Molecular Biology II: Transcription and Translation
The genetic information encoded in DNA determines the kinds of proteins to be synthesized. However, protein synthesis cannot be immediately directed by DNA. Rather, it is RNA which is synthesized initially using DNA as a template (i.e. transcription). The RNA then serves as a template during protein synthesis (i.e. translation). Thus, the flow of genetic information in a normal cell is as follows:
Various types of RNA molecules are known. Some serve as information carrying intermediates during protein synthesis, whereas others are integral components of the protein synthesizing machinery. In this chapter, synthesis of RNA according to DNA template (transcription) in prokaryotes is considered first. This is followed by a description of genetic code, which defines relationship between base sequence of the RNA and amino acid sequence of the polypeptide. Finally, the process of translation of base sequence of the RNA into the corresponding amino acid sequence of the polypeptide chain is described.
After going through this chapter, the student should be able to understand:
• Types of RNA and distinctive features of the three types of RNAs (mRNA, rRNA and tRNA).
• Transcription: initiation, elongation and termination; roles of RNA polymerase (RNAP) and other protein factors involved in this process; post-transcriptional modifications and processing of RNAs; and inhibitors of transcription.
• Genetic code: general properties, concept of wobble; role of tRNA as an adaptor molecule in translation, and of ribosomes as organelles of protein synthesis.
• Translation: mechanism, initiation, elongation and termination in prokaryotes; post-translational modifications, protein targeting and inhibitors of protein synthesis.
I Types of RNAs
The RNAs are polynucleotides, linked by phosphodiester bonds. They differ as a group from DNA in the following aspects:
1. They are much smaller in size (60–20,000 bp; DNAs often exceed 106 bp) and are mostly single-stranded.
2. The sugar they contain is ribose instead of 2’-deoxyribose of DNA.
3. They contain a pyrimidine base, uracil, instead of thymine of DNA.
Their major role is in gene expression, in contrast to DNA which stores genetic information.
There are three major types of RNAs: ribosomal RNA (rRNA), transfer RNA (tRNA) and messenger RNA ( mRNA). These types differ from one another in terms of size, structure and function.
Ribosomal RNA
rRNA plays important enzymatic and structural role, as constituent of ribosomes which are the protein synthesizing machines of the cell. The other components of ribosomes are protein molecules which are associated in a complex way with the rRNAs. There are three distinct size species of rRNA in prokaryotic cells: 23S, 16S, and 5S (Table 22.1 ).

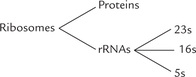
The same types are present in eukaryotic mitochondria, whereas in eukaryotic cytosol there are four size species (28S, 18S, 5.8S and 5S). Ribosomal RNA is most abundant of all types of RNAs, making up around 80% of the total RNA in the cell.
(S is the sedimentation coefficient, i.e. the sedimentation velocity per unit of centrifugal force. It is usually expressed in units of 10-13S, which are known Svedbergs, named after the inventor of the ultracentrifuge. It is related to the molecular mass of the compound being subjected to sedimentation.)
Transfer RNA
This RNA (tRNA) is the smallest of the three major species of RNAs having 73 to 93 nucleotide residues and a sedimentation coefficient of 4S. The tRNAs contain certain unusual bases and have extensive intrachain base pairings. They bind amino acids covalently and deliver them to the ribosome for protein synthesis.
Further details about structure of tRNA and its role as an adaptor molecule in protein synthesis are discussed later in this chapter.
Messenger RNA
Of the three types of RNAs, mRNA is the most heterogeneous type in terms of size, though it comprises only 5% of the total RNA in the cell. Its sequence is complementary to the nucleotide sequence of the template DNA. Consequently, it carries “working copies” of genetic information, originally contained in the DNA, into the cytosol. Once in the cytosol, its nucleotide sequence is translated as a polypeptide chain; the relationship between its nucleotide sequence and the amino acid sequence of the poly-peptide is defined by a genetic code.
Special structural characteristics of eukaryotic mRNA include
(i) a long sequence of adenosine monophosphates (poly A tail) on 3’ end of the RNA chain, plus
(ii) a methylated guanine nucleotide “cap” attached to the 5’ end through a unique 5’-5’ triphosphate linkage.
Note
Only about 5% of the total cellular RNA in E. coli is mRNA, although approximately one-third of the total RNA synthesized in this bacterium is mRNA. This is accounted by short lifespan (few minutes only) of mRNA.
II Transcription
Transcription is a cellular process during which RNA is synthesized using DNA as a template. All three types of cellular RNAs are copied from DNA template in the process of transcription. Only mRNA contains instructions for protein synthesis. The other two types (rRNA and tRNA) are not translated, but perform other vital functions during protein synthesis.
Transcription is similar to replication in terms of chemical mechanism, polarity (direction of synthesis) and use of a template. It differs from replication in two important aspects:
1. Transcription does not require a primer.
2. It involves only short segments of DNA. Within these segments, one of the separated strands of DNA serves as a template (i.e. the template strand); the other strand of DNA is the coding strand.
 Gene expression requires the synthesis of RNA by RNA polymerase (transcription), which is the first step in the mechanism by which genes direct protein synthesis.
Gene expression requires the synthesis of RNA by RNA polymerase (transcription), which is the first step in the mechanism by which genes direct protein synthesis.
RNA Polymerase (RNAP)
RNA polymerase (RNAP) is the principal enzyme of transcription in prokaryotes, which synthesizes all three types of cellular RNAs—mRNA, tRNA and rRNA—in E. coli. It acts according to instructions given by a DNA template and does not need a primer. It is a complex enzyme (500 kD), consisting of various subunits. The subunit structure of the holoenzyme is α2 ββ’σ (Table 22.2 ). The sigma (σ) subunit is loosely bound to the other sub-units. It is not required for the catalytic activity, but it enables the RNA polymerase to initiate the transcription by recognizing certain specific sequences on the DNA. Thereafter it gets dissociated from the holoenzyme, leaving behind the core enzyme (α2 ββ’).
Each of the subunits of the holoenzyme has a distinct role. The β’-subunit helps in the binding of DNA template; while the β-subunit binds the ribonucleoside triphosphate substrates. The α-subunit is necessary to reconstitute active enzyme from separated subunits. The σ-subunit plays an important role in initiating transcription.
A Three Stages of Transcription
Transcription occurs in three stages, i.e. initiation, elongation and termination.
Initiation
Before starting transcription, RNAP has to find the gene. Genes possess recognition sequence immediately upstream (i.e. on 5’ side) of the sequence that would be transcribed (Fig. 22.1 ). Transcription is initiated when RNAP interacts with the recognition sequences on the coding strand of DNA, called the promoters. Binding of the RNAP to promoter directs transcription of the adjacent segment of DNA.
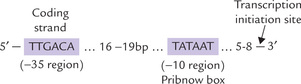
Fig. 22.1 Prokaryotic promoter showing the —10 sequence (Pribnow box) and –35 sequence. By convention, the first nucleotide of the template DNA that is transcribed into RNA is denoted + 1, the transcriptional start site (bp = base pairs).
How does the enzyme find the promoter?
The α2ββ’σ holoenzyme first positions itself on the duplex DNA, forming transient hydrogen bonds with exposed base pairs. This binding is non-selective, occurring with a moderate affinity between the holoenzyme and the bases. Then the holoenzyme slides along DNA. As it encounters the promoter sequence (which is recognized by the σ-subunit), it stops moving further. The transcription initiation complex is now formed, called the closed complex; it consists of the α2ββ’ σ holoenzyme plus the duplex DNA. The duplex DNA must be unwound at this stage, so that one of its strands may serve as template. This unwinding is brought about by the σ-subunit, starting at the conserved AT-rich sequence (Fig. 22.1). This sequence, called the Pribnow box (after David Pribnow who described it in 1975), lies in a region about 10 base pairs upstream of the site where mRNA synthesis starts (i.e. transcription initiation site). A segment of nearly 17 base pairs of DNA is unwound in this manner. This results in formation of the open complex, which consists of the unwound DNA plus the α2 ββ’ σ holoenzyme.
Thus, the σ-subunit plays major role in initiation of the transcription by:
Role of σ Subunit
There has been considerable progress in our understanding of the mechanism by which the σ-subunit helps specific recognition. It does so by decreasing affinity of the RNAP for the general regions of DNA by a factor of about 104. Consequently, the relative affinity of the RNAP for the promoter region becomes much higher, and so the two bind readily.
Role of promoter sequences
The promoter sequences are clustered approximately 10 base pairs (called the –10 bp sequence) and 35 base pairs (called the –35 bp sequence) upstream of the transcriptional initiation site. It is noteworthy that all promoter sequences are recognized by the same σ-subunit, even though the promoters of different genes do not have identical nucleotide sequence. However, a consensus sequence of the most commonly encountered bases can be deduced.
• The –10 sequence has the consensus TATAAT. It is named Pribnow box after the discoverer. It is an important recognition site that interacts with the σ factor of RNA polymerase.
• The –35 sequence has the consensus TTGAGA and is important in DNA-unwinding during transcriptional initiation (Fig. 22.1).
It was puzzling as to why different genes have different promoters. The most plausible explanation is that different genes have to be transcribed at different rates. Some are transcribed up to 10 times per minute, whereas others are transcribed only once in 10 minutes. The factors accounting for different rates of transcription are:
(a) affinity of binding of the RNAP holoenzyme to the promoter site, and
(b) the rate of transition from the closed to the open complex.
These processes depend on base sequence of the promoter. Greater the resemblance between the promoter and the consensus sequences, faster are the above processes, and greater in the rate of transcription. The sequences of strong promoters correspond well with the sequences shown in Figure 22.1, whereas weaker promoters have sequences that differ from these.
The promoter sequences are located on the coding strand and not on the template strand of the DNA. Nucleotide sequences of different promoters show deviations from the consensus sequences to varying extents (consensus sequence is the “average” of sequences of many genes).
Despite its key role in initiation, the σ-subunit does not participate in transcription further. It dissociates from the core enzyme after formation of approximately 10 phosphodiester bonds of the new RNA. The dissociation of the σ-subunit marks the end of the initiation phase of transcription and sets stage for the next phase of transcription, i.e. the elongation phase. The dissociated σ-subunit then joins another core polymerase to initiate another round of transcription. Thus we see that the holoenzyme is involved in selection and initiation also, whereas role of the core enzyme is elongation only.
Elongation
After dissociation of the σ-subunit, affinity of the core enzyme for the promoter decreases markedly. It now moves along the adjacent base sequences of the DNA. The core enzyme plays a pivotal role in the elongation phase, catalyzing the polymerization. New nucleotide units are incorporated in the nascent RNA, one at a time, according to the base pairing rule. Thus, A in DNA is transcribed to U in mRNA, G is transcribed to C, T to A, and C to G. The polymerization occurs in the 5’ →3’ direction like in case of replication. RNAP is processive, i.e. a single enzyme molecule can remain attached to the template and carry out transcription till the end. The region containing RNA polymerase, DNA and nascent RNA is called a transcription bubble, because it contains locally unwound (melted) bubble of DNA. The extent of unwinding area is about 17 base pairs per polymerase molecule (Fig. 22.2 ). Nascent RNA forms a hybrid helix with the template DNA strand in this region.
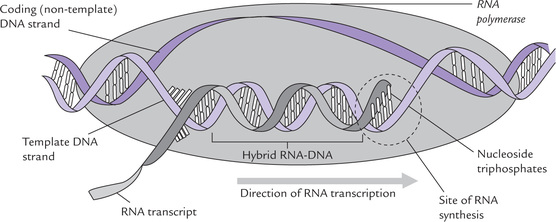
Fig. 22.2 Transcription bubble: RNA polymerase takes instructions from a DNA template to synthesize complementary RNA. Only one of the strands of DNA acts as template (i.e. template strand); the other one is a coding strand (or sense strand).
The precursor molecules for new RNA synthesis are ribonucleoside triphosphates. The 3’-hydroxyl of the RNA is so positioned that it attacks the innermost phosphate of the incoming precursor, forming a new phosphodiester bond. The pyrophosphate that is released drives forward the reaction. This is analogous to the mechanism of “new nucleotide incorporation”, described in replication (Fig. 21.12).
Following initiation, the σ subunit dissociates from RNA polymerase to leave the core enzyme (α ββ’), that uses the antisense stand of DNA is used as a template, and continues RNA synthesis in a 5’→3’ direction using the four ribonucleoside 5’ triphosphates as precursors.
Length of the DNA-RNA hybrid, and the extent of unwound area in duplex remains constant as the RNA polymerase moves along the DNA template. This indicates that DNA is rewound upstream at the same rate as it is unwound downstream. Furthermore, as RNA polymerase causes local unwinding of the duplex DNA, its movement is associated with generation of waves of positive super-coiling ahead of it and of negative supercoiling behind it. Such transcription driven supercoilings are relieved by action of topoisomerases.
RNA polymerase resembles DNA polymerase in several ways, but it differs from the latter in two important aspects:
1. It does not require a primer; it can initiate chain synthesis by assembling the first nucleotide itself.
2. It lacks exonuclease activities; thus, in contrast to DNA polymerase, it does not edit the nascent polynucleotide chain. Consequently, the fidelity of transcription is much lower than that of replication. The error rate in transcription is 104 to 105 times more than that in DNA replication. But relatively higher error-rate in transcription is tolerated since RNA is synthesized and degraded continuously; thus, a single error causes little damage. It is of less consequence to the cell since these errors are not transmitted to the daughter cell, or to the next generation. By contrast, any error in replication produces alteration in permanently stored genetic information, which is transmitted to progeny.
Comparative features of RNAP and DNAP are given in Table 22.3 .
Table 22.3
Comparison of bacterial DNA polymerase and RNA polymerase
| DNA polymerase | RNA polymerase | |
| Substrates | dATP, dGTP, dTTP, dCTP | ATP, GTP, UTP, CTF |
| Primer required | Yes | No |
| Exonuclease activities | Yes | No |
| Subunit structures | 8 subunits in DNAP III Single in DNAP I | α2 ββ′ σ |
| Bases added per second | 10–20 by DNAP I 600–1000 by DNAP III | ≈ 20 |
Sense (+) and antisense (−) strands
It merits re-emphasis that only one strand of the duplex DNA is copied, directing synthesis of new RNA in a given region of genome (Fig. 22.3 ); it is the template or non-coding strand, also called the antisense (-) strand. The other strand is sensestand, also called coding (or non-template) strand. The RNA produced has same sequence as the the sense (+) strand (except that T replaces U).
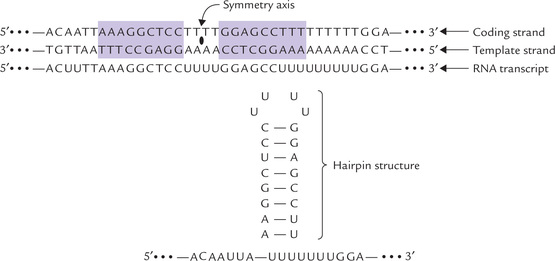
Fig. 22.3 Base sequence of mRNA transcript (transcribed by a palindrome) is self-complementary, and forms a hairpin loop.
It is evident from what has been described so far, that nucleic acid synthesis (whether of DNA or RNA) requires a DNA template. Thus, genetic information coded in DNA is the prime factor for directing the type of protein synthesized.
Termination
RNAP must know the defined site at which to stop RNA synthesis, so that the appropriate size of transcript is produced. This part known as transcription termination is probably the least understood part of RNA synthesis. It occurs by two well characterized mechanisms. The first mechanism, rho-dependent termination, requires the action of a protein factor, called rho (ρ), which recognizes certain termination signals. This halts movement of RNAP along the DNA template. The other mechanism does not require participation of the rho (ρ) factor i.e. p-independent termination).
A consistent feature of all transcriptional termination sites is the presence, i.e. the base sequence of one DNA strand, read in one direction is same as that of the other DNA strand read in the opposite direction (Fig. 22.3). A sequence of this type is called palindrome. When palindrome is transcribed, the base sequence of the RNA transcript is self-complementary.
Therefore, the mRNA transcript of this region forms a self-complementary “hairpain” structure due to internal base pairing (Fig. 22.3). The hairpin loop is often rich in GC base pairs which interact more strongly than AU base pairs. The GC rich region is often followed by a sequence of 6–8 uridine (U) residues. Formation of this secondary loop-structure dislodges the RNAP from the DNA template, resulting in termination of the RNA synthesis in the U stretch.
How does the rho factor participate in termination is still not clear. Two activities of the rho factor are probably involved: the ATPase action and the DNA-RNA helicase action.
1. The ATPase activity releases energy which permits the rho factor to move towards the termination site.
2. RNA-DNA helicase activity helps in separation of the nascent RNA from DNA template at the termination site.
Though rho factor plays important role, specific termination can occur in its absence also. Certain termination sites are present on the template, which do not require the rho factor. Transcription stops at such sites even in absence of this factor.
The transcription bubble travels along the DNA as the RNA chain is elongated stepwise, till it is terminated in response to specific secondary structural elements in the transcript and may require the action of the rho factor.
Recently some more proteins have been reported to mediate termination. For example, the nusA protein enables RNA polymerase in E. coli to recognize a characteristic class of termination sites. Lambda phage synthesizes antitermination proteins that allow certain genes to be transcribed and expressed.
Direction of movement of the replication and the transcription machinery is same to reduce collisions (Box 22.1).
B Post-transcriptional Modifications
The initial product of RNA polymerase, base sequence of which faithfully reflects that of the gene from which it was transcribed, is called the primary transcript. For a primary transcript to be functional, it must be processed before leaving the nucleus. Processing may involve endolytic cleavage (to cut-out unwanted sequences from the primary transcript), splicing, chemical modifications, terminal base additions, etc. Such modifications of RNA after its synthesis by RNA polymerase are collectively referred to as post-transcriptional modifications. Of the three major types, mRNAs are processed extensively in eukaryotes, but rarely in prokaryotes. rRNAs and tRNAs are subject to processing both in eukaryotes and in prokaryotes.
mRNA transcripts of protein-coding genes in prokaryotes require little or no modification before translation. However, ribosomal RNAs and transfer RNAS are synthesized as precursor molecules that require processing by specific ribonucleases to release the mature RNA molecules.
rRNA
The rRNAs are initially synthesized as a large precursor RNA both in eukaryotes and prokaryotes. In E. coli, this precursor contains sequences of 16S, 23S and 5S rRNAs. In some cases, one or several tRNAs are also contained within the precursor. In order to obtain rRNAs (and tRNAs) of the correct size from this precursor, a concerted action of specific ribonucleases of two major types endoribonucleases and exoribonucleases, are required.
• Endoribonucleases cleave phosphodiester bonds within the primary transcript to release individual RNAs, and
• Exoribonucleases trim these RNAs by removing excess nucleotides from their 5’ and 3’ ends till a molecule of correct size is produced (Fig. 22.4 ).
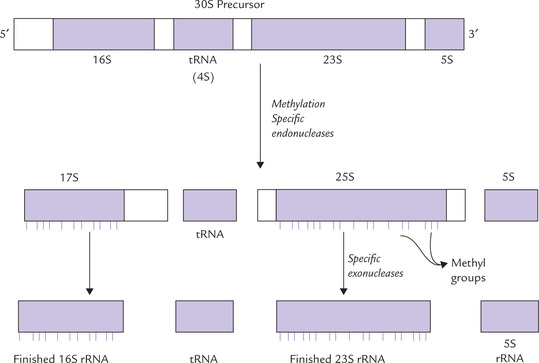
The large precursor RNA contains one copy each of 16S, 23S and 5S RNAs so that they are generated in equal amounts. This mechanism of synthesis ensures that the three rRNAs are available in appropriate amounts for the assembly of ribosome.
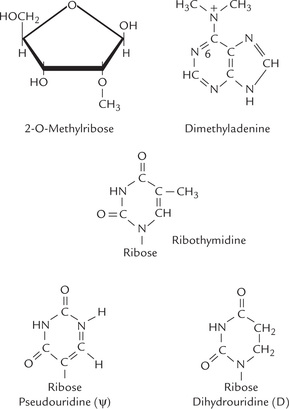
Bacterial rRNAs contain some methylated ribose residues, which are produced post-transcriptionally by methylating enzymes, using S-adenosyl methionine as the methyl group donor (Fig. 22.5 ).
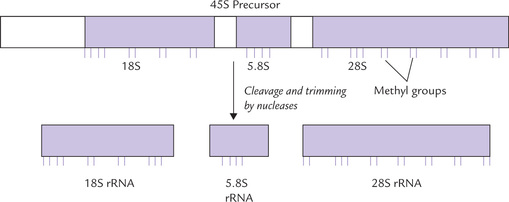
Ribosomal RNAs are derived similarly from a single large precursor in eukaryotes as well (Fig. 22.6 ).
tRNA
In both, prokaryotes and eukaryotes tRNAs are similarly excised from large precursors by ribonucleases. An end sequence containing cytidine, cytidine and adenosine (CCA) is added to the 3’end of the chains. Most tRNAs contain several unusual or chemically modified bases and sugars. Specific nucleotides are modified post-transcriptionally to yield these unusual bases (Fig. 22.5).
As noted in E. coli, three rRNA molecules and a tRNA molecule are obtained from a single primary transcript. Other primary transcripts may contain several different tRNAs or several copies of the same tRNA in addition to rRNAs.
mRNA
Most proteins in prokaryotes are encoded by a single uninterrupted DNA sequence that is copied without alteration to yield a mRNA, which is rarely subject to any post-transcriptional processing. In eukaryotes, the coding sequences (exons) are interrupted by non-coding sequences (introns) and so the primary transcript of mRNA is synthesized as a larger primary transcript, known as heterogenous nuclear (heteronuclear, hn) RNA. The latter undergoes complicated processing (described in Chapter 24).
C Antibiotic Inhibitors of Transcription
Transcription can be inhibited by certain antibiotics that inhibit specific biological processes.
Agents that Bind DNA
Actinomycin D, an antibiotic isolated from Streptomyces antibioticus, contains a planar phenoxazone ring system that becomes intercalated between two G-C base pairs in double-stranded DNA. In addition, this drug has two oligopeptide tails which fit into the grooves of the DNA. When actinomycin D is present RNAP cannot transcribe past the bound drug.
DNA has the same structural design in all organisms. Therefore, actinomycin D is toxic for eukaryotes as well as prokaryotes, and it cannot be used for the treatment of bacterial infections. However, it has been found to be very useful in treatment of Wilm’s tumour, a rare childhood tumour involving the kidney (nephroblastoma). Reason for such specific effects of this drug is not clear.
Agents that Bind RNAP
Rifampicin, a synthetic derivative of a bacterial compound rifamycin B, inhibits transcription in a different way. It binds with RNAP and prevents formation of the first phosphodiester bond in the new RNA chain. The bacteria are not destroyed by this treatment but lose their ability to grow. Thus, the drug is bacteriostatic, not bactericidal. Rifampicin has been successfully used for the treatment of a variety of infections, including tuberculosis. Unfortunately, the bacteria can become resistant to it by point mutation that alters the characteristics of the rifampicin binding site on the β-subunit of RNAP.
Anthramycin is a relatively new drug, which can inhibit both RNA and DNA synthesis.
III Genetic Code
The genetic information flows from the gene to protein, with mRNA serving as information carrying intermediate. Genetic code defines the relationship between the sequence of bases in DNA and the sequence of amino acids. DNA is the repository of all genetic information that directs protein synthesis. Information is coded in the form of a base sequence, as noted earlier. The nucleotide sequence of DNA has been described as a four letter language since it comprises four bases present in DNA (A, T, G, and C). These four code letters are ultimately translated into amino acid sequence. Translation of the four letter language of bases (A, T, C, G) into 20 letter language of amino acids (there are 20 primary amino acids) is an important aspect of molecular biology.
Protein synthesis begins with transcription of specific genes to form mRNA and ends with the assembly of amino acids into the final protein product. The base sequence of mRNA is complementary to that of the DNA which serves as a template. A sequence of three bases in mRNA codes specifically for one amino acid. The primary structure of mRNA and the protein synthesized is colinear (Fig. 22.7 ).
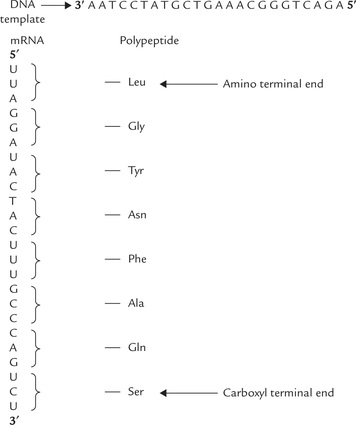
Fig. 22.7 Base sequence of the DNA, the mRNA transcript and the amino acid sequence of polypeptide are colinear.
Three bases of a given sequence in a mRNA serve as code letters or codon for one amino acid; for example, UUU codes for phenylalanine and AAA for lysine. Initially it was thought that the code letters (A, U, G, C) in a group of two are the genetic words or codons for amino acids. But by this arrangement only 16 (42) combinations of bases are possible, which are not sufficient to code for 20 primary amino acids. Four bases in groups of three (triplet) can yield 64 (43) combinations, which are sufficient for 20 amino acids. Therefore, it was established that genetic code consists of three bases and that amino acid sequence of a protein is defined by a linear sequence of triplet codons.
The relationship between the base sequence of the mRNA and the amino acid sequence of the polypeptide is defined by a genetic code. It is a triplet code in which a sequence of three bases on the mRNA, the codon, specifies an amino acid.
A Deciphering the Genetic Code
What is the specific three letter code word for a given amino acid? Initial experiments conducted by Marshall Nirenberg and Heinrich Matthaei provided a major breakthrough in understanding the nature of the genetic code.
1. These workers carried out synthesis of a polyribonucleotide chain of polyuridylate (designated as poly U). The synthetic chain was incubated with a mixture of the 20 primary amino acids and an E. coli extract, the latter providing essential components required for protein synthesis. The synthetic poly U chain may be regarded as mRNA, containing a series of the triplet codon UUU. It was observed that a polypeptide containing phenylalanine residues was synthesized. No other amino acid was incorporated in this chain. This observation led these workers to conclude that this triplet (UUU) coded for phenylalanine.
2. When the experiment was repeated using synthetic poly C, the polypeptide that was synthesized contained only proline residue (polyproline). Therefore, the triplet CCC codes for proline.
3. Using the same approach these workers reported that the triplet AAA codes for lysine.
The synthetic polynucleotides used in these experiments were synthesized by action of the enzyme, polynucleotide phosphorylase. This enzyme catalyzes formation of RNA polymers from the dinucleotide precursors in vitro.
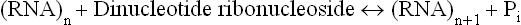
The polynucleotide Phosphorylase is not a template-directed enzyme and the composition of polymer synthesized by it solely depends on the nature of the substrate molecules. For example, if the substrate is UDP, polyU is synthesized, and formation of polyA occurs if the substrate is ADP. If more than one substrate is used, the nucleotide composition of the polymer reflects their relative concentrations. For instance, if the enzyme is presented with a mixture of five parts of ADP and one part of CDP, it will synthesize a random polymer containing maximum triplets of the sequence AAA; fewer of AAC, ACA, and CAA triplets; still fewer CCA, CAC and ACC; and least number of CCC triplets.
By observing relative quantities of various amino acids incorporated in the polypeptide chain, it was possible for Nirenberg and co-workers to identify the triplets coding for them. For example, lysine was incorporated in maximum amount in the above experiment, which indicated that it is encoded by AAA. Least amount of proline was incorporated, indicating that it is encoded by the triplet CCC. Nirenberg was awarded Nobel Prize in 1969 for deciphering the genetic code.
A complementary approach was provided by H. Gobind Khorana (Nobel Prize, 1968) who developed methods to synthesize polymers with repeat sequence of two or four bases. Study of the nature of polypeptides that were synthesized, in response to these RNAs as messengers, permitted unambiguous codon assignments. For example, polymers with defined sequence of two bases (A and C) were synthesized. These copolymers (AC)n had two alternating codons: CAC and ACA. The polypeptide chain synthesized in response to this polymer contained histidine and threonine in equal proportions. This observation, when combined with the earlier information, led to the conclusion that CAC codes for histidine and ACA for threonine. Similar studies, when applied to polymers having four bases with repeat pattern, provided further information regarding assignment of codons.
Specific amino acids coded by 61 of the 64 codons were thus identified. Further, it was found that codons, namely UAA, UAG and UGA, do not code for any amino acid. They are termed as termination codons or stop codons, since translation is terminated whenever these codons are encountered. All the 64 codons are shown in Table 22.4 .
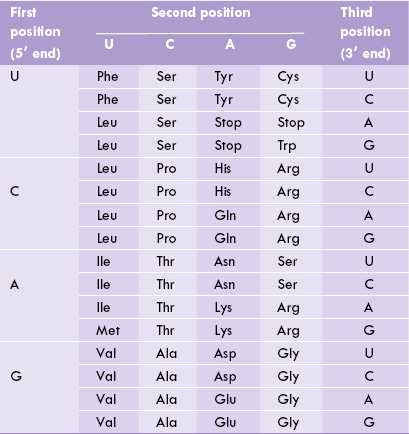
From Table 22.4, it is possible to know the amino acid that corresponds to a given codon. For example, the codon 5’ (AUG) 3’ on mRNA specifies methionine; and 5’ (ACA) 3’ or 5’ (ACG) 3’ or 5’ (ACC) 3’ specify threonine.
B Major Features of Genetic Code
Degeneracy
Perhaps the most striking feature of the genetic code is that it is degenerate, meaning that a given amino acid may be specified by more than one codon. Since 61 codons exist for 20 amino acids, it becomes evident that one amino acid has on an average three codons.
However, degeneracy is not uniform because some amino acids, such as arginine, have six codons. On the other hand, amino acids like tryptophan and methionine are coded by a single codon.
Codons that specify the same amino acid are called synonyms. For example, CAU and CAC are synonyms for histidine. Examination of the synonyms shows that they differ from one another in the third base of the triplet (i.e. the one at 3’ direction). For example, isoleucine is coded by the triplets AUU, AUC and AUA. The first two bases (read from 5’→3’ direction) are same in all the three codons, which thereby serve as the primary determinates of specificity.
Biological significance of degeneracy is not clear. Perhaps it minimizes the deleterious effects of mutations.
Unambiguous
Though degenerate, the genetic code is not imperfect or ambiguous because no codon specifies more than one amino acid. A given codon specifies one and only one amino acid.
The unambiguous nature of genetic code suggests that replacement of a base by another may change the codon, so that it specifies a different amino acid. This may result in incorporation of wrong amino acid in the polypeptide chain that is synthesized. Several disorders are known to arise in this way (Case 22.1).
Universal
A given codon specifies a particular amino acid in different organisms. Thus, in course of evolution, the information specified by the genetic code has remained invariant. There is, however, an exception to it in case of the initiation codon AUG, which determines N-formyl methionine in prokaryotes and methionine in eukaryotes. In addition, some minor variations do occur in genomes of mitochondria and chloroplast (Box 22.2).
Non-overlapping and Commaless
The successive codons occur one after another, meaning that they do not share any nucleotides. The codons are aligned without overlap and without empty spaces in between.
Colinear
The sequence of amino acids in the polypeptide—from the amino end to the carboxy end—corresponds to the base sequence of a gene (from the 5’ end to the 3’ end).
Stop Codons
The stop codons (UAA, UAG and UGA) signal end of polypeptide chain synthesis. Unlike the coding codons, which are read by the corresponding tRNAs, the stop codons are read by certain specific proteins, called release factors.
One of the amino acid coding codons, AUG, is known as initiation codon since it signals beginning of the polypeptide chains in both prokaryotes and eukaryotes.
C Codon-Anticodon Pairing
During protein synthesis, the primary structures of mRNA and the protein synthesized are colinear. However, the codon on mRNA cannot be directly recognized by the corresponding amino acids as there are no specific interactions between bases and amino acids. Rather a codon is recognized by the anticodon on the tRNA that carries the amino acid corresponding to that codon. The three nucleotides on an mRNA codon pair with the three nucleotides of a complementary tRNA anticodon in an antiparallel fashion. The binding is said to be antiparallel because the first base of codon (X’) pairs with the third base of anticodon (X), and the third base of codon (Z’) pairs with the first base of anticodon (Z).
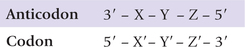
Since there are 61 amino acid coding codons, it is expected that the same number of tRNAs must be present. Actually, however, number of tRNAs is much less. It can, therefore, be logically concluded that one tRNA must be able to base pair with more than one codon.
Crick proposed the wobble hypothesis to explain how a single tRNA can recognize several (degenerate) codons. He assumed that the first two codon-anticodon pairings have normal Watson-Crick geometry, but there is freedom of base pairing between the third codon base (Z’–3) and the first (5’–Z’) anticodon base. The latter can get involved in non-Watson-Crick base pairing with two or three different bases; the allowed pairings for the third codon-anticodon position are listed in Table 22.5 . Thus, if U is present as the first anticodon base, it can pair not only with A but also with G. Thus, such anticodons can base pair with two different codons.
Table 22.5
Imprecision in the binding of the first anticodon base to the third codon base
| First anticodon base | Third codon base |
| C | G |
| A | U |
| U | A or G |
| G | U or C |
| I | U, C or A |
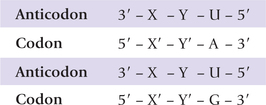
The first anticodon position (termed Wobble position) commonly contains inosine, so that such anticodons can recognize three different codons. By combining the above structural insights with logical deduction, it may be seen that wobble hypothesis accounts for codon degeneracy.
A cosideration of the various wobble pairings indicates that at least 31 tRNAs are required to translate all 61 coding triplets of the genetic code. Actually, however, there are 32 tRNAs in the minimal set because translation initiation requires a separate tRNA. Most cells have more than 32 tRNAs (usually 60), some of which have identical anticodons.
IV Translation
Translation is far more complex than replication and transcription. In the latter two processes, a sequence of bases was simply copied into another sequence of complementary bases. Also, the bases in template interacted specifically by base pairing with the bases of newly synthesized polynucleotide chain. Simply stated, a four-letter language of four bases (A, T, G, C) was copied into four-letter complementary language of four bases. However, such simple design is not possible in translation because it involves translation of the information inherent in the nucleotide sequence (of DNA and mRNA) into a colinear amino acid sequence of polypeptide. Since there is no specific binding interaction between bases and amino acids, this process is evidently more complex.
Translation requires not only the template mRNA and the amino acid substrates for the polypeptide chain, it also needs participation of a number of other biomolecules. In fact, a coordinated interplay of more than a hundred molecules, including tRNA-activating enzymes and protein factors is required in the process of translation. Ribosomes serve as work-benches for all these components.
A tRNAs are the Adaptor Molecules
The tRNAs are small oligonucleotides, containing 70–90 nucleotides. They are used to convert the information of bases in mRNAs into the corresponding sequence of amino acids in proteins, thereby serving as adaptor molecules. They are suited for this role because they can (a) bind with codon on the mRNA, and (b) link with an amino acid corresponding to that codon.
All tRNAs contain an anticodon triplet, which interacts by specific base pairing with the codon on the mRNA chain to select the correct amino acid. For example, a tRNA molecule with the anticodon AAA must attach to phenylala-nine since UUU is the complementary codon for this amino acid. The tRNA specific for phenylalanine is depicted as tRNAPhe and so on for each of the 20 amino acids, using the first three letters of amino acid names as abbreviations. There are nearly 60 different tRNAs in the cell, and each of them presents only one amino acid to ribosome. Though base sequences of tRNAs differ from one another, the following features are common to them all:
1. The tRNA molecule is folded in a clover leaf structure, with three base paired regions and three loops (Fig. 22.8 ). Most important of these loops is the one containing the anticodon. Three bases of anticodon pair with the codon on the mRNA during protein synthesis. The other two loops—D (dihydrouridine) loop and TψC (thymine pseudouridine-cytosine) loop—are named after the conserved bases in their sequence. The D-loop contains dihydrouridine and the TψC-loop contains both pseudouridine and ribothymi-dine. Recognition of the tRNA by the aminoacyl-tRNA synthetase rests on the D-loop; and the TψC-loop binds the tRNA-amino acid to the ribosomal surface during protein synthesis.
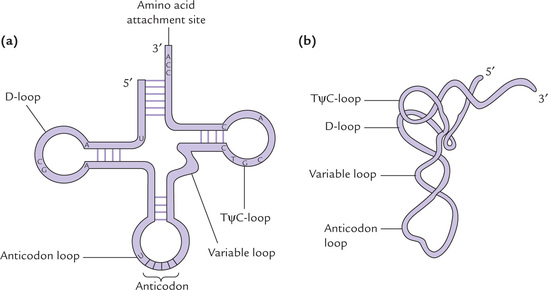
Structures of the dihydrouridine, ribothymidine and pseudouridine are shown in Figure 22.5. In addition, a variable loop (also called extra arm) is also present in most tRNAs.
2. The 3’ terminal ends with the sequence, CCA which links covalently with an amino acid.
3. The 5’ terminal is covalently linked with a phosphate group.
Thus, a tRNA has two functionally important arms: one of these links with amino acid and the other binds a codon.
There is at least one type of tRNA molecule specific for each of the 20 primary amino acids. For some of these amino acids, more than one type of tRNA molecules are present. At least 32 tRNAs are required to recognize all amino acid codons, but most cells contain many more than 32, as discussed later.
B Attachment of Amino Acids to tRNA Molecules
Amino acids are covalently linked to the corresponding tRNAs by soluble cytoplasmic enzymes, aminoacyl-tRNA synthetases to form the amino acid derivative of the tRNA. The latter is called aminoacyl-tRNA and the tRNA with attached amino acid is said to be aminoacylated or charged. The term uncharged tRNA refers to a tRNA molecule lacking an amino acid. The overall acylation reaction, which involves ATP breakdown to supply energy is
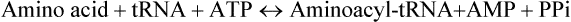
The process is referred to as amino acid activation. The reaction is reversible because the ester bond between amino acid and tRNA has essentially the same energy level as the phosphoanhydride bond in ATP. Nevertheless, the reaction is driven to completion because the inorganic pyrophosphate is hydrolyzed to two molecules of Pi.
Dual specificity of aminoacyl-tRNA synthetase: An amino acid synthetase is specific for (a) the amino acid, which is activated, and (b) the tRNA, which would accept the activated amino acid.
(a) There is a synthetase specific for each of the 20 amino acids. Usually only one aminoacyl synthetase exists for each amino acid, thus each bacterial cell has at least 20 different species of these enzymes. However, for a few amino acids, more than one synthetase does exist (such amino acids are specified by more than one codon).
(b) A given synthetase is specific for the prospective acceptor tRNA molecule also: the synthetase specific for leucine would load leucine to tRNALeu only. If, however, an amino acid can be bound to more than one tRNAs the same enzyme can recognize all prospective acceptor tRNAs. This means that each enzyme recognizes one or more specific tRNAs and attaches the appropriate amino acid to it.
The enzymology of activation is quite similar to that for activation of fatty acids by thiokinase. The reaction similarly occurs in two stages as shown here.
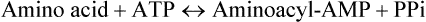
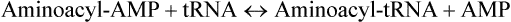
(There are nearly 60 different tRNAs, and each can attach to only one amino acid.)
Proofreading and editing functions: These additional functions of aminoacyl-tRNA synthetases enhance fidelity of the amino acid attachment to tRNA. This is important because it is on the accurate selection of the correct amino acid that the accuracy of translating mRNA into protein depends. Usually the active site of a synthetase is highly specific for its substrate amino acid, but errors do occur, especially when it has to distinguish between very similar amino acids, such as valine and isoleucine, which differ in a single methylene (–CH2) group. The synthetase specific for isoleucine can mistakenly activate valine and attach it to tRNAIle with an error rate of more than 1%, which would result in an unacceptable rate of errors in translation, unless there was a corrective mechanism. A ‘proofreading’ mechanism exists to prevent this, which depends on the presence of an additional catalytic site in the aminoacyl-tRNA synthetase.
Paul berg demonstrated that this catalytic site causes quantitative hydrolysis of the mistakenly activated valine (val AMP) rather than forming val-tRNAIle.
C Ribosomes: The Organelles for Protein Synthesis
Ribosomes are large, catalytically active ribonucleotide-protein particles that serve as workbenches for protein synthesis. Though they do not form a separate compartment in a cell, they have been classified as organelles. In bacteria they float freely in the cytoplasm or attach with plasma membrane, while in eukaryotes they remain either free in cytoplasm or attached to the membrane of endoplasmic reticulum (ER). About 1600 ribosomes are present in an E. coli cell. Eukaryotic cell, on the other hand, contains more than a million.
During protein synthesis, the ribosome binds to a site near the 5’ end of the mRNA and subsequently translates it in the 5’→3’ direction. Concomitantly, the polypeptide chain is synthesized in the amino to carboxy terminal direction.
A ribosome consists of two subunits: a large subunit and a small subunit, held together by non-covalent interactions. According to their sedimentation rate in the ultracentrifuge, the bacterial ribosome subunits are termed 30S and 50S subunits, and the ribosome itself is characterized as 70S (Fig. 22.9 ). The 30S subunit contains 21 proteins and a 16S rRNA molecule. The 50S subunit contains 34 proteins and two rRNA molecules, a 23S species and a 5S species. About two-third of the mass of an E. coli ribosome is RNA, whereas the other third is protein.
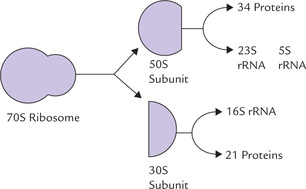
Note
The 16S rRNA plays an important role in initiating protein synthesis at a specific site, as discussed later.
Eukaryotic ribosomes are much larger; 80S ribosome is formed from 40S and 60S subunits.
D How Does Ribosome Know Where to Begin Protein Synthesis
The entire mRNA is not translatable, translation begins at a precise point in mRNA. It is of vital importance that there is an absolute precise initiation by ribosome; in other words, it must initiate correctly. An error of even a single base would be a reading frameshift, resulting in synthesis of a useless protein instead of that specified by the gene. Two kinds of signals determine the site of initiation: (a) the AUG codon, and (b) the Shine-Dalgarno sequence.
AUG Codon
The start site is AUG, less frequently GUG codon, located at least 25 nucleotides away from the 5’-terminal of the mRNA. However, all AUG codons do not necessarily signal beginning of translation: an AUG codon may be located further down the mRNA where it codes for methionine. How is that initiation occurs only at the first AUG and not at the ones located at more internal positions? This confusing situation is resolved by the fact that there are two different tRNAs, both specific for methionine. They have the same anticodon, but one tRNA is used exclusively for initiation and the other exclusively for adding methionine in the elongation process. What then determines the different functions of the two methionine-specific tRNA species? The answer will be evident in the following sections.
Protein Synthesis Starts with N-formylmethionine: The methionine which gets attached to the initiator tRNA (tRNAfMet) is formylated on its amino group by a transformylase in prokaryotes. This enzyme uses N10-formyltetrahydrofolate as formyl donor. As a result, the prokaryote proteins, for the reasons that are not clear, are synthesized with N-formylmethionine as the first unit.
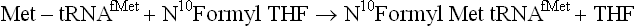
In some proteins, this amino terminus is retained, but more commonly it is deformylated, or fMet is removed by a proteolytic cleavage.
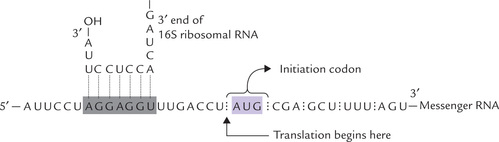
Shine-Dalgarno Sequence
It is a purine rich sequence centred about 10 nucleotides at the 5’ end of the initiator codon (consensus sequence AGGAG). This sequence helps to position the ribosome at the beginning of each protein coding region. It is complementary to a portion of the 16S rRNA in the small ribosomal subunit (Fig. 22.10 ). These sequences interact through hydrogen bonding of complementary base pairs, and this interaction helps to target the ribosome to the protein-coding regions of the mRNA. It is possible that the efficacy of initiation is modulated by strength of this interaction.
E The Process of Protein Synthesis
Translation is a dynamic process that involves the interaction of enzymes, tRNA, ribosomes and mRNA in specific ways to produce a protein molecule. The protein is synthesized from the N-terminus to C-terminus. This complex process is normally divided into three steps: initiation, elongation and termination.
Initiation
Initiation of protein synthesis takes place when:
(i) A ribosome (both small and large subunits) assembles on the mRNA.
(ii) The initiator tRNA (tRNAfMet) occupies a specific site (P site) on ribosome.
The process begins by formation of a 30S initiation complex between the 30S ribosomal subunit, the mRNA and formyl met-tRNAfMet (Fig. 22.11 ). GTP serves as a source of energy to drive this process. Three initiation factors (IF1, IF2 and IF3) are also required for the formation of this complex, as discussed below:
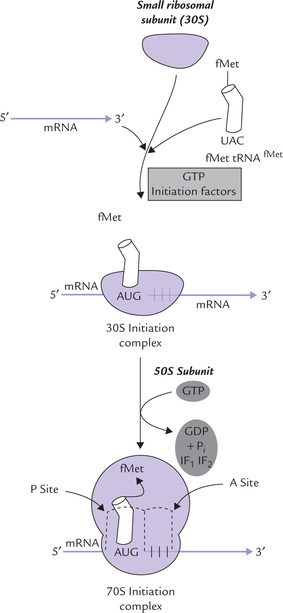
Fig. 22.11 Initiation reactions of protein synthesis require an initiator tRNA charged with formyl methionine (fMet tRNAfMet). The ribosomal subunits assemble with the fMet tRNAfMet, the mRNA and initiation factors along with GTP, to form 30S initiation complex first and 70S initiation complex subsequently.
• IF1 and IF3 increase the rate of dissociation of the ribosomal subunits and maintain the dissociated state, respectively.
• IF2, which contains a bound GTP, is required for the binding of the initiator tRNA to the 30S initiation complex.
At this stage, the 50S subunit joins the 30S initiation complex; simultaneously, the GTP molecule is hydrolyzed to GDP and phosphate. IF2 and IF3 also depart from the ribosome. Joining of the 50S and the 30S subunits results in the formation of 70S initiation complex. In this complex, the initiator tRNA occupies a specific site on the ribosomal surface, called the P site. The initiator tRNA is so positioned that its anticodon pairs with the initiating AUG (or GUG) codon on the mRNA. A second site on ribosomal surface, called the A site, is still empty (Fig. 22.11). It would be occupied subsequently by the incoming aminoacyl-tRNA molecules during the elongation phase.
Elongation
In this stage, the amino acids are added to the growing polypeptide chain in a stepwise fashion, one at a time, in the amino to carboxy terminal direction. In addition to the 70S complex, the other cellular components required in this stage are as below:
• Aminoacyl-tRNA, complementary to the next codon on the mRNA that is positioned in the A site.
• Three soluble proteins: EF-Tu, EF-Ts and EF-G called elongation factors.
The elongation cycle proceeds in three steps:
Step 1: Codon Recognition
The cycle begins with placement of an aminoacyl-tRNA corresponding to the second codon (empty) A site on the ribosome. The protein elongation factor Tu (EF-Tu), a GTP-binding protein, is responsible for the specificity of placement: it delivers the complementary aminoacyl-tRNA whereas its anticodon arm binds the codon on mRNA by complementary base pairing (Fig. 22.12).
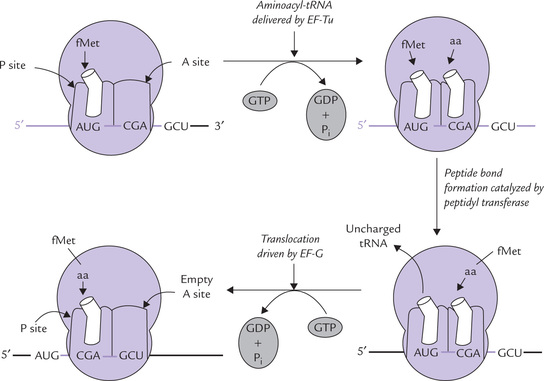
Fig. 22.12 Elongation phase of protein synthesis: codon recognition, peptide bond formation and translocation.
Placement of an aminoacyl-tRNA on the A site is not a passive process. It requires energy that is obtained by hydrolysis of GTP, bound to EF-Tu. Furthermore, EF-Tu is important for ensuring that correct codon-anticodon base pairing occurs. If, however, the anticodon does not base pair with the mRNA codon, the EF-Tu quickly dissociates it and sets it free. If, however, the codon-anticodon match, the bound GTD is hydrolyzed to GDP and phosphate; the EF-Tu then vacates the complex and the aminoacyl-tRNA remains in the A site, ready for peptide bond formation.
The GDP remains tightly associated with EF-Tu. The EF-Tu is made available for another round of protein synthesis by a reaction cycle of this elongation factor (Box 22.3).
Step 2: Formation of a Peptide Bond
At this stage, both A and P sites of a ribosome are occupied by an aminoacyl-tRNA and the stage is set for the formation of peptide bond (Fig. 22.12). This is accomplished by transfer of the formylmethionine unit from the initiator codon (in the P site) to the amino group of the amino acid residue on the aminoacyl-tRNA (in the A site) to from a dipeptidyl-tRNA (Fig. 22.13 ). This reaction does not require an external energy source, because the free energy content of the ester bond in the fMet-tRNAfMet (~ 7.0 Kcal/mole) exceeds the energy required to form a peptide bond (1.0 Kcal/mole) that of peptide bond (≈ 1 Kcal/mole). The enzyme catalyzing this reaction peptidyl transferase, of the large ribosomal subunit is not a ribosomal protein. Rather it is an enzyme activity of the 23S RNA in the large subunit. The 23S rRNA, therefore is a ribozyme, or an RNA enzyme.
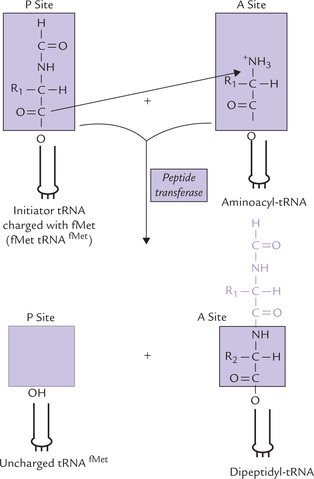
Fig. 22.13 Formation of the first peptide bond through transfer of N-formylmethionine unit to the amino group of the second aminoacyl-tRNA.
At the end of the second step of the elongation cycle, an uncharged tRNA occupies the P site, whereas a dipeptidyl-tRNA occupies the A site (Fig. 22.12).
Box 22.3 Reaction Cycle of Elongation Factor Tu
The elongation factor Tu is involved in delivering the correct aminoacyl-tRNA at the A site of ribosome. The energy for this process comes by GTP hydrolysis. GDP so formed remains tightly attached with the EF-Tu. The following reaction cycle ensures availability of this elongation factor for the next round.
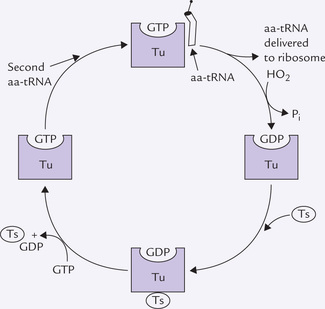
The Tu-GDP complex is bound by another elongation factor, EF-Ts. A complex of Tu-Ts and GDP is thus formed. It is then split by binding of GTP to form Tu-GTP complex; release of Ts-GDP concomitantly occurs. The Tu-GTP complex is now ready to enter the next round of protein synthesis.
Step 3: Translocation
In the final of the elongation cycle, an energy driven movement of the dipeptidyl-tRNA from the A site to the P site occurs, and the uncharged tRNA is released from the ribosome. Codon-anticodon pairing remains uninterrupted during translocation, and therefore, ribosome moves along the mRNA by three bases. Translocation requires a GTP-binding elongation factor, called EF-G. Hydrolysis of the bound GTP provides energy for this step.
This completes a single elongation cycle. In this cycle, the dipeptidyl-tRNA is present at the P site, and the A site is ready to receive the appropriate aminoacyl-tRNA. Occupancy of the A site by aminoacyl-tRNA starts another cycle in which the same series of events are repeated. In this way, the elongation and translocation steps are repeated until a termination codon moves into the A site.
The ribosome synthesizes polypeptides at a rate of approximately 15 amino acids per second.
This is comparable with the speed of RNA synthesis, which is about 20 nucleotides per second.
Termination
Translation termination requires termination factors (also called release factors) that recognize stop codons (UAA, UAG, and UGA). These codons do not have matching tRNAs. When one of these codons appears in the A site, one of the two termination factors (RF1 and RF2) binds with it. RF1 binds with UAA and UAG; RF2 binds to UAA and UGA. A third termination factor, RF3, contains bound GTP. It associates with the RF1 or RF2 and the complex causes the protein (that is attached to the last tRNA molecule in the P site) to be released. This process is an energy dependent reaction catalyzed by the hydrolysis of GTP, which transfers a water molecule to the end of the protein, thus releasing it from the tRNA. After release of the newly synthesized protein, the ribosomal subunits, tRNA and mRNA dissociate from each other.
Some stepnic in protein synthesis require help of soluble cytoplasm proteins, which are known as initiation factors, elongation factors and termination factors. Their action is driven by GTP hydrolysis.
Protein synthesis is energetically expensive: Ribosomal protein synthesis requires input of considerable energy, which is provided by both ATP and GTP:
• Two high-energy phosphate bonds are required for the formation of each aminoacyl-tRNA. Additional ATPs may be required at this step for the correction of errors.
• GTP energy is required at various steps during each elongation cycle: for placement of the aminoacyl-tRNA, for translocation and for termination.
• GTP energy is also required for the formation of initiation complex.
Thus, formation of each peptide bond requires expenditure of at least five high-energy phosphate bonds. Evidently, protein synthesis is an expensive process. In rapidly growing bacterial cell, protein synthesis may consume 30–50% of the total metabolic energy. Humans spend around 5% of the basal metabolic energy for this purpose.
Expenditure of large amount of energy during protein synthesis may appear wasteful. However, it is one of the important factors making nearly perfect fidelity possible, in translation of the genetic message. Moreover, it provides a large thermodynamic push in the direction of protein synthesis.
Polysomes
In prokaryotes, the efficiency of translation is greatly enhanced by polysomes, the clusters of 10 to 100 ribosomes. These ribosomes are closely spaced along a mRNA chain and translate it simultaneously (Fig. 22.14 ). Activity of polysomes allows highly efficient use of the mRNA. This is important because the bacterial mRNAs have extremely short half lives. They are degraded by the nucleases within a few minutes of their formation. Therefore, they must be translated with maximum efficiency; and this is made possible by polysomes.
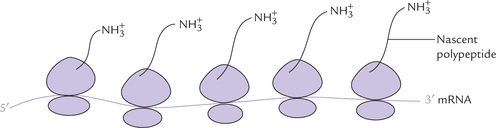
Each ribosome can synthesize only one polypeptide at a time, but an mRNA has a number of ribosomes lined up.
In bacteria, the processes of transcription and translation are tightly coupled. The mRNAs start getting translated even before transcription is complete. Such close coupling is not possible in eukaryotes as the mRNAs have to be transferred out of the nucleus into cytosol, before they can be translated.
F Inhibitors of Protein Synthesis
A number of antibiotics bind to various sites on ribosomes and interfere with individual steps of protein synthesis. Since growth and survival of the cell is not possible without protein synthesis, use of antibiotics eliminates the invading bacteria. Thus, antibiotics are potent tools with which infectious diseases are treated.
Some antibiotics that inhibit eukaryotic and prokaryotic translation are described below. Because of structural differences between prokaryotic and eukaryotic ribosomes, most of these antibiotics are selective either for prokaryotes or for eukaryotes.
1. Streptomycin binds to the 30S ribosomal subunit of prokaryotes, causes misreading of mRNA and thereby prevents formation of the initiation complex.
2. Tetracycline binds to the 30S ribosomal subunit of prokaryotes and inhibits binding of aminoacyl-tRNA to the A site.
3. Chloramphenicol competitively inhibits the peptidyl transferase activity in prokaryotes, thereby interfering with elongation of the peptide chain.
4. Erythromycin binds to the 50S subunit of prokaryotes. It prevents translocation.
These four compounds affect protein synthesis on 70S ribosomes of prokaryotes. Mitochondria also contain the 70S type ribosomes and so these compounds inhibit mitochondrial protein synthesis as well.
5. Ricin and cyclohexamide target eukaryotic 60S and 80S ribosomes, respectively.
6. Puromycin has structural resemblance with the aminoacyl-tRNA. It forms a peptide bond with the growing peptide and prematurely terminates protein synthesis. It is active in both prokaryotes and eukaryotes.
7. Diphtheria toxin prevents the translocation step in eukaryotes (described in Chapter 24).
The inhibition of protein synthesis prevents cell growth, as stated above. But it does not kill the bacteria immediately because most bacteria can survive for considerable periods without protein synthesis. Therefore, most antibiotics that act on ribosomes are not bactericidal but bacteriostatic (streptomycin is an important exception). Moreover, bacteria can become resistant to these antibiotics by mutations that affect the target of drug action (Box 22.4). For example, resistance to streptomycin results because of mutation in the gene for a protein of 30S ribosomal subunit (e.g. S12) to which this antibiotic binds.
G Post-translational Modification of Polypeptide Chain
The nascent polypeptide chain undergoes several modifications which convert it to the biologically active form. In course of its formation, or following its release, the polypeptide chain is folded into its native conformation. The native conformation depends on the primary structure (amino acid sequence) of the polypeptide. It permits formation of maximum number of intrachain interactions, such as hydrogen bonds, or van der Waal forces, ionic, and hydrophobic interactions. In this way, the linear or one-dimensional genetic message in the mRNA is changed into the three-dimensional protein.
In addition to folding, several processing reactions also occur in the polypeptide chain. Some of these are as below:
(i) Phosphorylation: Phosphate group is attached on hydroxyl group of serine, threonine or tyrosine by protein kinases.
(ii) Glycosylation: Carbohydrate side chains are attached to serine or threonine hydroxyl groups (O-linked) or to asparagine (N-linked) within the endoplasmic reticulum or the Golgi apparatus.
(iii) Hydroxylation: Proline and lysine residues of the a-chains of collagen may be extensively hydroxylated in the endoplasmic reticulum (Chapter 5).
(iv) Addition of prosthetic groups: Prosthetic groups required for activity of some proteins are attached after the polypeptide chain leaves the ribosome.
2. Proteolytic processing: Many proteins are initially synthesized as larger, inactive precursors which are not functionally active. Active molecule is formed by proteolytic cleavage of the precursor by specific endopeptidases and removal of the cleaved portion. For example, trypsinogen and chymotrypsinogen are larger precursor molecules, which are converted to trypsin and chymotrypsin, respectively, by proteolysis.
3. Formation of disulphide cross-links between cysteine residues link the adjacent polypeptide chains. These linkages are formed soon after the spontaneous folding.
4. Removal of N-terminal formylmethionine occurs in prokaryotes.
V Protein Targeting
A large number of proteins are synthesized in a cell, which get distributed to various locations. Some of these reside in cytoplasm, whereas others move to specific cellular organelles, or get inserted into membranes, or exported from cell to extracellular functional sites.
Thus newly synthesized proteins must be delivered to a specific subcellular location or exported from the cell where it can carry out its appropriate function. This phenomenon is termed protein targeting.
How do the newly synthesized proteins get directed and coveyed to a specific target sites?
Some mechanism must exist so that the proteins destined for export, for insertion into membranes, or for specific cellular organelles are distinguished from proteins that would reside in the cytoplasm.
A Targeting of Secretory Proteins
Secretory proteins are synthesized by ribosomes bound to the rough endoplasmic reticulum (RER). These proteins have an N-terminal signal peptide (or signal sequence), which enables the protein to move across the membrane of endoplasmic reticulum (ER) into the lumen where it folds into its final conformation. Vesicles then bud off from the ER membrane and carry the protein to the Golgi complex where it gets glycosylated. Other vesicles then carry it to the plasma membrane. Fusion of these transport vesicles with the plasma membrane finally releases the protein to the cell exterior.
Signal hypothesis
It refers to a special mechanism that is operative for exportation of secretory proteins (Fig. 22.15 ). A typical secretory protein differs from a cytosolic protein in having a signal sequence usually comprising first 20–30 amino acids on the amino terminal end of the protein. Signal sequences differ in different polypeptides, but all of them have the following common features:
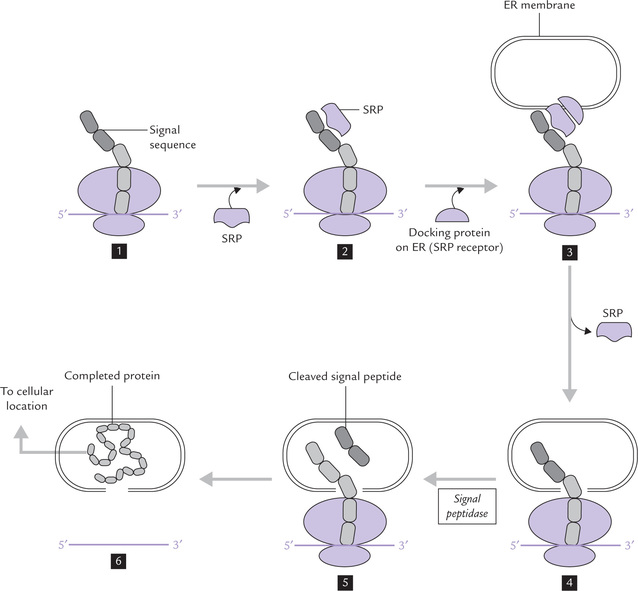
Fig. 22.15 Protein targeting to various destinations in cell occurs by recognition of signal sequence by an SRP (signal recognition particle). The complex of SRP-signal sequence ribosome is recognized by the SRP receptor on ER, and the signal sequence is inserted through a pore in the membrane. Release of signal sequence resumes translation, and the completed protein is delivered to its cellular location.
• A highly hydrophobic sequence of10–15 residues at the centre of the signal sequence; leucine, isoleucine and phenylalanine being common residues in this region.
• At least one positively charged residue (arginine and lysine) near the amino terminal end.
• Five residues, more polar than the hydrophobic core precede the cleavage site at the carboxy terminal.
The signal sequence directs the protein to the ER membrane and targets it into the ER lumen and be exported.
A simplified version of signal hypothesis is shown in Figure 22.15. The signal peptide is recognized by a signal recognition particle (SRP), which is a complex of 7S RNA and six proteins. SRP binds to the signal peptide and stops translation of the remainder of the protein (1–2).
The ribosome-mRNA-SRP complex now binds to a docking protein (called SRP receptor), located on the surface of ER. (3) At this stage, the SRP is set free from the signal peptide, and translation now continues once more. By this time a pore is created in the ER membrane (by a protein translocator), through which the nascent polypeptide passes into lumen of ER (4).
The signal sequence is no longer required beyond this stage and is removed by a signal peptidase. The removal of signal sequence occurs even before the translation is completed (5). The translation continues and the rest of the polypeptide also passes through the membrane pore and enters the lumen of the ER (6). The polypeptide is transferred from ER to Golgi apparatus, and then to its final destination.
Membrane protein targeting: The membrane proteins are also synthesized on the RER but get struck into the ER membrane (and hence ultimately the plasma membrane) rather than being into the ER lumen.
B Nuclear and Mitochondrial Protein Targeting
In eukaryotic cells, there exists completely separate types of translocations—into nucleus and into mitochondrial compartment. In contrast to the proteins discussed, which are synthesized by ribosomes on rough ER, synthesis of the proteins destined for mitochondria and nucleus occurs in free cytoplasmic ribosomes. Delivery to their respective cellular destinations is determined by targeting sequences. It is not a cotranslational event as these proteins are translocated only after their synthesis is complete.
Nuclear proteins: Proteins synthesized in the cytoplasm translocate into the nucleus via special pores. Short targeting sequences, rich in basic amino acids lysine and arginine, are present throughout the length of the proteins and mark them to pass though these pores.
Mitochondrial proteins: The mitochondrion, as already mentioned, has protein synthesizing machinery of its own, but a vast majority of mitochondrial proteins (95%) must be translocated from the cytoplasmic compartment. These proteins are initially targeted to the outer mitochondrial membrane (OMM), requiring an amino-terminal sequence of about 12–70 amino acids. This sequence is rich in basic amino acids and serine and threonine, and forms an amphipathic α-helix in which one side is positively charged and the other side is largely hydrophobic. One or more of these features attach the protein to its receptor on the OMM. After this initial targeting, the subsequent partitioning between the different mitochondrial compartments (the intermembranous space, the inner membrane, or the mitochondrial matrix) is a complex event, and requires several proteolytic events.
Finally, the mitochondrial proteins, but not the nuclear proteins, must be unfolded before transport. This is explained by the large size of the nuclear pores which can accommodate transport of a protein in its native state.
Exercises
Essay type questions
1. In what ways does RNA synthesis differ from DNA synthesis? Discuss roles of sigma factor and rho factor in the initiation and termination, respectively, of the E. coli gene transcription.
2. Compare DNA and RNA polymerase with respect to overall structure, substrates, mechanism of action, error rate, and template specificity. Summarize the post-transcriptional modification of prokaryotic mRNA, rRNA, and tRNA.
3. Define genetic code and discuss its characteristic features. Why do you think 61 codons are actually used to specify the 20 amino acids?
4. By means of diagram(s) explain the process of initiation of transcription of a gene in E. coli.
5. Discuss actions of inhibitors of transcription and translation.
6. How are newly synthesized proteins delivered to their correct destinations?
7. Describe the participation and, where known, the role of GTP in protein synthesis. Why is translation considered an expensive process?
8. Describe the post-transcriptional modifications that the primary transcript undergoes in prokaryotes.
9. Draw a diagram of tRNA indicating its binding sites. What are the functions of different loops in tRNA?