consistently from task to task. Explaining a medical condition to a patient may be done well when one particular patient has one particular diagnosis. With varying diagnoses and different patients (e.g. explaining a more complex diagnosis to an angry patient), the individual’s performance will vary. Performance on one case does not generalise to the ‘universe’ of cases and patients. The concept of a ‘generically good communicator’ does not exist.
Given our definition of competency, which emphasises integration of cognitive, psychomotor, and affective skills, this is not surprising. Communication skills and professional behaviours are contextually bound by the knowledge required for that particular situation. An individual’s performance on a particular problem or situation only weakly predicts their performance on a different problem or situation. Although most of us believe that individuals have stable personality traits, research has clearly demonstrated that it is not true. The ‘traits’ individuals exhibit are context-dependent. The situation (i.e. the context) should be considered a better predictor of behaviour than personality.
Two important lessons have been learnt. First, sampling of content must be wide. That was the main catalyst for developing OSCEs and for the demise of the long case. We now understand why sufficient testing time is essential in order to achieve adequate case specificity (reliability across cases), as shown in Figure 14.3, based on data published by Swanson et al (1995). A generalisability coefficient of 1.0 would indicate 100% test reproducibility (see below in section on measuring reliability). In reality, as Figure 14.3 demonstrates, that is rarely achieved because other variables such as examiner performance or poor standardisation of cases impact on tests. A coefficient of >0.8 is the pragmatic aim for most high-stakes tests of clinical competency. Based on that level, at least 14 OSCE cases are needed. Increasing the number of judges improves reliability to a significantly lesser extent (Figure 14.3). Second, more psychometric analyses of traditional methods, such as long cases and orals, have been published, which show that all methods are relevant provided the test is long enough to sample adequately. Sufficient testing across a range of contexts is essential (Figure 14.4). We have been released from the stringencies of examinations. Multiple assessment tools can, if planned appropriately using a sufficient range of contexts, be combined to assess individual performance more validly grounded in the reality of workplaces. (Wass et al, 2001c; van der Vleuten and Schuwirth, 2005).
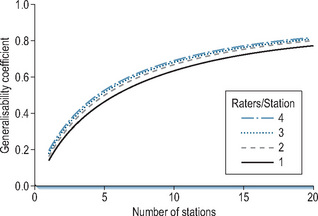
Figure 14.3 • The reliability of the OSCE. Statistics demonstrating how reliability (generalisability coefficient) improved as station number was increased and the number of raters on each station was increased
(from Swanson et al, 1999, with thanks to David Swanson).
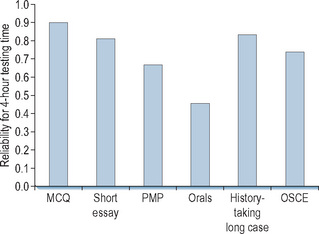
Figure 14.4 • Reliability of different assessment methods over 4-hour testing time (MCQ, Norcini et al, 1985; Short essay, Stalenhoef-Halling et al, 1990; PMP, Norcini et al, 1985; Orals, Swanson, 1987; Long case, Wass and Jolly, 2001; OSCE, Newble and Swanson, 1996).
Blueprinting
It follows that tests must be carefully planned against intended learning outcomes and curriculum content, a process known as ‘blueprinting’. Assessments must validate all the objectives set by a curriculum because students inevitably focus on learning what is tested. Clinical competency is multifaceted. The learning outcomes required, sometimes defined as knowledge, skills, and attitudes, cannot realistically be assessed by a single test format. To assess clinical competence, a battery of different tests is needed. No single one can be valid, given the complexity of clinical competency itself. All tests must use a method that is appropriate to the learning outcome being tested. A multiple choice question (MCQ) may be a valid test of knowledge but not of communication skills, where an interactive test is required. Context specificity must be addressed and integrated into the framework to ensure an appropriate range of case scenarios are used. A blueprint is essential to overcome this complexity (Boursicot et al, 2007). It specifies not just what to assess but also how to assess it. For undergraduate curricula, where core content is more homogeneous, that is easier than for more broadly defined postgraduate curricula (Tombeson et al, 2000). To improve assessments, there is now a move for more detailed definition of their content. Conceptual frameworks to plan assessment programmes are essential and can be designed even for generalist collegiate tests. The assessment programme of the UK Royal College of General Practitioners (Rughani, 2007) provides an example.
Miller’s model of competence assessment
Over the past 20 years, ‘Miller’s triangle’ has provided an invaluable framework for planning clinical competency assessments (Miller, 1990). The model, shown in Figure 14.5, considers progression towards expertise as learners become more knowledgeable. They begin by assimilating knowledge (‘knows’), then apply knowledge (‘knows how’), before acquiring skills (‘shows how’), and finally move to ‘does’: that is, performance in the workplace. Miller’s model can be used to demonstrate the appropriateness of testing methods to competencies being measured. Mapping assessment tools against ‘the triangle’ has increasingly highlighted the lack of robust methods to assess performance (the apex of the triangle). As discussed above, the need to adjust test methodology to developing expertise has tended to be overlooked. There has been reconsideration of Miller’s model. It implicitly assumes that competence, demonstrated under controlled conditions, predicts practice in the real world. Several studies have shown differences between doctors’ performance in controlled high-stakes assessments and the reality of their actual practice (Rethans et al, 1991; Southgate et al, 2001). Knowledge is a pre-requisite for competence (Ram et al, 1999b), but not sufficient alone to predict application in practice. Other influences related both to the individual (stress, health) and systems (conditions of practice) also have a significant impact on performance. Competence (‘shows how’) sheds light on performance but does not fully illuminate it, which Miller’s model lacks the flexibility to reflect. Rethans et al (2002) suggested inverting the triangle to place greater weight on performance and modify it to highlight additional individual and system-related influences. They offered a useful reflection of the challenges faced when moving assessment from the relatively controlled environment of the medical school to the reality of postgraduate training in the workplace.
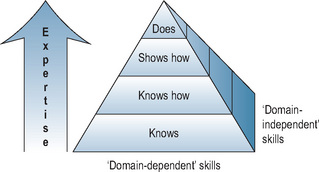
Our version of Miller’s triangle is a three-dimensional pyramid (Figure 14.5), emphasising that blueprints must acknowledge ‘domain-independent’ skills – ones that are not specific to medicine but nevertheless essential facets of professional behaviour. We have added the third dimension because it is increasingly recognised that the two-dimensional (triangle) knowledge model favoured the use of unduly simply summative methodologies. It served as a good planning design but pulled us away from integration. Flexner’s definition of an ideal test (Flexner, 1910) captures the essence of the problem. ‘There is only one sort of licensing test that is significant, namely a test that ascertains the practical ability of the student confronting a concrete case to collect all relevant data and to suggest the positive procedure applicable to the conditions disclosed. A written examination may have some incidental value; it does not touch the heart of the matter.’ Miller has offered a model of identifying how assessments can be combined at different levels of cognition to achieve Flexner’s aim. Professional values must be integrated into the model in order to effectively capture performance.
The utility equation
No assessment tool is perfect. When designing assessment, it is important to acknowledge and weigh logistics. The practicalities of delivery cannot be ignored. The need to balance the concepts described above (Figure 14.2) to address the purpose of a test and reflect the philosophy of the training programme is essential. Choice is generally a compromise. The ‘utility equation’ (van der Vleuten, 1996) provides useful guidance for matching test method to the competency being assessed in the context of the curriculum:
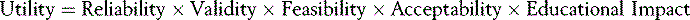
The equation highlights the importance of balancing educational impact with reliability and validity when designing an assessment. Summative tests place more weight within the equation on reliability; formative tests lean more towards educational impact and validity. In addition, van der Vleuten has highlighted the inevitability of addressing the feasibility of implementation. To achieve optimum reliability and validity, an individual needs theoretically to be assessed ad infinitum. That is never possible. Feasibility is intrinsic to assessment delivery. Reliability at this aspirational level is impractical. The time available, recruitment of assessors, administrative requirements, and financial restrictions all impact on test design. Similarly, test validity is undermined if collective acceptance of its theoretical framework is lost due to poor implementation. Constraints of practicality should be explicitly acknowledged. At the same time, assessment proposals must be acceptable to those involved: students, assessors, teachers, and institutions. Acceptability needs to be addressed when balancing assessment decisions.
No test can score uniformly high on all five parameters. Some trade-off is inevitable to ensure the purpose of an assessment is achieved. Utility counterbalances the selection of assessment methods, supporting delivery of a comprehensive, robust, and educationally transparent assessment package. We emphasise again the importance of educational impact. This should be at the heart of the endeavour. Too often, the educational benefits of assessments are lost. All assessors have a responsibility to make assessment a source of learning. Its place in the equation is fundamentally important.
Assessment formats through the continuum
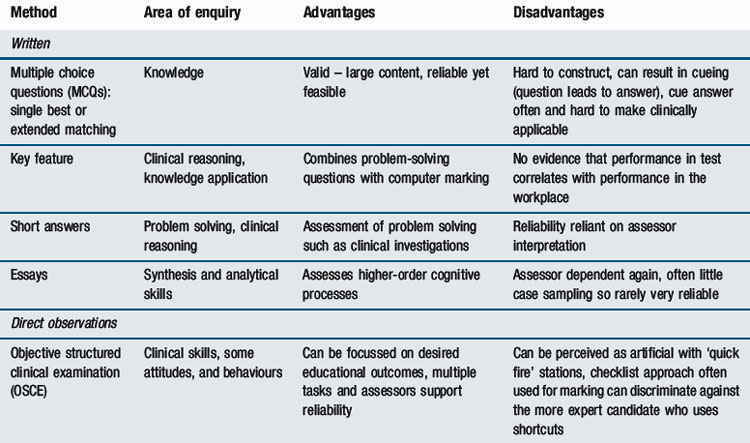
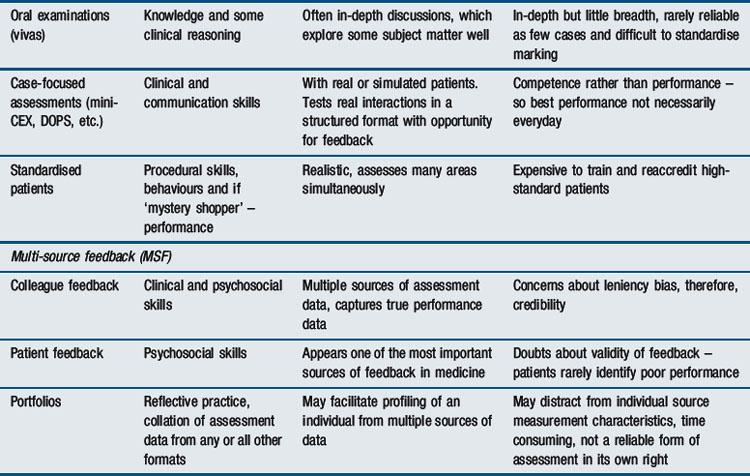
The move away from examinations to more flexible assessment programmes, alongside the increasing aspiration to assess learners in workplaces, offers greater freedom to engage with available assessment tools, both traditional and new (van der Vleuten and Schuwirth, 2005; Wass et al, 2001c). There has been a historical tendency to adopt the latest trend and drop established methods, without reference to any evidence base. As psychometric information has emerged, it has become increasingly clear that the application of a test is more important than the method itself (Figure 14.4). Whatever the format, test length and its consequence, breadth of sampling, is critical (Figure 14.4). More emphasis can be placed on validity, provided context specificity, and hence reliability, are addressed. Now we accept that assessment must be contextual, a range of tools has become available. Expansion of methodological choice allows educational goals to be achieved at the relevant curriculum level of competency. Embedding different methods across the curriculum achieves that, provided they are sufficiently representative and carefully blueprinted. Logistic considerations, neatly summarised by the utility equation, can be balanced across programmes rather than confined to examinations. Methods can be tailored to trainees’ progress along the novice-to-expert pathway, ensuring that assessments are delivered at the relevant point in time on the curriculum map and appropriate feedback is given. The choice of ‘what’ method and ‘when’ presents the challenge. Table 14.3 (modified from Epstein, 2007) summarises the properties of these different formats. Miller’s model (Figure 14.5) shapes the following discussion of available methodologies.
The assessment of ‘knows, and ‘knows how’
From the start of undergraduate curricula, increasing emphasis is being placed on testing ‘knows how’ – that is, applying knowledge to problem solving – rather than ‘knows’ – that is, straight, factual knowledge recall (Figures 14.1 and 14.5). Problem solving is not a generic skill. It is closely linked to knowledge and is context-specific. A candidate’s problem-solving ability is inconsistent across different tasks. As in all areas of clinical competence testing, inter-case reliability becomes an issue (van der Vleuten, 1996). This is more easily solved for written formats, where a large number of questions can be covered relatively quickly. As more complex approaches to assessment have evolved, pure knowledge tests have been criticised for their lack of validity. Yet, they remain a reliable and feasible way of assessing core knowledge. They retain a firm place in undergraduate and postgraduate training programmes and, arguably, in continuing professional development. Scores on pure knowledge tests can predict clinical performance. Studies by the American Board of Internal Medicine (ABIM) (Ramsey et al, 1989) showed a correlation between performance on the ABIM certification examination (a pure multiple-choice test) and performance in practice 10 years later, as assessed by peer ratings. More recently, Norcini et al (2002) linked data on all heart attack cases in Pennsylvania to certification by the ABIM. Physicians certified by this knowledge test had a 19% lower case fatality rate than those who were not. There was a 0.5% increase in mortality in their practice for every year post graduation. That is consistent with knowledge decreasing as experience lengthens (Choudhry et al, 2005). Performance on pure knowledge tests appears to relate positively to health outcomes and negatively to experience.
Multi-choice knowledge tests
Tests of factual recall can take a variety of formats. Multiple choice methods remain the most widely used. They provide a large number of question items across multiple content areas and are relatively easily administered. These tests, if long enough, successfully address context specificity and have high reliability. As discussed, every effort must be made to ensure they challenge the learner at the ‘knows how’ level. To do that, a range of question formats have evolved: single best answer, extended matching, short and long menus of options, and short or long essays are examples (Schuwirth and van der Vleuten, 2003). Currently, the single best answer format is favoured. The correct response to a clinical scenario is selected from a series of options (usually 5). A notable limitation of multiple choice formats is that question items, at the applied knowledge level, are challenging and time consuming to write (Epstein, 2007). The delivery of tests can be modified to drive learning in the direction of the curriculum. The progress test, where all learners sit the same knowledge test simultaneously regardless of the point in the course they have reached, is an example of this (Muijtjens et al, 1998). Progress testing sets out to monitor growth of knowledge over time.
Written knowledge tests
It is hypothesised that validity improves when students are asked to explore subjects in more depth. Difficulties arise with complex scenarios, such as ethical ones, which are highly relevant to clinical practice but lack a clear ‘single best’ answer. Writing options that are sufficiently homogeneous and do not ‘cue’ candidates towards the correct answer is difficult (Schuwirth and van der Vleuten, 2004). When developing new formats, one of the key aims has been to reduce cueing. Traditional essays are notoriously unreliable (Frijns et al, 1990). Structuring essays can both preclude cueing and engage more complex cognitive processes. In terms of utility, though, the gain on validity and educational impact of essays is offset by a loss of reliability. Breadth of content is reduced and inter-rater agreement can be poor unless examiner training is provided using detailed marking schedules. The process is time consuming. This threatens feasibility and acceptability.
Key-feature questions, developed to assess decision-making skills and avoid cueing, offer one of the better solutions (Farmer and Page, 2005). These require short ‘uncued’ answers to clinical scenarios but restrict the candidate’s response to a predetermined number of key statements. That makes it possible to cover more contexts. Script-concordance items present a case (e.g. vaginal discharge), add a piece of clinical information (dysuria), and ask the student to assess the degree to which the new information alters the probability of a diagnosis or clinical outcome (Chlamydia-related pelvic inflammatory disease) (Charlin and van der Vleuten, 2004; Epstein, 2007). There is evidence that such questions provide some insight into practical clinical judgement (Brailovsky et al, 2001). Similarly, computer simulations can replace written scenarios and raise the level of clinical testing by sequentially adding information into a scenario (Cantillon et al, 2004). In the past, these simulations have been complicated. Dynamic and complex situations have been created which require large resources rarely available to those delivering clinical curricula. The need for short simulations, which both cover context specificity and stimulate rather than cue responses, remains a challenge for those developing computer formats.
Orals
The ‘knows how’ of ethical situations and attitudinal issues, the domain-independent skills we emphasised in relation to Miller’s model (Figure 14.5), remains difficult to assess. Traditionally, orals were used (Wass et al, 2003b), predicated on the belief that face-to-face encounters are needed to assess the more domain-independent aspects of professional behaviour. Two recent reviews highlight the difficulties orals present (Davies and Karunathilake, 2005; Memon et al, 2009). Criticism centres on (i) the use of discourse, which can selectively disadvantage certain candidates (Roberts et al, 2000), (ii) the logistics of extending the process sufficiently to address context specificity (Wass et al, 2003b), and (iii) the ‘halo’ effect. The latter is important to assessment in general. Assessors, after making their first judgement, tend not to change their minds. If a candidate performs poorly on the first question, then assessors carry this impression (‘halo’) forwards. Subsequent questions also tend to be judged unfavourably (Swanson, 1987). One of the most striking examples of assessment being poorly informed by evidence is the use of orals to make final pass/fail decisions for borderline candidates taking written tests. It is not rational to use an oral, one of the most unreliable assessment tools, to make a crucial pass/fail decision on a test that in actuality has much higher reliability. Fortunately, that practice is gradually changing. To address the intrinsic difficulties, orals (which many still believe to hold high validity in assessing professional behaviour) can be more reliable if short standardised questions and more examiners are used. Even then, achieving the level of reliability for high-stakes tests is not feasible, and linguistic disadvantage introduces unacceptable bias.
The assessment of ‘shows how’
Long and short cases
The use of unstandardised real patients as ‘long’ or ‘short’ cases to test clinical skills was abandoned many years ago in North America. Change has been relatively slow elsewhere although the authenticity and reliability of this test format has been increasingly challenged. Traditionally, a single long case, where the candidate interviewed a patient for 30–60 minutes and then presented the case to examiners, was unobserved. Ironically, this actually assessed at a ‘knows how’ rather than ‘shows how’ level. In addition, given the context specificity of clinical skills, it is unacceptable to use a single case for a summative assessment. Yet, little published psychometric research on long cases has been published. Initial data (Figure 14.3) suggested that test length is again the key to increasing reliability (Wass et al, 2001a). Attempts have been made to improve the long case format. Observing interaction with patients, perhaps predictably, improves both its validity and the provision of feedback (Wass and Jolly, 2001). More structured long case formats have been developed. The Objective Structured Long Examination Record (OSLER) (Gleeson, 1994) and the Leicester Assessment package (Fraser et al, 1994) both include some direct assessor observation of candidates interviewing patients. Unless the format of long and short cases is improved by viewing candidate–patient interactions and test length is extended to include more cases, the unreliability of this traditional format does not justify its use as a summative tool. An unreliable test cannot be valid.
Objective structured clinical examinations
New methodology was needed. Harden and Gleeson (1979) conceptualised the OSCE in 1979. Candidates rotate through a series of ‘stations’ based on clinical competencies applied across a range of contexts. Skills can be integrated to different degrees within stations. Thus, OSCEs can be adapted as learners advance in their training. The format has become the mainstay of assessment at the level of ‘shows how’ in both undergraduate and postgraduate settings. It offers the capacity to modify both station length and complexity of task according to the level of expertise required. The wider sampling of cases and structured assessment format increase reliability. OSCEs are popular because they improve the balance between validity and reliability. They present a solution to measuring the complexity and integration of clinical competence at a ‘shows how’, rather than ‘knows how’, level. In terms of utility, however, there are drawbacks. The validity of OSCEs is open to challenge (Hodges, 2003). Firstly, with the demise of the long case, real patients have been increasingly replaced by standardised role players who simulate patients. Howley (2004) offers a review of the literature on their use. Learners interact with standardised patients (SP) previously trained to simulate a realistic clinical scenario with a predetermined emotional state. The assessee’s performance is evaluated by the SP, or an observer, or both against the blueprinted competencies. Simulations are the norm in North America, where SPs are extensively trained to carry out the dual role of patient and assessor. This ensures the consistency and reproducibility of scenarios needed to achieve the level of reliability required by North American licensing tests (Colliver et al, 1989). For high-stakes examinations, the costs of training can be justified within the utility equation. This is arguably at the expense of validity. These highly trained ‘assessor SPs’ tend to become ‘professional’ rather than ‘real’ patients. Simulation of physical signs, such as skin rashes or hepatomegaly, is impossible. Real patients can be used where available. In the Western world, the logistics of doing that are becoming increasingly challenging (Sayer et al, 2002).
A second concern about the validity of OSCEs is that reducing integrated skills to checklist items on a mark sheet can impact on both assessees and assessors. Validity may be lost as complex skills, requiring an integrated professional judgement, become fragmented by the relatively short station length (generally 5–10 minutes). Candidate performance, if guided by rote learning rather than practice, can become unrealistic (Talbot, 2004). Experts, as discussed above, develop global pattern recognition. Examiners can find it difficult to work with itemised tasks (Hodges et al, 1999). Scoring against a checklist of items is not as objective as originally supposed. There is increasing evidence that global ratings, particularly by physicians, are as reliable as checklist formats (Regehr et al, 1998). Neither global nor checklist ratings offer a true ‘gold standard’ of judging performance. While checklists may not capture all aspects of physician–patient interactions, global ratings may be subject to other rater biases. Clinicians internalise different standards and approaches to practice. Extensive rater training is required to ensure consistency. An alternative approach excludes the assessor by using written information collected at ‘post-encounter’ stations. Candidates spend 5–7 minutes recording their findings from the SP encounter. It has been argued (Williams et al, 1999) that this approach yields similar data at both the item and test level and minimises some shortcomings of checklists. At some expense to validity, OSCEs have withstood the test of time and sufficiently balanced the challenges of utility at a ‘shows how’ assessment level. The setting, though, remains apart from the real world. As discussed above, assessment of competence at this simulated level does not necessarily predict actual performance. In an attempt to overcome this, there is a significant shift towards assessment in workplaces.
The assessment of ‘does’
There have been significant advances over the last decade in workplace-based assessment (WBA) (Norcini and Burch, 2007), a change with potential for significant educational advantage. Increased curriculum integration encourages more contact with patients from the start of medical school. A patient-centred approach to care can improve health outcomes (Beck et al, 2002; Little et al, 2001). It makes sense to design test methodology to drive patient-centred learning and increase holistic understanding of patients’ needs. To achieve this, assessment must emulate the reality of a patient’s journey through the health services. We need to know how learners perform in the working world and not in a pre-planned controlled environment. At the same time, there is compelling evidence that giving formative feedback to learners, while assessing them in workplaces, can ultimately improve achievement (Norcini and Burch, 2007). Intrinsic to WBA is the need to embed multiple assessment tools in the curriculum and ensure that learners are assessed at the appropriate level of Miller’s model. As the concept of in-training assessment programmes has evolved (van der Vleuten and Schuwirth, 2005), there has been reluctance in some arenas to conceptualise assessment instruments as part of an overall programme. Moving from individual assessment instruments to programmes has created new challenges that are only just beginning to be explored (Davies et al, 2009).
Interestingly, modifications of more traditional methods are coming to the fore. Assessment of clinical competencies in the UK Foundation post-graduation 2-year residency programme is entirely workplace-based. The methods used are, essentially, adaptations of the observed long case (mini-CEX), OSCE stations (direct observation of procedures (DOPs)), and an oral (case-based discussion) (Modernising Medical Careers, 2008). In a sense, there is a swing away from OSCEs back to more traditional methods modified to address context specificity, the issue which originally led to their demise. Most knowledge tests can be improved to test at the ‘knows how’ rather than ‘knows’ level within a traditional written paper format. It remains difficult, though, to assess synthesis and evaluation (Figure 14.1). WBAs, such as audit projects and portfolios, may well prove the answer to assessing a trainee’s ability to apply knowledge at those higher levels of Bloom’s hierarchy. With adequate sampling to cover a range of contexts, assessors, and methods, workplace assessment should theoretically be able to realise adequate reliability. Given the difficulties of standardising content and training assessors, it remains to be seen whether these methods can ever achieve more than medium-stakes reliability. Other biases such as score inflation due to the formative nature of the assessment are of concern (Govaerts et al, 2007).
Workplace-based assessment: methods
Norcini and Burch (2007) have reviewed current methodology. The mini-Clinical Evaluation Exercise (mini-CEX) provides feedback on clinical skills by observing part of an actual clinical encounter (Norcini et al, 2003). By taking a ‘snapshot’, it provides a window into a real consultation. The strength of the mini-CEX lies in its OSCE-style approach. Mini assessments should take place on different days with different assessors and in different contexts. That allows good case sampling and integrates short observation into normal working activities. Direct observation of procedural skills (DOPS) adopts a similar approach for the assessment of skills (Wilkinson et al, 2008). Case-based discussions, or chart-stimulated recall, assess doctors on patient records for whom they have been directly responsible. These are modified orals designed to assess clinical decision-making and patient management. Similar instruments are being developed, based on the same principle of direct observation in clinical settings; wards, outpatient clinics, or operating theatres. This is a time of development. The real challenges lie in combining the tools to achieve reliability while at the same time ensuring that the learners receive constructive formative feedback. In actuality, relative unstandardised approaches, failure to train assessors, and time restraints imposed by clinical practice impact on both (Wilkinson et al, 2008). An innovative approach and exploration of different methodologies is essential.
Direct observation has drawbacks. Observing learners may influence their performance (the Hawthorne effect). It is not a true assessment of actual performance (Hays et al, 2002). One logical step is to remove the rater from the room. That can be done covertly in the workplace to simulate performance (Gorter et al, 2001). Videoing events may offer advantages over direct assessment because both doctors and patients learn to ignore video equipment (Ram et al, 1999a). Video clips offer the additional benefit of creating examples of performance isolated from the event, which can be used to train assessors or rate the interaction independently. Learners can review their performance. Although widely adopted in primary care settings (Campbell and Murray, 1996; Ram et al, 1999a), logistics can be prohibitive (Hays et al, 2002).
Assessment of professionalism
Assessing professional behaviour has gained increasing attention in recent years (Ginsburg et al, 2000). Papadakis’s et al (2005) research highlighted the importance of adding this dimension (Figure 14.5); she demonstrated that unprofessional behaviour as a medical student may predict subsequent poor performance in independent practice. David Stern’s book Measuring Medical Professionalism (see Further reading) reviews the complexity of this area of assessment extensively. In the workplace, multi-source feedback (MSF) methodology, derived from the literature on organisations (Bracken et al, 2001), is now extensively employed. Direct feedback of an individual’s professional behaviour is gained from colleagues. Its popularity arises from the belief that MSF is one of the few methods to assess professionalism and psycho-social skills. Online administration makes it relatively easy to administer. The collation of colleagues’ views provides a reliable series of scores across a number of domains, which can be compared with self-assessment (Archer et al, 2005).
Patient feedback
Another approach centres on the direct involvement of patients. When assessing clinicians, it seems logical to include patients’ views. Patient satisfaction surveys must not be confused with patient feedback. In the latter, patients are asked to comment on a series of high-level competencies, such as clinical care and professionalism. These methods are increasingly used around the world, often in high-stakes situations. The evidence for their robustness is mixed. Patients’ scores correlate poorly with ratings on professional behaviour obtained from work colleagues. They rarely highlight dissatisfaction with their doctors (Crossley et al, 2008) even though colleagues have raised serious concerns (Archer and McAvoy, 2009). Patients may assess professionalism differently from clinical colleagues, although, given the strong similarities of the questions being asked of both, this seems unlikely (Campbell et al, 2008). Politically, it is hard to argue that patients should be excluded from assessing their own doctors. Current methodologies suggest they are either being asked the wrong questions or are not empowered to answer honestly.
Self-assessment and self-monitoring
Most studies define self-assessment as an individual’s ability to identify their own strengths and weaknesses compared to those perceived by others. It has long been hypothesised that engaging the learner in self-assessment places them at the centre of the process. More reliance on self-assessment should theoretically increase the educational impact. Yet, evidence suggests the process is poor (Ward et al, 2002). It is informed by culture and gender rather than a shared reality. Self-assessment appears to be methodologically flawed (Eva and Regehr, 2005). Social psychologists view our behaviour and performance as shaped by our unconscious minds (Bargh, 1999). These are self-serving, primarily focusing on self-preservation. For example, when learners are given negative feedback, they blame external factors and distance themselves from any personal responsibility (Alimo-Metcalfe, 1998). Self-assessment must currently be viewed with caution as an assessment tool.
Self-assessment should not be confused with self-monitoring and reflection. Self-monitoring is the ability to respond to situations shaped by our own capability in a particular context. Reflection, often used interchangeably with self-assessment, represents a very different and important concept. It is a conscious and deliberate process focusing on understanding events and processes to bring about self-improvement (Mann et al, 2009), discussed in more detail in Chapter 2. Reflection is clearly important and may be part of self-monitoring (Eva and Regehr, 2005). Yet, although intuitive, there is little evidence that we achieve a better understanding of ourselves through reflection (Mann et al, 2009). Learners should seek the views of others external to themselves (Eva and Regehr, 2007), which places even greater emphasis on delivering high-quality assessments to ensure valid and reliable feedback is delivered and learners are appropriately supported (Archer, 2010).
These important concepts remain central to our ability to learn from external feedback on assessment performance. Eva and Regehr argue that the ‘health professional community should predominantly be concerned with identifying contextual factors that influence self monitoring behaviours in the moment of action rather than worrying about the accuracy of generic and broader self assessments of ability’ (Eva and Regehr, 2007). This is not to say all individuals respond to feedback in the same way. Individual receptiveness is complex and related to self-awareness, demographic similarity, and acquaintance, and it appears to fall with age (Archer, 2010). A better understanding of these concepts is required if we are to harness successfully the formative feedback, which external assessment offers learners.
Portfolios
One approach to self-monitoring within assessment programmes has been the introduction of portfolios. Broadly defined as a tool for gathering evidence and a vehicle for reflective practice, a wider understanding is developing of portfolios’ potential use in assessment. Portfolios include documentation of, and reflection on, a learner’s personal professional journey. Validity is added to formative assessment. This must be weighed against reliability for summative purposes (Driessen et al, 2005). A recent literature review suggests that these difficulties may not be insuperable (Driessen et al, 2007). The learning portfolio for the UK Foundation Programme provides an interesting example (Modernising Medical Careers, 2008). We need more evidence of its efficacy as an assessment tool. Portfolios have the potential to support reflection. They provide a unique source of evidence to help us understand learners. For portfolios to be effective, though, mentoring is essential to ensure learners reflect constructively on their experience. Without that, the formative role of a portfolio is threatened. The topic of portfolio learning, reflection, and mentoring is also discussed in Chapter 13.
Evaluating assessments: quality assurance
Any attempt at assessing performance has to balance validity and reliability, which makes compromise inevitable. Decisions need to be carefully weighed in relation to the purpose and context of both individual assessments and the assessment programme as a whole. One may, for example, choose a method with lower reliability to accentuate the effect on learning or perhaps even because stakeholders find it acceptable. That may be defensible if the method chosen is only a small part of a total assessment programme. Other, more reliable tests should also be included. The overall programme may contain any method, whether traditional or modern, depending on its stated purpose. This must meet a range of quality criteria in addition to those mentioned in the utility formula (Baartman et al, 2006). Table 14.4 summarises the steps intrinsic to quality assuring assessment programmes (Wass and van der Vleuten, 2006).
Table 14.4 Ten principle steps for the design and quality assurance of an assessment programme
| Principle | Step | |
|---|---|---|
| 1 | Define the purpose of the test | Clarity and transparency of purpose from the start are essential. Use assessment to ‘mirror’ and ‘drive’ the educational outcomes of the training programme |
| 2 | Select the overarching competency structure | Define the learning outcomes you aim to assess over the training period. At which level: knowledge, competence, or performance? |
| 3 | Define the longitudinal novice-to-expert pathway | The programme design should include longitudinal assessment elements and acknowledge the development of expertise across training. At what level on the novice-to-expert scale are you testing? |
| 4 | Design a blueprint | Map the competencies being tested against the curriculum: blueprint to ensure the design is comprehensive and reflects the philosophy of the curriculum |
| 5 | Balance formative and summative feedback | A balance is essential between formative and summative assessment. We need more evidence on how to achieve this within assessment programmes |
| 6 | Choose appropriate tools | Apply the ‘utility equation’ (see text) to determine which tests to use and when |
| 7 | Involve stakeholders | Ensure stakeholders (trainers, trainees, managers, patients) are actively involved in designing and evaluating the programme |
| 8 | Aggregation/triangulation | Judgements of overall performance must be based on aggregated multiple sources of information and triangulation of findings |
| 9 | Programme evaluation | There must be systematic attention to feedback, both quantitative and qualitative |
| 10 | Quality assurance (of test design and administration) | The assessment programme must be continuously monitored and adjusted to ensure constructive alignment with the curriculum and its impact on learning |
Modified from Baartman et al (2006).
Even in well-constructed assessment packages, there are still compromises to be made (van der Vleuten and Schuwirth, 2005). Robust programmes cannot be constructed if they contain poor component parts that fail to stand up to individual scrutiny. Combining the performance of individual components to estimate overall composite reliability, as with the battery of tests used in the past for clinical examinations (Wass et al, 2001b), presents a psychometric challenge as yet unanswered (Davies et al, 2009). One approach is to screen for poor performance and only offer additional assessment methods to struggling trainees. The alternative is a comprehensive assessment programme for all. Each approach has the same important principle at its core. To gain a true reflection of an individual’s ability, sampling across performance in terms of domains, contexts, timelines, and methods is fundamental to success.
Setting standards
Quality inferences about, and expectations of, levels of performance are critical to any assessment. Well-defined and transparent procedures must be set in place to achieve that. When assessment is used for summative purposes, a defensible pass/fail level must be agreed. In reality, there are no hard and fast scientific parameters for achieving one. It is essential that people setting standards are well acquainted with the learners and the expectations of the curriculum. At the same time, learners must fully understand what is expected of them. Various methods are available to support the process. It has to be acknowledged that there are no gold standards. The standard setting process should be viewed as a triangulation of methodologies to justify and defend the parameters being set. It cannot occur in isolation. Final decisions are inevitably informed partly by prior knowledge of the programme and learners and, unavoidably at times, by political influences. We offer guidelines for the methods available.
Criterion referencing
Comparison of performance with peers – that is, norm referencing – is used in examination procedures where a specified number of candidates are required to pass. Performance is described relative to the positions of other candidates. A fixed percentage, for example, all candidates one standard deviation below the mean, always fails. Any variation in difficulty of the test is compensated for. In contrast, variations in the ability of cohorts sitting the test are not accounted for. If the group is above average in ability, those who might have passed in a poorer cohort will fail. This is clearly unacceptable for clinical competency licensing tests, which aim to ensure that candidates are safe to practise. If all trainees meet the standard, then a pass rate of 100% should be achievable. A clear standard, below which doctors would not be considered ‘fit to practise’ needs to be defined. Such standards are set by criterion referencing, where the minimum standard acceptable is agreed. The reverse problem now faces assessors. Although differences in candidate ability are accounted for, variation in test difficulty becomes the key issue. Standards should be set for each test, item by item. Various methods have been developed to do this: ‘Angoff’, ‘Ebel’, ‘Hofstee’, and ‘Contrasting method’. Cusimano (1996), Norcini (2003), and Champlain (2004) offer comprehensive reviews of these methodologies, which can be time consuming but are essential. They permit the setting of a pass/fail cut score prior to and independent of the actual test results. The outcome can then be cross-referenced with this standard and adjustments made (see below) for measurement error. A final decision on the pass/fail score is then reached. The process enables a group of stakeholders (not just assessors) to participate. Lay people can be involved in the setting of standards for health care, a principle that increasingly mirrors the educational philosophy of patient-centred practice (Southgate and Grant, 2004).
More recently, methodology has been introduced using the examiner cohort itself to set the standard during assessments. Examiners, after assessing a candidate, indicate which students they judge to be borderline. The mean mark across all examiners (and there is invariably a range) is taken as the pass/fail cut off (Wilkinson et al, 2001). The robustness of this method across different cohort of examiners remains to be seen (Downing et al, 2003c). Recently, this borderline method has been extended to more reliable regression techniques that are very suitable for application to OSCEs (Kramer et al, 2003). This method is proving useful. Inevitably, as examiner cohorts change, conceptions of borderline will change too. It is important to train assessors before standard setting procedures to achieve consensus on borderline ‘just competent’ performance. The concept can be difficult to internalise but, unless this is achieved, borderline standards may vary with different assessor groups. Selection of methodology will depend on available resources, the consequences of misclassifying examinees, and decisions involving stakeholders. Standard setting is best viewed as an art rather than a science. Using more than one method triangulates opinions and informs final decisions. Unfortunately, learners do not fall neatly into competent and incompetent groups. The pass/fail score has to be agreed within a continuum of performance. The standard setting process inevitably involves error and uncertainty. That makes it even more crucial to create a transparent process, which ensures that the final decision is accountable and defensible. It must not be capricious.
Measuring validity
As discussed above, validity is a complex and fluid concept. Assessment methods are never valid or invalid. Assessors must collate evidence and build a case for validity. Traditionally, to help build a framework for achieving this, a range of ‘facets’ was identified (Table 14.2). These acknowledge that appraising the validity of a test requires multiple sources of evidence (Wass and van der Vleuten, 2006). Many educators still refer to these. ‘Face’ validity represents an overview of the assessment measuring whether the educational intentions have been honoured. ‘Content’ validity requires analysis of whether subject matter has been comprehensively covered. It is also important to evaluate whether the test was appropriate to learners’ level of expertise. That is termed ‘construct validity’. These three facets of validity are relatively easy to evaluate. ‘Predictive validity’ is more challenging. This requires longitudinal follow-up to measure whether trainees’ subsequent clinical performance correlates positively with their previous assessment grades: that is, do the top scoring candidates on knowledge tests subsequently do best in the health care arena? There is some evidence, for example, that UK school ‘A’ level grades are the best predictors of subsequent postgraduate performance (McManus et al, 2003). Finally, to ensure emphasis is placed on the educational impact of assessment, the consequences of the test, ‘consequential validity’, should be appraised (Wass and van der Vleuten, 2006). ‘Does the test produce the desired educational outcome?’ is an important question to ask of any assessment.
This initial, rather pragmatist view of validity has changed. In its contemporary conceptualisation, one unitary concept, ‘construct validity’, is offered (Downing, 2003b). We believe that this redefining of validity is essential to the development of new assessment methodology. The single term embraces the multiple sources of evidence (Table 14.5) needed to evaluate and interpret the outcomes of an assessment. It enables us to move away from the traditional individual descriptive ‘facets’ outlined above and focus more on the sources of evidence needed to validate an assessment process. Five sources of evidence have been identified (Downing, 2003b), which can be used to support or refute the validity of assessment outcomes (Table 14.5). By weighing evidence from both score measurements and quality assurance processes, a more logical, theoretically based, and defensible conclusion can be drawn about whether the original ‘hypothetical’ intentions have been met or not. The context of an assessment, that is, whether it is a ‘high-stakes’ summative or a ‘low-stakes’ more formative process, is also integral to any final conclusions on test validity. Scrutinising assessments against this framework (Table 14.5) offers a useful approach to evaluating validity. Intrinsic to this lies the reality, emphasised above, that quality data are needed to evaluate validity. The integrity of the results (response process), performance of test items (internal structure), and correlations with other test outcomes are all concrete measurements that should be robust. The process loses all value if the test data itself has not reliably ranked candidate performance. A test cannot be valid unless it is also reliable.
Table 14.5 Sources of evidence for measuring validity
| Source of evidence | Type of evidence | Conclusions sought |
|---|---|---|
| Content | Map the assessment against the test specification or blueprint | Have the intended learning outcomes been adequately covered in sufficient contexts? |
| Response process | Scrutinise the integrity of the data: evaluate test material, accuracy of judgements, quality of simulation, etc. | Have all the sources of error associated with the test administration been controlled or eliminated as far as is possible? |
| Internal structure | Assess available statistical or psychometric evidence | How well did the examination questions perform: discrimination, reproducibility, and generalisability? |
| Did items intended to measure the same variables within the test correlate well or not? | ||
| Relationship to other variables | Seek confirmatory evidence to prove the test is measuring what was intended by comparing with previous assessments? | How do the results converge or diverge with performance on other tests? Positive correlations confirm similar and negatives ones different abilities |
| Consequences | Investigate the consequences of the test | What evidence is there that the outcomes of the test benefited or harmed the candidate? |
Adapted form Downing (2003b).
Measuring reliability
Reliability has been defined as the reproducibility of assessment data or scores, over time or occasions (Downing, 2004). We have chosen briefly to outline three approaches to measuring test reproducibility: internal consistency, classical theory, and generalisability (G) theory. References are given for further detailed reading. A plea for different psychometric approaches, which depend less on these rather reductionist measurement of reliability and validity, has been made (Schuwirth and van der Vleuten, 2006). Currently, though, generalisability theory remains the gold standard (Brennan, 2001).
Internal consistency
Internal consistency is based on the concept of ‘test–retesting’. This assumes an ideal situation where a repeat test offered to the same group of learners results in 100% reproducibility; that is, candidate performance on the two tests correlates with a coefficient of 1.0. As already discussed, that is never achieved. There are inevitable sources of variance. Cronbach and Shavelson (2004) developed a statistical method to measure internal consistency within a single test: ‘Cronbach alpha’. Statistically, the test is split into two and candidate ranking across the two halves are analysed. The method is dependent on the homogeneity of the test material. Both halves of the test should be measuring identical clinical constructs. All candidates must have answered the same questions to ensure that significant sources of variance are eliminated. Cronbach’s alpha can be used to measure consistency within items, agreement between raters, internal agreement of rating scales, and the stability of scores on multiple occasions. It is of limited value in more complex assessments where inter-case and inter-rater consistencies present a significant source of error variance.
Classical test theory
Classical test theory assumes that each learner has a true score (‘the signal’) that would be obtained if there were no errors in measurement attributable to external factors (‘the noise’). In reality, as discussed, there is always some variance or ‘noise’ attributable to examiner performance, conditions of testing, etc. A true score is a learner’s average score if measured an infinitely large number of times, when all measurements are independent and stable across different observers and situations. The difference between the observed score and the learner’s true score is the measurement error. The candidate score on any test inevitably does not totally reflect their true ability. The difference between the true score and the observed score is the result of errors in measurement.
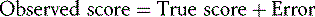
Classical test theory can only estimate reliability by evaluating one source of potential error at a time. It rests on a ‘crossed test’ design. Learners’ scores are measured against a single source of error; for example, ‘the test item’. The learners must all take identical test items. This has significant limitations:
Case specificity
As already discussed, competency is context-specific. One case does not generalise to another. Classical test theory cannot be applied to tests, such as traditional vivas or long cases, where the cohort of candidates have not been assessed on the same questions under the same conditions. Even when identical cases are used, as in OSCEs, failure to standardise patients or role play to ensure identical conditions can result in significant error variance.
Inter-rater reliability
Observers often vary in their interpretation of an assessment even when assessing a learner simultaneously. Inter-rater differences can cause significant error variance. Assessor performance needs to be monitored and training is essential. It helps to build a common understanding of the process and the standard expected. However, there is limited evidence that training assessors effectively reduces inter-rater variance (van der Vleuten and Swanson, 1990).
Intra-rater reliability
Assessors do not necessarily rate consistently. Checklists have evolved in an attempt to reduce this error although evidence now shows that global ratings may be more reliable than checklists (Reznick et al, 1998). Reliability is expressed as a coefficient that represents the proportion of true to error variance:
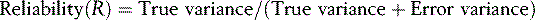
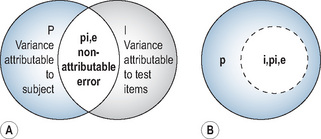
An example of a fully crossed design is when all candidates take the same written paper, which is marked by the same examiner. There are two potential sources of error: (1) test items; (2) examiner ratings. Only two facets are calculable using classical test theory; candidate ability (true variance) and examination items (error variance) In reality, the additional error of examiner inconsistency (intra-rater error) cannot be measured (Figure 14.6).
Standard error of the measurement
Reliability, the probability that an identical pass/fail decision will be made on retesting, is reported in these studies as a coefficient between 0 and 1. A coefficient of 1 represents 100% reliability; in reality, never achieved. The level to aim for is debatable (Downing, 2004). In ‘high-stakes’ testing, where important progression decisions need to be made, setting robust reliability is essential to achieve defensible pass/fail decisions on assessment scores. At a minimum, coefficients of 0.8–0.89 should be aimed for (Downing, 2004). If the stakes are less high, then lower levels are acceptable although less confident and subsequently less defensible. It is increasingly accepted that the precision of measurement – that is, 95% confidence limits – must be defined by applying the standard error of measurement (SEM) at the cut score. The square root of the measurement error (√measurement error) constitutes the SEM. Ninety-five percent confidence intervals are determined by the SEM multiplied by 1.96. Cronbach and Shavelson (2004) ultimately argued that reliability coefficients are more honestly and usefully expressed as confidence limits. When using test–retest theory, this requires a correction for the spread of scores:
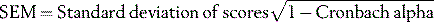
By applying confidence limits to pass/fail scores, as determined by standard setting procedures, decisions become more defensible. Raising the agreed cutoff scores by two standard errors of measurement assures 95% confidence that all passing candidates would still be judged competent if retested. The pass/fail score can be adjusted according to the level of confidence required. Using standard errors of measurement, learners can be evaluated in terms of their proximity to the pass mark. Those approaching the pass score will increasingly have confidence intervals that cross it. There is uncertainty about their accurate placement on the one side or the other of the pass mark. More data on their performance needs to be accrued. This is good educational practice. Identifying and understanding the needs of individuals who are potentially struggling is clearly beneficial.
Generalisability (G) theory
Generalisability (G) theory is an extension of classical test theory designed to overcome these limitations in measuring error variance. It enables several sources of variance error within a test; for example, cases, assessors, and candidates to be quantified individually (Brennan, 2001). A ‘nested’ rather than ‘crossed’ assessment design is used. The candidate score is taken as the main facet and analysed individually against each potential source of variance. A single OSCE case can be ‘nested’ within a rater who sits at one OSCE station throughout the examination. By maintaining the rater and the station as a constant, the variance attributable to the candidate can be estimated. All other variance remains as unattributable error. To assess variance due to assessor ratings, two assessors would need to be nested within a single OSCE station throughout the examination. By keeping the item constant, the impact on candidate score of assessor ratings (inter-rater error) can be estimated. From the variance components, a G coefficient can be calculated, using the same classical test formula:
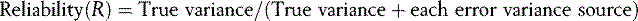
Generalisability theory integrates the discriminating ability of the test and the reproducibility of the result. The coefficient will always be lower than with the classical approach as it takes into account all possible sources of error simultaneously.
Decision (D) studies
The generalisability coefficient is an estimate based on the actual assessment data from which it is formulated. It is also possible to predict test reliability if one of the facets were to be theoretically changed; for example, if the number of cases or number of raters (or indeed both) were to be increased. Decision studies use statistical modelling to modify assessment designs to improve reliability. Generalisability theory was employed in this way, for example, to predict OSCE reliability for a varying number of stations and raters in the example offered previously in this chapter (Figure 14.3). Such predictions can be used to inform the design of future assessments modifying test length, number of items or assessors to identify combinations that achieve acceptable levels of reliability. Although generalisability and decision studies are powerful, prediction does not replace measurement. Decision studies rely on the data presented to them. Modelling assumes that any new sample of subjects, assessors, and items is identical. It is always good practice to re-evaluate reliability.
Item response theory
Classical and generalisability test theories are sample-dependent. They centre on candidate scores. Assessment of item performance is always confounded by the characteristics of subjects taking the items at that point in time. Yet, for test design, it is important to isolate the performance of items per se, for example, level of difficulty, to both understand their individual properties and apply items independently of a particular cohort of examinees. This theoretical approach allows error variance due to candidate cohort ability to be excluded. Only then can items stand alone. A constant independent measurement scale for items can be generated. This permits both scaling of difficulty and legitimate comparison of performance; for example, of changes in student ability if they take the item sequentially over time. Three common item response theory models exist and are reviewed by Downing (2003a). Although technically difficult to apply, awareness of this model is important to understand computer-adaptive testing where the candidate follows a testing pathway determined by their personal capability. The theory can also be used for adjusting rater error in clinical performance assessments.
Future challenges in assessment: implications for practice
The tensions between an educationally formative approach to assessment and the summative stance needed to protect the public from doctors who are unfit to practise continue to dominate the assessment of clinical learners. There are several domains in which assessment is in its infancy and remains a challenge for development and improvement. Setting national standards through a National Licensing Examination is established practice in North America but remains a continuing source of debate elsewhere (Archer, 2009). With increasing globalisation and movement of the medical workforce, international standards should, arguably, be considered to ease migration. Yet, there are concerns in the United Kingdom that, where there is no national licensing system, standards at graduation may differ across medical schools within a single country alone (Boursicot et al, 2006). Opponents argue that standardising exit assessment from medical schools leads to a lack of diversity in curricula and their delivery, preventing innovation. Because of the limitations of assessment methodology, a national examination will focus on lower levels of Miller’s triangle. Doctors and medical schools may be ranked unfairly as actual performance will not be addressed. North American experience, on the other hand, demonstrates that a national licensing test can predict poor performance (Tamblyn et al, 2007). The debate continues, dominated by a concern that a summative end point to medical education will stifle formative development.
Workplace-based assessment remains in its infancy. We are still searching for effective measures of attitudinal behaviours. Experts find it difficult to agree on the definition of professionalism, let alone how to measure it. Of the numerous scales designed to rate communication, there is little evidence that any one is better than another. Patient ratings of professionalism can differ considerably from those given by experts. Quality of care and patient safety depend on effective inter-professional teamwork. There is no validated method of assessing this. There is some early evidence that MSF can identify poor performance. Patient feedback, though, does not appear to discriminate. At the same time, research is focusing on the complexities of self versus peer assessment. The use of multiple methods of assessment can overcome many of the limitations of individual test formats. We need a better understanding of how learners and assessors achieve their professional judgements. The difficulties intrinsic to the imposition of summative progression decisions on a formative process remain unresolved.
Longitudinal assessment avoids excessive testing at any one point in time. It serves as a foundation for monitoring professional development. The collation of results into a portfolio resembles the art of diagnosis; it demands that learners synthesise a varied range of information to establish an overall picture. This is ideal for appraisal, but as discussed, raises important concerns if used for revalidation. We need a better understanding of the emerging evidence that knowledge per se can deteriorate as expertise develops. Clinical expertise implies practical wisdom. Experience enables doctors to manage ambiguous unstructured problems, balance competing explanations, avoid premature closure, and note exceptions to rules and principles. Even under stress, they have the skills to risk decisions that are acceptable but imperfect. Testing either inductive or deductive thinking in situations where there is no consensus on the correct answer presents formidable psychometric challenges. New approaches to combining qualitative and quantitative data on expertise are required if portfolio assessments are to be widely applied and withstand the test of time. Proposals to base revalidation on appraisal lack evidence for its efficacy as a summative tool. Whether formative confidential processes can effectively and fairly assume the summative function of licensing to practise is highly debatable, an issue as yet unresolved.
The direction of travel is, we believe, justified. Assessment must adopt a more formative educational approach. At the same time, new methods and programmes must demonstrate reliability as well as validity. Critics argue that WBA performance judgements lack the robustness needed to make decisions on progression. Yet it is logical to identify trainees in difficulty early to offer more formative support and ensure they progress. A change in the culture of assessment is essential to instil a new assessment ethos in educational supervision. Inevitably, that will take time. A greater understanding of the psychometrics of these novel assessment programmes must be the focus of future research.
Alimo-Metcalfe B. Professional forum: 360° feedback and leadership development. Int J Select Assess. 1998;6:35-42.
Archer J.C. European licensing examinations – the only way forward. Med Teacher. 2009;31:215-216.
Archer J.C. State of the science in health professional education: effective feedback. Med Educ. 2010;44:101-108.
Archer J., McAvoy P. Multi source feedback in high stakes assessment. International physicians assessment coalition. 2009. Quebec, Canada, Abstract only. Available at http://www.ozzawa13.com/OZZAWA%20Abstracts%20and%20Posters.pdf Accessed December
Archer J.C., Norcini J., Davies H.A. Use of SPRAT for peer review of paediatricians in training. BMJ. 2005;330:1251-1253.
Baartman L.K.J., Bastiaens T.J., Kirschner P.A., et al. The wheel of competency assessment: presenting quality criteria for competency assessment programmes. Stud Educ Eval. 2006;32:153-177.
Bargh J.A. The unbearable automaticity of being. Am Psych. 1999;54:462-479.
Beck R.S., Daughtridge R., Sloane P.D. Physician–patient communication in the primary care office: a systematic review. J Am Board Fam Pract. 2002;15:25-38.
Bloom B.S. Taxonomy of educational objectives. London: Longman, 1965.
Boursicot K.M., Roberts T.E., Pell G. Standard setting for clinical competence at graduation from medical school: a comparison of passing scores across five medical schools. Adv Health Sci Educ. 2006;11:173-183.
Boursicot K.A.M., Roberts T.E., Burdick W.P. Structured assessments of clinical competence. Edinburgh: ASME Education, 2007.
Bracken D.W., Timmreck C.W., Church A.H. The handbook of multisource feedback: The comprehensive resource for designing and implementing MSF processes. San Francisco, CA: Jossey-Bass, 2001.
Brailovsky C., Charlin B., Beausoleil S., et al. Measurement of clinical reflective capacity early in training as a predictor of clinical reasoning performance at the end of residency: an experimental study on the script concordance test. Med Educ. 2001;35:430-436.
Brennan R.L. Generalizability theory. New York: Springer-Verlag, 2001.
Campbell L.M., Murray T.M. The effects of the introduction of a system of mandatory formative assessment for general practice trainees. Med Educ. 1996;30:60-64.
Campbell J.L., Richards S.H., Dickens A., et al. Assessing the professional performance of UK doctors: an evaluation of the utility of the General Medical Council patient and colleague questionnaires. Qual Safe Health Care. 2008;17:187-193.
Cantillon P., Irish B., Sales D. Using computers for assessment in medicine. BMJ. 2004;329:606-609.
Champlain de A. Ensuring the competent are truly competent: an overview of common methods and procedures used to set standards on high stakes examinations. J Vet Med Educ. 2004;31:62-66.
Charlin B., van der Vleuten C.P.M. Standardised assessment of reasoning in contexts of uncertainty: the Script Concordance Approach. Eval Health Prof. 2004;27:304-319.
Choudhry N.K., Fletcher R.H., Soumerai S.B. Systematic review: the relationship between clinical experience and the quality of health care. Ann Int Med. 2005;142:260-273.
Colliver J.A., Verhulst S.J., Williams R.G., et al. Reliability of performance on standardised patient cases: a comparison of consistency measures based on generalizability theory. Teach Learn Med. 1989;1:31-37.
Cronbach L.S.R., Shavelson R.J. My current thoughts on coefficient alpha and successor procedures. Educ Psychol Meas. 2004;64:391-418.
Crossley J., Davies H., Cooper C., et al. A district hospital assessing its doctors for re-licensure: can it work? Med Educ. 2008;42:359-363.
Cusimano M.D. Standard setting in medical education. Acad Med. 1996;71(Suppl):S112-S120.
Davis M., Karunathilake I. The place of the oral examination in today’s assessment systems. Med Teach. 2005;27:294-297.
Davies H., Archer J., Southgate L., et al. Initial evaluation of the first year of the Foundation Assessment Programme. Med Educ. 2009;43:74-81.
Downing S.M. Item response theory: applications of modern test theory in medical education. Med Educ. 2003;37:739-745.
Downing S.M. Validity: on the meaningful interpretation of assessment data. Med Educ. 2003;37:830-837.
Downing S.M. Reliability: on the reproducibility of assessment data. Med Educ. 2004;38:1006-1012.
Downing S.M., Lieska G.N., Raible M.D. Establishing passing standards for classroom achievement tests in medical education: a comparative study of four methods. Acad Med. 2003;78:S85-S87.
Dreyfus H.L., Dreyfus S.E. Putting computers in their proper place: analysis versus intuition in the classroom. In: Sloan D., editor. The computer in education: a critical perspective. Columbia, NY: Teachers’ College Press, 1984.
Dreyfus H.L., Dreyfus S.E. The power of human intuition and expertise in the era of the computer. New York: Free Press, 1986.
Dreyfus S.E. Four models v human situational understanding: inherent limitations on the modelling of business expertise USAF. Office Sci Res. 1981. ref F49620-79-C-63
Driessen E.W., Tartwijk van J., Overeem K., et al. Conditions for successful reflective use of portfolios in undergraduate. Med Educ. 2005;39:1221-1229.
Driessen E., Tartwijk J., van der Vleuten C.P.M., et al. Portfolios in medical education: why do they meet with mixed success? A systematic review. Med Educ. 2007;41:1224-1233.
Epstein R.M. Assessment in medical education. N Eng J Med. 2007;356:387-396.
Eraut M. Developing professional knowledge and competence. London: Falmer, 1994.
Eva K.W., Regehr G. Self assessment in the health professions: a reformulation and research agenda. Acad Med. 2005;80:S46-S54.
Eva K.W., Regehr G. Knowing when to look it up: a new conception of self-assessment ability. Acad Med. 2007;82(S10):S81-S84.
Farmer E.A., Page G. A practical guide to assessing clinical decision-making skills using the key features approach. Med Educ. 2005;39:1188-1194.
Flexner A. Medical education in the United States and Canada. New York: Carnegie Foundation for the Advancement of Teaching, 1910.
Fraser R., McKinley R., Mulholland H. Consultation competence in general practice: establishing the face validity of prioritised criteria in the Leicester assessment package. Br J Gen Pract. 1994;44:109-113.
Frijns P.H.A.M., van der Vleuten C.P.M., Verwijnen G.M., et al. The effect of structure in scoring methods on the reproducibility of tests using open ended questions. In: Bender W., Hiemstra R.J., Scherbier A.J.J.A., Zwierstra R.P., editors. Teaching and assessing clinical competence. Gromingen: Boekwerk; 1990:466-471.
Ginsburg S., Regehr G., Hatala R., et al. Context, conflict, and resolution: a new conceptual framework for evaluating professionalism. Acad Med. 2000;75(10 Suppl):S6-S11.
Gleeson F. The effect of immediate feedback on clinical skills using the OSLER. In: Rothman A.I., Cohen R., editors. Proceedings of the Sixth Ottawa Conference of Medical Education. Toronto: University of Toronto Bookstore Custom Publishing; 1994:412-415.
Gorter S.L., Rethans J.J., Scherpbier A.J.J.A., et al. How to introduce incognito standardized patients into outpatient clinics of specialists in rheumatology. Med Teach. 2001;23:138-144.
Govaerts M.J., van der Vleuten C.P.M., Schuwirth L.W., et al. Broadening perspectives on clinical performance assessment: rethinking the nature of in-training assessment. Adv Health Sci Educ Theory Pract. 2007;12:239-260.
Harden R.M., Gleeson F.A. Assessment of medical competence using an objective structured clinical examination (OSCE). J Med Educ. 1979;13:41-54.
Hays R.B., Davies H.A., Beard J.D., et al. Selecting performance assessment methods for experienced physicians. Med Educ. 2002;36:910-917.
Hodges B. Validity and the OSCE. Med Teach. 2003;25:250-254.
Hodges B. Medical education and the maintenance of incompetence. Med Teach. 2006;28:690-696.
Hodges B., Regehr G., McNaughton N., et al. OSCE lists do not capture increasing levels of expertise. Acad Med. 1999;74:1129-1134.
Howley L.D. Performance assessment in medical education: where we’ve been and where we’re going. Eval Health Prof. 2004;27:285-303.
Jamtvedt G., Young J.M., Kristoffersen D.T., et al. Audit and feedback: effects on professional practice on health care outcomes. Cochrane Libr. 2003:1-31.
Kramer A., Muijtjens A., Jansen K., et al. Comparison of a rational and an empirical standard setting procedure for an OSCE. Objective structured clinical examinations. Med Educ. 2003;37:132-139.
Lave J., Wenger E. Situated learning. Legitimate peripheral participation. Cambridge: Cambridge University Press, 1991;1991.
Little P., Everitt H., Williamson I., et al. Observational study of effect of patient centeredness and positive approach on outcomes of general practice consultations. BMJ. 2001;323:908-911.
McManus I.C., Smithers E., Partridge P., et al. A levels and intelligence as predictors of medical careers in UK doctors: 20 year prospective study. BMJ. 2003;327:139-142.
Mann K., Gordon J., Macleod A. Reflection and reflective practice in health professions education: systematic review. Adv Health Sci Educ. 2009;14:595-621.
Memon M.A., Joughin G.R., Memon B. Oral assessment and postgraduate medical examinations: establishing conditions for validity, reliability and fairness. Adv Health Sci Educ. 2009. doi:10.1007/s10459-008-9111-9
Messick S. Validity. In: Linn R.L., editor. Educational measurement. ed 3. Washington, DC: American Council on Education Macmillan; 1989:13-104.
Miller G.E. The assessment of clinical skills/competence/performance. Acad Med. 1990;65:S63-S67.
Modernising Medical Careers. Available at http://www.foundationprogramme.nhs.uk/pages/home/training-and-assessment, 2008. Accessed December 2009
Muijtjens A.M., Hoogenboom R.J., Verwijnen G.M., et al. Relative or absolute standards in assessing medical knowledge using progress tests. Adv Health Sci Educ. 1998;3:81-87.
Newble D.I., Swanson D.B. Psychometric characteristics of the objective structured clinical examination. Med Educ. 1996;22:325-334.
Norcini J.J. Setting standards on educational tests. Med Educ. 2003;37:464-469.
Norcini J.J., Burch V. Workplace-based assessment as an educational tool. AMEE Guide No. 31. Med Teach. 2007;29:855-871.
Norcini J.J., Swanson D.B., Grosso L.J., et al. Reliability, validity and efficiency of multiple choice questions and patient management problem items formats in the assessment of physician competence. Med Educ. 1985;19:238-247.
Norcini J.J., Lipner R.S., Kimball H.R. Certifying examination performance and patient outcomes following acute myocardial infarction. Med Educ. 2002;36:853-859.
Norcini J.J., et al. The mini-CEX: a method for assessing clinical skills. Ann Int Med. 2003;138(6):476-481.
Papadakis M.A., Teherani A., Banach M.A., et al. Disciplinary action by medical boards and prior behavior in medical school. N Engl J Med. 2005;353:2673-2682.
Ram P., Grol R., Rethans J.J., et al. Assessment of general practitioners by video observation of communicative and medical performance in daily practice: issues of validity, reliability and feasibility. Med Educ. 1999;33:447-454.
Ram P., van der Vleuten C.P.M., Rethans J., et al. Assessment in general practice: the predictive value of written-knowledge tests and a multiple-station examination for actual medical performance in daily practice. Med Educ. 1999;33:197-203.
Ramsey P.G., Carline J.D., Inui T.S., et al. Predictive validity of certification by the American Board of Internal Medicine. Ann Int Med. 1989;110:719-726.
Regehr G., MacRae H., Reznick R., et al. Comparing the psychometric properties of checklists and global rating scales for assessing performance on an OSCE-format examination. Acad Med. 1998;73:993-997.
Rethans J.J., Sturmans F., Drop R., et al. Does competence of general practitioners predict their performance? Comparison between examination setting and actual practice. BMJ. 1991;303:1377-1380.
Rethans J.J., Norcini J.J., Baron-Maldonado M., et al. The relationship between competence and performance: implications for assessing practice performance. Med Educ. 2002;36:901-909.
Reznick R.K., Regehr G., Yee G., et al. Process-rating forms versus task-specific checklists in an OSCE for medical licensure. Medical Council of Canada. Acad Med. 1998;73:S97-S99.
Roberts C., Sarangi S., Southgate L., et al. Oral examinations, equal opportunities and ethnicity: fairness issues in the MRCGP. BMJ. 2000;320:370-374.
Rowntree D. Assessing students – how shall we know them? London: Kogan, 1987.
Royal College of Physicians UK. Doctors in society: medical professionalism in a changing world. 2005. Available at www.rcplondon.ac.uk/pubs/books/docinsoc Accessed December 2009
Rughani A. Assessment blueprint of general practice. 2007. Available at http://www.pmetb.org.uk/index.php?id=968 Accessed December 2009
Rust C., O’Donovan B.O., Price M. A social constructivist assessment process model: how the research literature shows us this could be best practice. Assess Eval Higher Educ. 2005;30:231-240.
Sayer M., Bowman D., Evans D., et al. Use of patients in professional medical examinations: current UK practice and the ethico-legal implications for medical education. BMJ. 2002;324:404-407.
Schmidt H.G., Norman G.R. How expertise develops in medicine: knowledge encapsulation and illness script formation. Med Educ. 2007;41:1133-1139.
Schuwirth L.W.T., van der Vleuten C.P.M. ABC of learning and teaching in medicine: written assessment. BMJ. 2003;326:643-645.
Schuwirth L.W.T., van der Vleuten C.P.M. Different written assessment methods: what can be said about their strengths and weaknesses? Med Educ. 2004;38:974-979.
Schuwirth L.W.T., van der Vleuten C.P.M. A plea for new psychometric models in educational assessment. Med Educ. 2006;40:296-300.
Shepard L.A. The role of assessment in a learning culture. Educ Res. 2000;29:4-14.
Southgate L., Grant J. Principles for an assessment system for postgraduate training. Postgraduate Medical Training Board, 2004. Available at http://www.pmetb.org.uk/fileadmin/user/QA/Assessment/Principles_for_an_assessment_system_v3.pdf Accessed December 2009
Southgate L., Campbell M., Cox J., et al. The General Medical Council’s Performance Procedures: the development and implementation of tests of competence with examples from general practice. Med Educ. 2001;35(Suppl 1):20-28.
Stalenhoef-Halling B.F., van der Vleuten C.P.M., Jaspers T.A.M., et al. The feasibility, acceptability and reliability of open-ended questions in a problem based learning curriculum. In: Bender W., Hiemstra R.J., Scherpbier A.J.J.A., et al, editors. Teaching and assessing clinical competence. Boekwerk: Groningen; 1990:1020-1031.
Swanson D.B. A measurement framework for performance based tests. In: Hart I.R., Harden R.M., editors. Further developments in assessing clinical competence. Can-Heal: Montreal; 1987:13-45.
Swanson D.B., Norman G.R., Linn R.L. Performance-based assessment: lessons from the health professions. Educ Res. 1995;24:5-35.
Swanson D.B., Clauser B.E., Case S.M. Clinical skills assessment with standardized patients in high-stakes tests: a framework for thinking about score precision, equating and security. Adv Health Sci Educ. 1999;4:67-106.
Talbot M. Monkey see, monkey do: a critique of the competency model in graduate medical education. Med Educ. 2004;38:587-592.
Tamblyn R., Abrahamowicz M., Dauphinee D., et al. Physician scores on a national clinical skills examination as predictors of complaints to medical regulatory authorities. JAMA. 2007;298:993-1100.
Tombeson P., Fox R.A., Dacre J.A. Defining the content for the objective structured clinical examination component of the Professional and Linguistic Assessment Board examination: development of a blueprint. Med Educ. 2000;34:566-572.
van der Vleuten C.P.M. The assessment of professional competence: developments, research and practical implications. Adv Health Sci Educ. 1996;1:41-67.
van der Vleuten C.P.M., Schuwirth L.W.T. Assessing professional competence: from methods to programmes. Med Educ. 2005;39:309-317.
Van der Vleuten C.P.M., Swanson D.B. Assessment of clinical skills with standardised patients: state of the art. Teach Learn Med. 1990;2:58-76.
Vygotsky L.S. Mind and society: the development of higher psychological processes. Cambridge, MA: Harvard University Press, 1978.
Ward M., Gruppen L., Regehr G. Research in self-assessment: current state of the art. Adv Health Sci Educ. 2002;7:63-80.
Wass V., Jolly B. Does observation add to the validity of the long case? Med Educ. 2001;35:729-734.
Wass V., van der Vleuten C.P.M. Assessment in medical education and training. In: Carter Y., Jackson N., editors. A guide to medical education and training. Oxford: Oxford University Press; 2006:105-128.
Wass V., Jones R., van der Vleuten C.P.M. Standardised or real patients to test clinical competence? The long case revisited. Med Educ. 2001;35:321-325.
Wass V., McGibbon D., van der Vleuten C.P.M. Composite undergraduate clinical examinations: how should the components be combined to maximise reliability? Med Educ. 2001;35:326-330.
Wass V., van der Vleuten C.P.M., Shatzer J., et al. Assessment of clinical competence. Lancet. 2001;357:945-949.
Wass V., Roberts C., Hoogenboom R., et al. Effect of ethnicity on performance in a final objective structured clinical examination: qualitative and quantitative study. BMJ. 2003;326:800-803.
Wass V., Wakeford R., Neighbour R., et al. Achieving acceptable reliability in oral examinations: an analysis of the Royal College of General Practitioner’s Membership Examination’s oral component. Med Educ. 2003;37:126-131.
Williams R.G., McLaughlin M.A., Eulenberg B., et al. The patient findings questionnaire: one solution to an important standardized patient examination problem. Acad Med. 1999;74:1118-1124.
Wilkinson T.J., Newble D.I., Frampton C.M. Standard setting in an objective structured clinical examination: use of global ratings of borderline performance to determine the passing score. Med Educ. 2001;35:1043-1049.
Wilkinson J., Crossley J., Wragg A., et al. Implementing workplace-based assessment across the medical specialties in the United Kingdom. Med Educ. 2008;42:364-373.
Downing S.M., Haladyna T.M. Handbook of test development. Mahwah: Erlbaum Associates, 2006.
Jackson N., Jamieson A., Khan A. Assessment in medical education and training. Oxford: Radcliffe Publishing Ltd, 2007.
Stern D.T. Measuring medical professionalism. Oxford: Oxford University Press, 2004.
Streiner D.L., Norman G.R. Health measurement scales. A practical guide to their development and use. Oxford: Oxford University Press, 2005.