5 GENES
INTRODUCTION
All the cells in the adult body are descended from one cell — the fertilised egg cell — which is formed from the union of a sperm and an ovum (egg). This fertilised cell progresses through many thousands of divisions to produce an incredible variety of cell types, organised neatly into the organs and systems of the body. The descendants of this fertilised cell have different roles: some become skin cells; others blood cells, liver cells or brain cells. However, the genetic information located in the nucleus of each cell is identical, containing the mixture of genetic information from both parents at the time of conception.
In this chapter, you will learn how this genetic information controls events within the cell, and how our parents and grandparents contribute to the range of characteristics that make each one of us unique. This chapter does not discuss alterations to genes that may give rise to genetic diseases or susceptibility to particular diseases or disorders. This is discussed in detail in Chapter 37, where we explore how genetic diseases arise and, importantly, how the link between genes and the environment where people live is related to many diseases and disorders that are prevalent in Australia and New Zealand.
THE NUCLEUS
The nucleus is sometimes referred to as the ‘control room’ of the cell. It directs the activities of the cell, which then determine how the cell interacts with other cells and thus how the entire body functions. The nucleus is a separate membrane-bound compartment inside the cell (known as an organelle; refer to Chapter 3). Small molecules move freely in and out of the nucleus through pores in the nuclear membrane, but larger molecules cannot cross the nuclear membrane unless specific transport mechanisms are in place. This means that some large molecules are found only in the nucleus and others are found only in the cytoplasm. Many of the molecules confined to the nucleus are involved in copying and maintaining chromosomes — the long, thread-like molecules that store genetic information (see Figure 5-1). Chromosomes can be regarded as the ‘instruction manual’ for the cell.
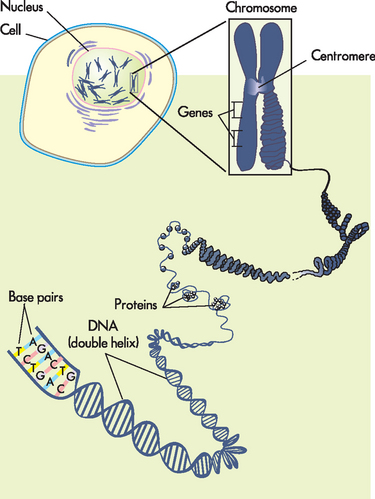
FIGURE 5-1 The cell’s genetic information.
The genetic information of the cell is stored within the nucleus as DNA. DNA is packaged into chromosomes. Note that proteins assist in coiling DNA, forming chromosomes that are located in the nucleus.
Source: Based on Urden LD et al. Critical care nursing: diagnosis and management. 6th edn. St Louis: Mosby; 2010.
Chromosomes are very long, extremely thin molecules of DNA (deoxyribonucleic acid), which are approximately 2 metres long if stretched out from end to end. It is hard to imagine how they fit into the cell nucleus, but this is achieved by coiling them very tightly. While they usually appear in the nucleus as a tangled mass (chromatin), individual chromosomes may become visible as rod-shaped bodies when cells divide.
Except for gametes (egg and sperm), each human cell contains 46 chromosomes, consisting of 22 paired chromosomes (referred to as autosomes) and two sex chromosomes (X or Y). In total, these are usually referred to as 23 pairs of chromosomes. A karyotype is the arrangement of all the chromosomes in a cell (see Figure 5-2). It can be produced by obtaining a blood sample and staining the blood cells during the stages of cell division when individual chromosomes are paired and therefore visible. The chromosomes are arranged in order of size and are numbered sequentially from largest to smallest. Karyotyping can be used to determine the sex of an individual; it can also detect cells with abnormal chromosome numbers (too many or too few chromosomes) or significant chromosomal rearrangements.
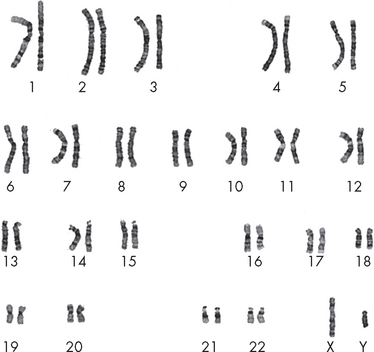
FIGURE 5-2 Karotype of a normal human male.
There are 22 paired chromosomes, numbered from 1 to 22, and two sex chromosomes, X and Y. Note that chromosomes 1, 2 and 3 are the largest, and 21 and 22 are the smallest.
Source: McPherson RA, Pincus RR. Henry’s clinical diagnosis and management by laboratory methods. 21st edn. Philadelphia: Saunders; 2007.
CELL REPRODUCTION
Human life begins when the sperm and ovum (egg) fuse to form a single, functional cell (see Chapter 31). This cell then divides to form two cells, four cells, eight cells, sixteen cells and so on, eventually producing the approximately one trillion cells that make up a human baby. Cell division continues throughout life; it is essential for growth and for the replacement of damaged or aged tissues.
Cells do not simply split in half; they must multiply their organelles, copy their chromosomes and expand their cytoplasm before cell division occurs. When cell division takes place, these components are distributed in approximately equal proportions to each new ‘daughter’ cell. These events occur in a regular rhythm known as the cell cycle. We describe the processes of the cell cycle in the following section. Some cells live only for a short period of time; for instance, skin cells are constantly being replaced because they only survive for approximately one month. In contrast, some neurons in the central nervous system are never replaced — you have them for your entire life. That is why you need to take good care of them! The ultimate goal of the cell cycle is to produce new cells; this requires careful copying and organisation of genes into the new cells.
In most tissues, new cells are created as fast as old cells die. Cellular reproduction is therefore necessary for the maintenance of life. Reproduction of gametes (sperm and egg cells) occurs through a process called meiosis. Briefly, this is where gametes are formed with half the chromosomal content of the parent cells (a full discussion of meiosis is included in Chapter 31 on the reproductive systems). During sexual reproduction, when a sperm and egg cell unite, the chromosomes combine to reconstitute the full chromosomal complement. The reproduction, or division, of other body cells (somatic cells) involves two sequential phases: mitosis, or nuclear division; and cytokinesis, or cytoplasmic division. Before a cell can divide, it must double its size and duplicate its contents. Separation for division occurs during the growth phase, called interphase. The alternation between mitosis and interphase in all tissues with cellular turnover comprises the cell cycle.
The cell cycle
The four designated phases of the cell cycle (see Figure 5-3) are as follows:
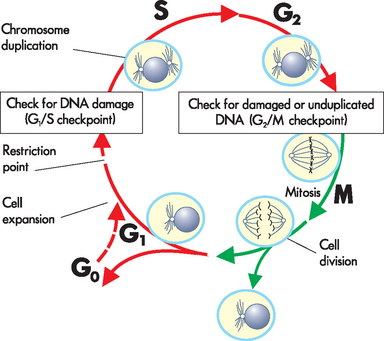
The figure shows the cell cycle phases (G0, G1, G2, S and M), the location of the G1 restriction point, and the G1/S and G2/M cell cycle checkpoints. Skin cells cycle continuously; liver cells spend much of their time in G0, but may enter the cell cycle once or twice a year; nerve cells do not enter the cycle.
Source: Based on Kumar V. Robbins & Cotran pathological basis of disease. 8th edn. Philadelphia: Saunders; 2010; modified from Pollard TD, Earnshaw WC. Cell biology. Philadelphia: Saunders; 2002.
Together, G1, S and G2 form the interphase, which is the longest phase of the cycle.
The cell cycle commences when the cell has just completed a division, when two new cells have been formed. The first phase, the G1 phase, is usually quite long, but its length is variable. During this phase, the cell accumulates the materials required to copy (replicate) the cell’s DNA. If the cell is going to divide again, it will then progress through and enter the S phase when conditions are suitable; for example, when sufficient space and raw materials are available. If the cell is not going to undergo further replication (such as the neurons described above), then it moves out of the G1 phase and into G0, which indicates that it is not actively dividing (see Figure 5-3).
During the S phase, the cell chromosomes are duplicated. This requires replication of the DNA molecules that carry the cell’s genetic information, as well as the production of proteins that fold and assemble the chromosome. After the S phase, each chromosome consists of two identical strands that are held together at a region known as the centromere (refer to Figure 5-1).
In the second gap phase (G2), enzymes that control cell division are produced and mitochondria are replicated so that they can be shared between the new daughter cells. The cell has now completed the interphase and is ready to enter mitosis.
Mitosis is the phase in which the cell nucleus is duplicated, and then the cell is ‘pinched’ into two, forming new daughter cells (see Figure 5-4). Although the cells are genetically identical (having identical DNA), the sharing of cytoplasmic components may not be quite equal, but any differences are subtle and do not affect cell function. Mitosis is subdivided into four phases:
 In prophase, the chromatin untangles and separates into compact chromosomes, and the nuclear membrane breaks down, releasing the chromosomes (two identical DNA strands for each chromosome pair) into the cytoplasm. Very thin fibres attach to the centromere of each chromosome, pulling them towards the midline of the cell. During metaphase, the centromeres line up along the midline of the cell, so that all the chromosomes are arranged side by side. The chromosomes are stretched out and often clearly visible at this stage (using a microscope). In anaphase, the centromeres break and the separate chromosomal strands move to opposite ends of the cell. By the end of anaphase, there are 23 pairs of chromosomes lying at each side of the cell. Barring mitotic errors, each of the two groups of 23 pairs of chromosomes is identical to the original 23 pairs present at the start of the cell cycle. During telophase, the final stage, most of the events of prophase are reversed. The chromosomes become surrounded by new nuclear membranes and adopt the random coil structure of chromatin; two identical nuclei are formed. A band of microfilaments constricts the cell, forming a ‘furrow’ that gradually becomes deeper until the cell eventually undergoes a process known as cleavage, whereby it splits into two daughter cells. Now the original cell has been copied and divided into two identical cells, each with the same genetic information as seen in the original cell.
In prophase, the chromatin untangles and separates into compact chromosomes, and the nuclear membrane breaks down, releasing the chromosomes (two identical DNA strands for each chromosome pair) into the cytoplasm. Very thin fibres attach to the centromere of each chromosome, pulling them towards the midline of the cell. During metaphase, the centromeres line up along the midline of the cell, so that all the chromosomes are arranged side by side. The chromosomes are stretched out and often clearly visible at this stage (using a microscope). In anaphase, the centromeres break and the separate chromosomal strands move to opposite ends of the cell. By the end of anaphase, there are 23 pairs of chromosomes lying at each side of the cell. Barring mitotic errors, each of the two groups of 23 pairs of chromosomes is identical to the original 23 pairs present at the start of the cell cycle. During telophase, the final stage, most of the events of prophase are reversed. The chromosomes become surrounded by new nuclear membranes and adopt the random coil structure of chromatin; two identical nuclei are formed. A band of microfilaments constricts the cell, forming a ‘furrow’ that gradually becomes deeper until the cell eventually undergoes a process known as cleavage, whereby it splits into two daughter cells. Now the original cell has been copied and divided into two identical cells, each with the same genetic information as seen in the original cell.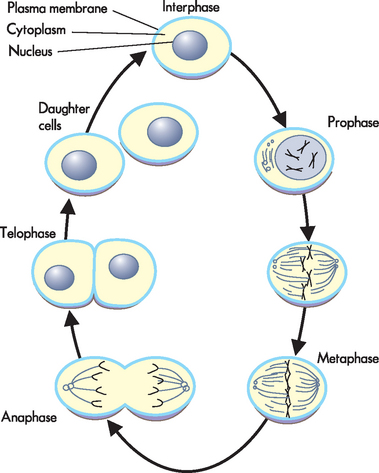
Control of cell division
Although the complete cell cycle lasts 12 to 24 hours, generally about an hour is required for the four stages of mitosis and cytokinesis. The timing and rate of cell division in different parts of the body are critical for normal growth, development and maintenance. Different types of cells have different patterns of division: skin cells divide frequently to replace the outer layer of cells that are constantly being removed, whereas liver cells do not divide unless it becomes necessary to repair damaged tissue. Nerve cells and muscle cells do not divide in adult humans. All types of cells undergo mitosis during formation of the embryo, but this ability to undergo cell division becomes gradually lost in some cell types in the progression from embryo to adulthood.
Normal adult cells may stop dividing owing to lack of nutrients or contact with other cells. However, they always complete the cell cycle that they are currently in and stop late in the G1 phase at the restriction point (see Figure 5-3). Cells can leave the cell cycle at this point and stop dividing; cells that are not dividing are in G0 phase. The restriction point ensures that the cell size is appropriate, that sufficient nutrients are available and that suitable signals have been received before the cell starts a new division cycle.
The G1/S checkpoint is a point of no return. The onset of the S phase commits the cell to continue through the cell cycle to divide, regardless of external conditions such as nutrient supply. This does not mean that the cell is out of control. The precise sequence of events required for successful division seems to depend on the completion of each task before the cell can progress to the next stage.
A second G2/M checkpoint ensures that the chromosomes have been replicated and are intact before allowing the cycle to proceed to mitosis. A final M phase checkpoint determines whether the chromosomes have been properly distributed before cell cleavage occurs. The exact mechanisms by which the cells ‘sense’ the internal environment to determine whether these conditions have been met is unknown.
Failure of these checkpoints to halt the cell cycle is associated with cancer, so they are the focus of much investigation. In a non-cancerous cell, abnormalities that are detected at the checkpoints are either corrected or result in the destruction of the cell. On the other hand, cancerous cells are somehow able to avoid abnormalities in genes from being detected and so they are not destroyed, meaning these abnormal cells survive. Drugs such as chemotherapeutic agents that control the cell cycle have the potential to control the progression and/or spread of tumour cells, and are discussed further in Chapter 36.
In addition to the mechanisms described above which check that cell division has progressed normally, the actual process of cell division can be stimulated and enhanced. For example, certain substances that originate from outside the particular cell, such as hormones or nutrients, can stimulate the cell to undergo the process of division. An example within the body is the hormone erythropoietin, which stimulates the production of red blood cells through cell division. If the level of erythropoietin is increased, the number of red blood cells that are produced is also increased. Similarly, on some occasions, an abundance of nutrients in the extracellular fluid can stimulate a cell to undergo division. In this way, the process of cell division can be influenced or stimulated by substances external to the cell.
DNA AND RNA
DNA (deoxyribonucleic acid) and RNA (ribonucleic acid) are long strands of repeating units. DNA stores genetic information in the cell nucleus, and the DNA always remains in the nucleus. RNA carries copies of relevant parts of this genetic information to the cytoplasm, where it is ‘read’ and directs cell activities. Both RNA and DNA consist of a series of structures, known as nitrogenous bases (because they contain the element nitrogen), linked to a backbone (which consists of sugar-phosphate groups). DNA and RNA have different backbone sugars:
Four different nitrogenous bases (designated A for adenine, C for cytosine, G for guanine and T for thymine) can be attached to the backbone in varying combinations. Because the backbone does not change, knowing the sequence of bases is all that is needed to fully describe a nucleic acid molecule.
DNA contains two nucleic acid strands, running in opposite directions (see Figure 5-5). This double-helix of DNA is now a well-recognised image. The bases on each strand pair together; A is always opposite T and G is always opposite C. This means that a large base (A or G) is always opposite a small base (C or T), so the two strands are always the same distance apart. This is described as complementary base pairing, because A complements T (and G complements C). The two strands are then twisted to form a helix, often described as a ‘twisted ladder’ — the sugar-phosphate backbone forms the sides of the ladder and the pairs of bases form the rungs. The sequence of the bases (A, G, T and C) forms the genetic code.
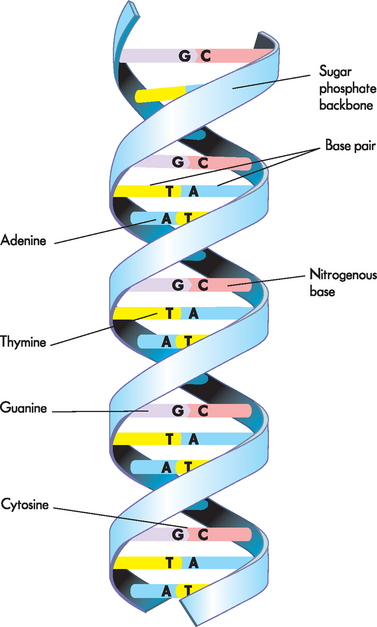
FIGURE 5-5 The structure of DNA.
Note that the two strands wind around one another with paired bases in the centre. A is always opposite T and G is always opposite C, so the sequence of one strand dictates the sequence of the second strand.
Source: Based on Urden LD et al. Critical care nursing: diagnosis and management. 6th edn. St Louis: Mosby; 2010.
DNA must be replicated whenever cell division occurs if identical daughter cells are to be produced. Recall that, in the cell cycle, replication occurs during the S phase (synthesis). Due to the complementary nature of base pairing, a single DNA strand contains all the necessary information required for synthesis of a second, complementary DNA strand. Replication of both strands occurs simultaneously, in opposite directions. The two strands are unwound and separated, and then each strand acts as a template for the synthesis of a new DNA strand.
GENES
Genes are small, discrete sections of chromosomal DNA arranged along the length of the chromosome in single file, without overlap. Spaces between genes also have important roles; for example, they may determine which genes are active in a particular cell and which are ‘silent’. This means that, although every cell has a complete set of genetic instructions, each cell reads only those instructions that are relevant to the activities of that individual cell. Most genes code for a specific protein, whose actions determine particular characteristics. We refer to the process by which a gene directs the production of a protein as gene expression. Some genes influence a certain set of characteristics in a particular way, so are responsible for traits such as hair and eye colour, blood group and nose shape. Others are associated with inherited diseases, such as phenylketonuria (PKU), Huntington’s disease and cystic fibrosis (see Chapter 37).
Alleles
Alleles are alternative forms of a gene, found at a particular position (locus) on the chromosome (remember that a chromosome is the structural organisation of DNA). Because cells contain paired chromosomes, every cell contains two alleles for each gene (one allele received from each parent when gametes fuse). A cell may contain two identical alleles, or two different alleles; in most cases, both alleles will be expressed, so will direct the synthesis of specific proteins. Alternative alleles for a particular gene typically direct production of slightly different proteins; these differences produce a range of outcomes, such as straight, wavy or curly hair. The situation is different for genes associated with disease: where normal alleles code for functional proteins, alleles associated with disease code for non-functional or harmful proteins.
Production of proteins
All of a cell’s activities depend on proteins. Some proteins have structural roles; for example, forming the cytoskeleton framework that gives the cell its particular shape. Some proteins become embedded in cell membranes, where they transport specific molecules into and out of the cell. Yet others act as enzymes that speed up the rate of biochemical reactions and provide energy for cellular processes. Of course, proteins are needed for tasks outside the cell too; body fluids such as blood and lymph contain a wide range of proteins with essential functions, including hormones, antibodies and transport proteins such as haemoglobin. These circulating proteins are also produced in cells, and are then exported from the cell and delivered to their final destination. The production of proteins is also referred to as protein synthesis, as the word synthesis refers to the combining of two or more components to form a new product.
How do genes code for proteins?
Genes in chromosomes determine the sequence of amino acids in proteins in much the same way as we use letters to construct words that we organise into sentences. As discussed earlier, DNA is made up of four different bases (A, G, C and T). These bases (letters) are arranged in different three-base combinations, each of which corresponds to a particular amino acid (three-letter word) (see Figure 5-6). Different combinations of amino acids make different proteins (sentences). As genes are very long, containing thousands of bases, the number of different combinations is vast. Changing a base, or the order of bases, can change an amino acid, or the order of amino acids, and therefore make a protein with a different function. Again, we are familiar with this from simple language, such as:
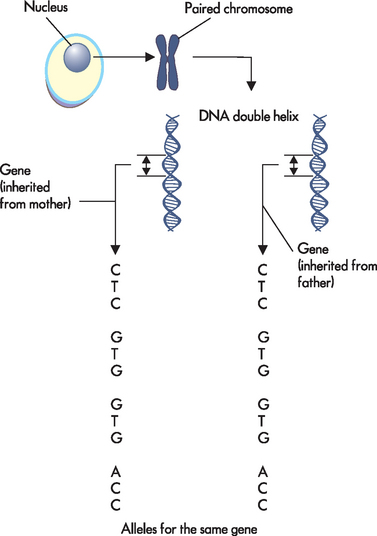
FIGURE 5-6 Within the nucleus, DNA is organised into chromosomes.
Genes are particular regions of chromosomes. When seen at the smallest level, genes consists of the bases A, C, G and T organised in particular orders known as codes. In this example, the alleles for the same genes that were inherited from both parents are identical (so the offspring is homozygous for that allele; see later in the chapter).
Changes in the DNA base sequence are known as mutations. Mutations can be caused by physical damage to DNA (such as breaking the strand), by adding or removing bases or by altering the chemical structure of the bases. The effects of mutations are unpredictable and highly variable. Some have no effect at all, but others have lethal consequences. Because DNA damage has potentially severe outcomes, the nucleus contains complicated systems that continually check and if necessary repair the DNA base sequence. Although these repair systems are very efficient, if the damage is extensive mutations may escape detection and repair. For example, prolonged exposure to the UV radiation in sunlight damages some bases; this can result in skin cancer. Australia has one of the highest incidences of skin cancer in the world: two-thirds of Australians will have been diagnosed with skin cancer by the time they reach 70 years of age.1
How are proteins produced in the cell?
DNA resides in the nucleus, but most proteins perform their various roles in the cell cytoplasm, or even outside the cell. In order for DNA to be able to direct the production of proteins, and hence the amount of protein function, the genetic information contained in the sequence of DNA bases must be transferred from the nucleus to the cytoplasm. This transfer of genetic information out of the nucleus is the function of RNA, where the genetic message (now in the RNA base sequence) then directs the production of the corresponding protein (see Figure 5-7). Depending on its biological role, the newly made protein may move freely within the cell, it may be directed to a particular cellular compartment or even to reside in the cell membrane, or it may be exported from the cell.
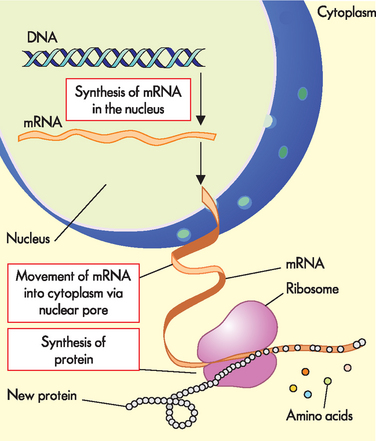
FIGURE 5-7 Production of proteins (protein synthesis).
Note that DNA remains in the nucleus, while mRNA transfers the information contained in one gene to the cytoplasm, where it directs the synthesis of a protein.
The production of proteins can be considered as a series of steps:
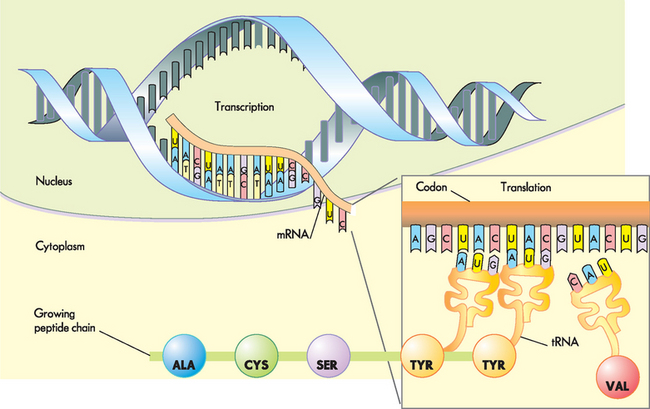
FIGURE 5-8 Protein synthesis: a closer view.
Note that each set of three bases specifies one particular amino acid. ALA= alanine; CYS = cysteine; SER = serine; TYR = tyrosine; VAL = valine.
Source: Based on Libby P et al. Braunwald’s heart disease: a textbook of cardiovascular medicine. 8th edn. Philadelphia: Saunders; 2008.
Although the genetic composition of all cells within one individual is identical, only a specific subset of genes is active in a particular cell type; the remaining genes are silent. This means that each cell produces only those proteins needed for its specific biological role. The nucleus responds to a wide range of signals to determine which genes are expressed, and therefore which proteins are produced, in any one cell at a particular time. This enables cells to change their activities in response to specific demands. For example, protein production increases during periods of active growth, and the production of specific proteins is required to fight inflammation and infection (see Chapters 13 and 14). Some silent genes become switched on at a particular stage of development; for example, genes switched on at puberty direct the production of proteins associated with sexual maturation.
INHERITANCE
As you are aware, we inherit a range of characteristics from our ancestors. Newborn babies are thoroughly inspected for family traits, leading to pronouncements such as ‘She has her father’s long legs … and her grandma’s eyes’. We now know that genes are the basic unit of inheritance and that both of our parents contribute to our genetic make-up. Therefore, we possess a mixture of traits, some of which can be seen in either side of the family and some which are uniquely our own.
Chromosomes in gametes (ova and sperm) are not paired, so gametes contain 23 different chromosomes: 22 autosomes and one sex chromosome. In the ovum, the sex chromosome is always an X chromosome, while sperm can contain either an X chromosome or a Y chromosome. At fertilisation, the sperm and ovum fuse to form an embryo, which contains two copies of each autosome and two sex chromosomes, XX in females and XY in males.
Gametes contain only one copy of each allele. When gametes form, the duplicate alleles possessed by each parent are randomly selected at each locus, so no two eggs or sperm will be identical. Thus, the egg actually contains only half the genetic material of the mother, because only one copy of each allele is included. Each egg that the mother produces has a different combination of alleles. The same process is true of each sperm produced by the father. This is why members of a family, who all share the same genetic ancestry, have some recognisable similarities yet are uniquely different. It also explains why sometimes siblings can be quite different in both appearance and personality — because the unique combination of half the genetic material from each parent could be quite different for each offspring.
If an individual receives two identical copies of an allele, one from each parent, they are described as being homozygous for that particular allele (homo meaning same). A simple example of this may be for eye colour. If the offspring receives an allele for brown eyes from the mother and an allele for brown eyes from the father, the offspring will be homozygous for the eye colour. If an individual receives a different allele from each parent, they are said to be heterozygous for the allele (hetero meaning different). Using the example of eye colour, if the offspring receives one allele for brown eyes and one allele for blue eyes they will be heterozygous, yet still have brown eyes (we explain why their eyes are brown, not blue, later in the chapter). Each individual cell contains tens of thousands of alleles, so an individual will be homozygous for some particular traits and heterozygous for others.
Genotype and phenotype
The genotype is the genetic composition of an individual, represented by the alleles that the individual possesses. The combination of alleles that each individual possesses results in that person being genetically unique. This is important to understand, because it provides reasons why we are all different despite being human. The combination also determines much about how we will turn out as individuals for traits such as height, musical ability and susceptibility to disease. Recent research has revealed more about how genes can influence the likelihood of our developing particular diseases, and, in the future, increased understanding of the genetic processes in diseases may even lead the way to improved treatment options (genetic diseases are discussed in Chapter 37). The genotype is fixed at conception and remains constant throughout life.
The phenotype comprises the characteristics and physical features displayed by the individual, which may change throughout life and may be affected by environment. For example, weight may be affected by diet, skin colour is affected by sun exposure, and diseases such as asthma and cancer may develop if an individual is exposed to particular environmental factors. This means that, while the phenotype is determined by the genotype, the genotype cannot be accurately predicted from the phenotype. The relationships between genetic information from chromosomes, through to genotype and phenotype, are shown in Figure 5-9.
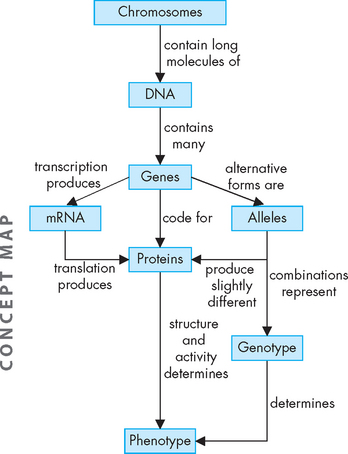
FIGURE 5-9 Chromosomes, DNA and genes from the code that result in the production of proteins.
Combinations of genetic factors result in the genotype, or genetic make-up of the person. The unique combinations of proteins are a main contributor to this individual’s phenotype, which results in the actual expression of individual characteristics.
Genetically identical twins arise from the union of one ovum and one sperm — one fertilised egg divides in the very early stages to develop into two embryos. Thus, identical twins have the same combination of alleles. They therefore have the same genotype, but lifestyle and environmental influences prevent them from having identical phenotypes. Compare this with fraternal (or non-identical) twins, which arise from two sets of ova (eggs) and sperm fusing at fertilisation and developing into embryos at the same time (in the one pregnancy). In this case, as the two embryos develop from different ova and sperm, the twins have different genotypes.
Predicting genotype: the Punnett square
Given the variability of gametes, it is not possible to predict the genotype of offspring of two particular individuals. However, we can predict the likelihood of an individual inheriting a particular trait using a simple technique known as the Punnett square. For example, what is the likelihood that a new baby will be a boy? Or a girl?
Remember that each parent has two sex chromosomes: the mother’s genotype is XX, while the father’s genotype is XY. This means that the mother can contribute either of her two X chromosomes to the baby, while the father can contribute either an X chromosome or a Y chromosome. We show this by writing the parental genotypes on the top and left side of the Punnet square as shown below (it doesn’t matter which parent goes where).
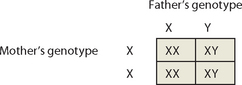
The Punnett square shows that, according to chance, 2 of the 4 children will be XX (female) and 2 of the 4 children will be XY (male), so the chance of having a boy or a girl is 50% (which you already knew!). It is important to note that this estimate assumes that X- and Y-containing sperm are equally likely to fertilise the ovum, and that both XX and XY embryos are equally viable. In fact, the number of male and female babies born in Australia is almost equal — in 2008, 296,600 births were registered in Australia and 51% of these were males.2 This is very near to the 50% split that we have just calculated using the Punnett square. Furthermore, although the theoretical likelihood of producing an offspring of any one sex is 50%, in reality this does not mean that the sexes will alternate — it is quite possible for a couple to have 4 children all of the same sex.
Interestingly, it is worth emphasising the fact that the only sex chromosome that the mother can pass to the offspring is an X chromosome. This means that the sex of the offspring is ultimately determined by whether the sperm that fertilises the egg contains the father’s X chromosome or his Y chromosome. In some cultures, the man requests that his wife produce him a son, yet it is only the male genes that can provide the Y chromosome necessary to produce a male offspring.
ABO blood groups
It is reasonably simple to provide a theoretical prediction for characteristics such as sex. Another example of genetic determination is that associated with blood groups. There are four blood groups and these have been designated the letters A, B, AB and O. They differ according to the presence or absence of sugar molecules on the surface of red blood cells (see Chapter 16). When a patient requires a blood transfusion, a sample of their blood is tested to determine the particular blood group, because incompatible blood administered to a patient can cause life-threatening immune reactions (see Chapter 15).
Compared to determining sex in offspring, determining blood groups is more complicated. The ABO blood groups are determined by three alleles on chromosome 9, designated a, b, and o. These alleles direct the production of proteins (enzymes) that are responsible for the production of surface antigens on red blood cells. Allele a results in the production of the A antigen (a protein on the surface of the cell that identifies the cell; see Chapter 12); allele b results in the production of the B antigen; and allele o does not cause antigen production. An individual can possess only two of the three possible alleles in any combination, producing blood groups A, B, AB and O as shown in Table 5-1.
Table 5-1 RELATIONSHIPS BETWEEN ABO BLOOD GROUPS ALLELES, RED BLOOD CELL ANTIGENS AND BLOOD GROUPS
| ALLELES | SURFACE ANTIGEN | BLOOD GROUP |
|---|---|---|
| oo | nil | O |
| aa or ao | A | A |
| bb or bo | B | B |
| ab | A and B | AB |
Note that individuals with aa or ao genotypes have the same phenotype (blood group A); similarly, both bb and bo gentotypes produce the blood group B phenotype.
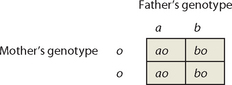
Punnett squares can also be used to predict the blood groups of offspring. Consider the case of a father with type AB blood and a mother with type O blood; their respective genotypes are ab and oo. The Punnett square below shows that their children are equally likely to have type A blood (ao) or type B blood (bo). Interestingly, none of the children will have the same blood group as either parent (type O or type AB).
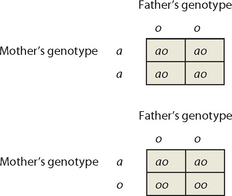
Now consider the case of a father with type O blood and a mother with type A blood. Can we state, with certainty, the likely blood groups of their offspring? In this case, we know the genotype of the father (oo) but we are not certain of the genotype of the mother (she could be aa or ao; refer to Table 5-1). If you construct Punnett squares, you will see that the blood groups of their children can be either A or O. If the mother has genotype aa, all offspring will have type A blood. However, if she has genotype ao, her offspring are equally likely to have type A or type O blood.
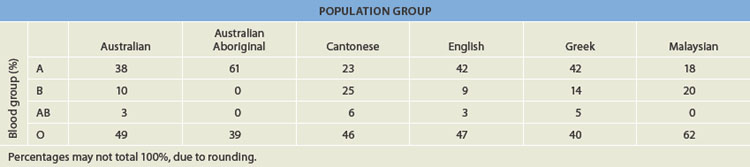
The frequency of the ABO blood groups varies between populations (see Table 5.2) because the distribution of a, b and o alleles in different ethnic groups is variable. In general, group O is common and group AB is rare. Group O (49%) and Group A (38%) are common in Australia,3 while Group B is more common among individuals of Asian descent (such as the Cantonese from China, or Malaysian people) than among individuals of European descent.4
Dominant and recessive genes
Gregor Mendel, an Austrian monk, worked with pea plants to find out how phenotypic characteristics such as flower colour were inherited. His findings apply to humans as well as to peas! Mendel showed that many genes have two alternative alleles: one allele of the gene (say, D) is dominant while the alternative (say, d) is recessive. The effect of d is observed only in the absence of D. Three combinations of alleles are possible: DD, dd and Dd:
If an individual is homozygous (has two copies) for the dominant form of the allele (DD), only the effect of allele D will be observed. If an individual is homozygous for the recessive form of the allele (dd), only the effect of allele d will be observed. If an individual is heterozygous (Dd), D dominates d so only the effect of allele D will be observed.In the example of eye colour used above, brown eyes are dominant, while blue eyes are recessive. Therefore, the offspring who is heterozygous having one brown allele and one blue allele will have brown eyes. The blood group alleles discussed earlier illustrate the patterns of inheritance observed for dominant and recessive genes. Alleles a and b are dominant, while o is recessive. If two recessive o alleles are present, no antigens are produced and the blood group is O. However, in the presence of alleles a or b, A or B antigens are produced, so the blood group is A or B, respectively; the presence of allele o has no effect. You will note that when both of the dominant alleles (a and b) are present, both A and B antigens are produced, so the blood group AB results. This indicates that alleles a and b are equally dominant, or codominant.
Many common physiological characteristics are inherited in Mendelian fashion: one allele is dominant, while other alleles are recessive. Recessive traits, such as pale hair, skin and eye colour, are observed only when two recessive alleles are present, for example:
You might find it interesting to use Punnett squares to track one of these characteristics within your own family. Can you determine whether individuals displaying dominant characteristics have two dominant alleles, or one dominant and one recessive allele?
Many inherited diseases follow the dominant/recessive pattern of inheritance. This means that the likelihood of offspring being affected can be calculated, if the genotype of the parents is known. This is explored further in Chapter 37.
Polygenetic inheritance refers to a particular characteristic that is represented by more than one gene, so that the genetic possibilities of the offspring are more complicated to predict. For example, there are multiple genes for skin colour, so the potential numbers of combinations of alleles from mother and father that are responsible for skin colour are quite high. The skin colour of the offspring could end up being one of any number of shades, so the genotype is determined by multiple genes; this is an example of polygenetic inheritance. When you then consider environmental influences such as amount of time in the sun and usage of sun protection, the ultimate phenotype of the individual may be influenced by many factors. The concept of polygenetic inheritance is discussed further in Chapter 37 in relation to the inheritance of genetic diseases.
NEWBORN SCREENING
Around the time of pregnancy and childbirth, parents and healthcare professionals become increasingly interested in the genetic possibilities for the offspring. This is perhaps the one time when the theory on genetics just discussed seems particularly relevant for most people within our community.
Each unique combination of ovum and sperm can result in genetic possibilities that may actually be detrimental for the offspring. While newborn babies may appear to be healthy, it is possible that some may have a genetic abnormality that can be detrimental. For some genetic conditions, early detection allows the condition to be managed more effectively. Blood testing of newborn babies for treatable disorders was introduced in Australia and New Zealand in the late 1960s.5 National newborn screening in Australia is performed by laboratories in the different states. Initially this testing was aimed to identify PKU (phenylketonuria), a disease that causes severe and irreversible mental retardation in untreated children. Although careful dietary management can prevent brain damage, a restricted diet must be introduced very soon after birth, so early detection is essential. Dr Robert Guthrie developed a test for PKU that requires a very small amount of blood, usually obtained by pricking the baby’s heel, and spotting the blood onto a specially prepared absorbent card (often known as a Guthrie card) that is sent to the laboratory for testing. This allows the genes stored within the nucleus of the blood cells to be assessed. Remember, the genes in blood cells contain genetic information for the whole body, not just the blood cells.
In recent years the Guthrie test has been expanded to test for more than 30 inherited disorders.6 All the disorders tested in newborn metabolic screening programs cause severe, often life-threatening disease and can be treated by dietary management or medication. A single heel-prick blood sample, ideally obtained 48–72 hours after birth, is used to provide three blood spots on a specially prepared card; lab results are available within 24 hours. Positive results are followed up by more detailed testing to confirm the diagnosis.
While each of the individual disorders is very rare, the importance of screening is highlighted by data from the South Australian Newborn Screening Centre, which indicate that one in every 800 babies screened has one of these treatable disorders.7 This study also investigated the efficiency of screening programs in South Australia and found that only 98% of newborn babies are screened — meaning that, on average, one baby with a treatable disorder will escape early detection programs in South Australia each year. If we assume that similar screening rates apply Australia-wide, this equates to seven affected babies per year. Nationally, only one in every 1000 babies is actually diagnosed with a condition through this testing process.8 This particular study from South Australia also found that babies less likely to be screened include those born at home, those born to an Aboriginal mother and those born to a mother from interstate. Special strategies may be needed to improve screening efficiency within these groups. It is also important that babies who die in utero or soon after birth are screened to detect inherited disorders, so that strategies can be put into place to ensure a better outcome in subsequent pregnancies.
Cell reproduction
Cellular reproduction in body tissues involves mitosis (nuclear division) and cytokinesis (cytoplasmic division). Only mature cells are capable of division. Maturation occurs during a stage of cellular life called the interphase (the growth phase). The cell cycle is the reproductive process that begins after the interphase in all tissues with cellular turnover. There are four phases of the cell cycle: G1 phase, S phase, G2 phase and M phase.Genes
Genetic information is organised as a series of genes positioned at specific loci on the DNA molecule. Messenger RNA carries the genetic message from the nucleus, where genes reside, to the cytoplasm, where proteins are produced. The cell nucleus determines the patterns of gene expression within a specific cell at a particular point in time.Two days ago, Miriam, who is 32 years old, gave birth to her first child, Beth, at home. The pregnancy was carefully planned and Miriam took great care to ensure a healthy pregnancy. Her diet was well balanced and she minimised chemical usage in her home. She stopped work quite early in her pregnancy (24 weeks gestation) because she believes that a calm, happy mother is essential for a calm, happy baby. However, she maintained a moderate exercise program (walking and swimming) and is quite fit. The birth was uncomplicated and Beth is contented. The midwife has requested Miriam’s permission to perform a heel-prick test to collect a blood sample from Beth for metabolic screening. Miriam is reluctant to agree to this testing, as she believes that it will upset her baby and is not necessary, given that she did ‘all the right things’ throughout her pregnancy.