Understanding Quantitative Research Design
A research design is the blueprint for conducting a study. It maximizes your control over factors that could interfere with the validity of the findings. The research design guides the researcher in planning and implementing the study in a way that is most likely to achieve the intended goal. This control increases the probability that the study results are accurate reflections of reality. Skill in selecting and implementing a research design can improve the quality of the study and thus the usefulness of the findings. A strong design makes it more likely that the study will contribute to the evidence base for practice. Being able to identify the study design and to evaluate design flaws that might threaten the validity of findings is an important part of critically analyzing studies.
The term research design is used in two ways. Some consider research design to be the entire strategy for the study, from identification of the problem to final plans for data collection. Others limit design to clearly defined structures within which the study is implemented. In this text, the first definition refers to the research methodology and the second is a definition of the research design.
The design of a study is the end result of a series of decisions you will make concerning how best to implement your study. The design is closely associated with the framework of the study. As a blueprint, the design is not specific to a particular study but rather is a broad pattern or guide that can be applied to many studies. Just as the blueprint for a house must be individualized to the house being built, so the design must be made specific to a study. Using the problem statement, framework, research questions, and clearly defined variables, you can map out the design to achieve a detailed research plan for collecting and analyzing data. Your research plan specifically directs the execution of your study. Developing a research plan is discussed in Chapter 17.
Elements central to the study design include the presence or absence of a treatment, the number of groups in the sample, the number and timing of measurements, the sampling method, the time frame for data collection, planned comparisons, and the control of extraneous variables. Finding answers to the following questions will help you to develop the design:
1. Is the primary purpose of the study to describe variables and groups within the study situation, to examine relationships, or to examine causality within the study situation?
3. If so, will the researcher control the treatment?
4. Will the sample be pretested before the treatment?
5. Will the sample be randomly selected?
6. Will the sample be studied as a single group or divided into groups?
7. How many groups will there be?
8. What will be the size of each group?
9. Will there be a control group?
10. Will groups be randomly assigned?
11. Will the variables be measured more than once?
12. Will the data be collected cross-sectionally or over time?
13. Have extraneous variables been identified?
14. Are data being collected on extraneous variables?
15. What strategies are being used to control for extraneous variables?
16. What strategies are being used to compare variables or groups?
17. Will data be collected at a single site or at multiple sites?
Developing a study design requires the researcher to consider multiple details such as those listed. The more carefully thought out these details are, the stronger the design. These questions are important because they connect to the logic on which research design is based. To give you the information necessary to understand and answer these questions, this chapter discusses (1) the concepts important to design, (2) design validity, (3) the elements of a good design, and (4) triangulation, a relatively recent approach to research design.
EVIDENCE BASE AND DESIGN
Only the most carefully thought through designs can contribute significantly to the evidence base. By incorporating the elements discussed in this chapter into your design, you will develop a study that is strong enough to be included in the evidence base.
Concepts Important to Design
Many terms used in discussing research design have special meanings within this context. An understanding of these concepts is critical for recognizing the purpose of a specific design. Some of the major concepts used in relation to design are causality, bias, manipulation, control, and validity.
Causality
The first assumption you must make in examining causality is that causes lead to effects. Some of the ideas related to causation emerged from the logical positivist philosophical tradition. Hume, a positivist, proposed that the following three conditions must be met to establish causality: (1) there must be a strong correlation between the proposed cause and the effect, (2) the proposed cause must precede the effect in time, and (3) the cause has to be present whenever the effect occurs. Cause, according to Hume, is not directly observable but must be inferred.
A philosophical group known as essentialists proposed that two concepts must be considered in determining causality: necessary and sufficient. The proposed cause must be necessary for the effect to occur. (The effect cannot occur unless the cause first occurs.) The proposed cause must also be sufficient (requiring no other factors) for the effect to occur. This leaves no room for a variable that may sometimes, but not always, serve as the cause of an effect.
John Stuart Mill, another philosopher, added a third idea related to causation. He suggested that, in addition to the preceding criteria for causation, there must be no alternative explanations for why a change in one variable seems to lead to a change in a second variable.
Causes are frequently expressed within the propositions of a theory. Testing the accuracy of these theoretical statements indicates the usefulness of the theory. A theoretical understanding of causation is considered important because it improves our ability to predict and, in some cases, to control events in the real world. The purpose of an experimental design is to examine cause and effect. The independent variable in a study is expected to be the cause, and the dependent variable is expected to reflect the effect of the independent variable.
Multicausality
Multicausality, the recognition that a number of interrelating variables can be involved in causing a particular effect, is a more recent idea related to causality. Because of the complexity of causal relationships, a theory is unlikely to identify every variable involved in causing a particular phenomenon. A study is unlikely to include every component influencing a particular change or effect.
Cook and Campbell (1979) have suggested three levels of causal assertions that one must consider in establishing causality. Molar causal laws relate to large and complex objects. Intermediate mediation considers causal factors operating between molar and micro levels. Micromediation examines causal connections at the level of small particles, such as atoms. Cook and Campbell (1979) used the example of turning on a light switch, which causes the light to come on (molar). An electrician would tend to explain the cause of the light coming on in terms of wires and electrical current (intermediate mediation). However, the physicist would explain the cause of the light coming on in terms of ions, atoms, and subparticles (micromediation).
The essentialists’ ideas of necessary and sufficient do not hold up well when one views a phenomenon from the perspective of multiple causation. The light switch may not be necessary to turn on the light if the insulation has worn off the electrical wires. Additionally, even though the switch is turned on, the light will not come on if the light bulb is burned out. Although this is a concrete example, it is easy to relate it to common situations in nursing.
Few phenomena in nursing can be clearly reduced to a single cause and a single effect. However, the greater the proportion of causal factors that can be identified and explored, the clearer the understanding of the phenomenon. This greater understanding improves our ability to predict and control. For example, currently nurses have only a limited understanding of patients’ preoperative attitudes, knowledge, and behaviors and their effects on postoperative attitudes and behaviors. Nurses assume that high preoperative anxiety leads to less healthy postoperative responses and that providing information before surgery improves healthy responses in the postoperative period. Many nursing studies have examined this particular phenomenon. However, the causal factors involved are complex and have not been clearly delineated. The evidence base in this area is lacking.
Probability
The original criteria for causation required that a variable should cause an identified effect each time the cause occurred. Although this criterion may apply in the basic sciences, such as chemistry or physics, it is unlikely to apply in the health sciences or social sciences. Because of the complexity of the nursing field, nurses deal in probabilities. Probability addresses relative, rather than absolute, causality. From the perspective of probability, a cause will not produce a specific effect each time that particular cause occurs.
Reasoning changes when one thinks in terms of probabilities. The researcher investigates the probability that an effect will occur under specific circumstances. Rather than seeking to prove that A causes B, a researcher would state that if A occurs, there is a 50% probability that B will occur. The reasoning behind probability is more in keeping with the complexity of multicausality. In the example about preoperative attitudes and postoperative outcomes, nurses could seek to predict the probability of unhealthy postoperative patient outcomes when preoperative anxiety levels are high.
Causality and Nursing Philosophy
Traditional theories of prediction and control are built on theories of causality. The first research designs were also based on causality theory. Nursing science must be built within a philosophical framework of multicausality and probability. The strict senses of single causality and of “necessary and sufficient” are not in keeping with the progressively complex, holistic philosophy of nursing. To understand multicausality and increase the probability of being able to predict and control the occurrence of an effect, the researcher must comprehend both wholes and parts.
Practicing nurses must be aware of the molar, intermediate mediational, and micromediational aspects of a particular phenomenon. A variety of differing approaches, reflecting both qualitative and quantitative, descriptive and experimental research, are necessary to develop a knowledge base for nursing. Some see explanation and causality as different and perhaps opposing forms of knowledge. Nevertheless, the nurse must join these forms of knowledge, sometimes within the design of a single study, to acquire the knowledge needed for nursing practice.
Bias
The term bias means to slant away from the true or expected. A biased opinion has failed to include both sides of the question. Cutting fabric on the bias means to cut across the grain of the woven fabric. A biased witness is one who is strongly for or against one side of the situation. A biased scale is one that does not provide a valid measure.
Bias is of great concern in research because of the potential effect on the meaning of the study findings. Any component of the study that deviates or causes a deviation from true measure leads to distorted findings. Many factors related to research can be biased: the researcher, the measurement tools, the individual subjects, the sample, the data, and the statistics. Thus, an important concern in designing a study is to identify possible sources of bias and eliminate or avoid them. If they cannot be avoided, you must design your study to control these sources of bias. Designs, in fact, are developed to reduce the possibilities of bias.
Manipulation
Manipulation tends to have a negative connotation and is associated with one person underhandedly maneuvering a second person so that he or she behaves or thinks in the way the first person desires. Denotatively, to manipulate means to move around or to control the movement of something, such as manipulating a syringe. However, nurses manipulate events or the environment to benefit the patient. Manipulation has a specific meaning when used in experimental or quasi-experimental research; the manipulation is the treatment. For example, in a study on preoperative care, preoperative teaching might be manipulated so that one group receives the treatment and another does not. In a study on oral care, the frequency of care might be manipulated.
In nursing research, when experimental designs are used to explore causal relationships, the nurse must be free to manipulate the variables under study. For example, in a study of pain management, if the freedom to manipulate pain control measures is under the control of someone else, a bias is introduced into the study. In qualitative, descriptive, and correlational studies, the researcher does not attempt to manipulate variables. Instead, the purpose is to describe a situation as it exists.
Control
Control means having the power to direct or manipulate factors to achieve a desired outcome. In a study of pain management, one must be able to control interventions to relieve pain. The idea of control is important in research, particularly in experimental and quasi-experimental studies. The more control the researcher has over the features of the study, the more credible the study findings. The purpose of research designs is to maximize control factors in the study.
Study Validity
Study validity, a measure of the truth or accuracy of a claim, is an important concern throughout the research process. Study validity is central to building an evidence base. Questions of validity refer back to the propositions from which the study was developed and address their approximate truth or falsity. Is the theoretical proposition an accurate reflection of reality? Was the study designed well enough to provide a valid test of the proposition? Validity is a complex idea that is important to the researcher and to those who read the study report and consider using the findings in their practice. Critical analysis of research requires that we think through threats to validity and make judgments about how seriously these threats affect the integrity of the findings. Validity provides a major basis for making decisions about which findings are sufficiently valid to add to the evidence base for patient care.
Cook and Campbell (1979) have described four types of validity: statistical conclusion validity, internal validity, construct validity, and external validity. When conducting a study, you will be confronted with major decisions about the four types of validity. To make these decisions, you must address a variety of questions, such as the following:
1. Is there a relationship between the two variables? (statistical conclusion validity)
2. Given that there is a relationship, is it plausibly causal from one operational variable to the other, or would the same relationship have been obtained in the absence of any treatment of any kind? (internal validity)
3. Given that the relationship is plausibly causal and is reasonably known to be from one variable to another, what are the particular cause-and-effect constructs involved in the relationship? (construct validity)
4. Given that there is probably a causal relationship from construct A to construct B, how generalizable is this relationship across persons, settings, and times? (external validity) (Cook & Campbell, 1979, p. 39)
Statistical Conclusion Validity
The first step in inferring cause is to determine whether the independent and dependent variables are related. You can determine this relationship (covariation) through statistical analysis. Statistical conclusion validity is concerned with whether the conclusions about relationships or differences drawn from statistical analysis are an accurate reflection of the real world.
The second step is to identify differences between groups. There are reasons why false conclusions can be drawn about the presence or absence of a relationship or difference. The reasons for the false conclusions are called threats to statistical conclusion validity. These threats are described here.
Low Statistical Power: Low statistical power increases the probability of concluding that there is no significant difference between samples when actually there is a difference (type II error). A type II error is most likely to occur when the sample size is small or when the power of the statistical test to determine differences is low. The concept of statistical power and strategies to improve it are discussed in Chapters 14 and 18.
Violated Assumptions of Statistical Tests: Most statistical tests have assumptions about the data being used, such as that the data are interval data, that the sample was randomly obtained, or that there is a normal distribution of scores to be analyzed. If these assumptions are violated, the statistical analysis may provide inaccurate results. The assumptions of each statistical test are provided in Chapters 20, 21, and 22.
Fishing and the Error Rate Problem: A serious concern in research is incorrectly concluding that a relationship or difference exists when it does not (type I error). The risk of type I error increases when the researcher conducts multiple statistical analyses of relationships or differences; this procedure is referred to as fishing. When fishing is used, a given portion of the analyses shows significant relationships or differences simply by chance. For example, the t-test is commonly used to make multiple statistical comparisons of mean differences in a single sample. This procedure increases the risk of a type I error because some of the differences found in the sample occurred by chance and are not actually present in the population. Multivariate statistical techniques have been developed to deal with this error rate problem (Goodwin, 1984). Fishing and error rate problems are discussed in Chapter 18.
Reliability of Measures: The technique of measuring variables must be reliable to reveal true differences. A measure is a reliable measure if it gives the same result each time the same situation or factor is measured. For example, a thermometer would be precise if it showed the same reading when tested repeatedly on the same patient. If a scale is used to measure anxiety, it should give the same score (be reliable) if repeatedly given to the same person in a short time (unless, of course, repeatedly taking the same test causes anxiety to increase or decrease).
Reliability of Treatment Implementation: Treatment standardization ensures that the research treatment is applied consistently each time the treatment is administered. If the method of administering a research treatment varies from one person to another, the chance of detecting a true difference decreases. To control for this lack of standardization, during the planning phase the researcher must ensure that the treatment will be provided in exactly the same way each time it is administered.
Random Irrelevancies in the Experimental Setting: Environmental extraneous variables in complex field settings (e.g., a clinical unit) can influence scores on the dependent variable. These variables increase the difficulty of detecting differences. Consider the activities occurring on a nursing unit. The numbers and variety of staff, patients, crises, and work patterns merge into a complex arena for the implementation of a study. Any of the dynamics of the unit can influence manipulation of the independent variable or measurement of the dependent variable.
Random Heterogeneity of Respondents: Subjects in a treatment group can differ in ways that correlate with the dependent variable. This is referred to as random heterogeneity. This difference can influence the outcome of the treatment and prevent detection of a true relationship between the treatment and the dependent variable. For example, subjects may have a variety of responses to preoperative attempts to lower anxiety because of unique characteristics associated with differing levels of anxiety.
Internal Validity
Internal validity is the extent to which the effects detected in the study are a true reflection of reality rather than the result of extraneous variables. Although internal validity should be a concern in all studies, it is addressed more commonly in relation to studies examining causality than in other studies. When examining causality, the researcher must determine whether the independent and dependent variables may have been caused by a third, often unmeasured, variable (an extraneous variable). The possibility of an alternative explanation of cause is sometimes referred to as a rival hypothesis. Any study can contain threats to internal validity, and these validity threats can lead to a false-positive or false-negative conclusion. The researcher must ask, “Is there another reasonable (valid) explanation (rival hypothesis) for the finding other than the one I have proposed?” Threats to internal validity are described here.
History: History is an event that is not related to the planned study but that occurs during the time of the study. History could influence a subject’s response to the treatment.
Maturation: In research, maturation is defined as growing older, wiser, stronger, hungrier, more tired, or more experienced during the study. Such unplanned and unrecognized changes can influence the findings of the study.
Testing: Sometimes, the effect being measured (testing) can be due to the number of times the subject’s responses have been tested. The subject may remember earlier, inaccurate responses and then modify them, thus altering the outcome of the study. The test itself may influence the subject to change attitudes or may increase the subject’s knowledge.
Instrumentation: Effects can be due to changes in measurement instruments (instrumentation) between the pretest and the posttest rather than a result of the treatment. For example, a scale that was accurate when the study began (pretest) could now show subjects to weigh 2 lbs less than they actually weigh (posttest). Instrumentation is also involved when people serving as observers or data collectors become more experienced between the pretest and the posttest, thus altering in some way the data they collect.
Statistical Regression: Statistical regression is the movement or regression of extreme scores toward the mean in studies using a pretest-posttest design. The process involved in statistical regression is difficult to understand. When a test or scale is used to measure a variable, some subjects achieve very high or very low scores. In some studies, subjects are selected to be included in a particular group because their scores on a pretest are high or low. A treatment is then performed, and a posttest is administered. However, even with no treatment, subjects who initially achieve very high or very low scores tend to have more moderate scores when retested. Their scores regress toward the mean. Thus, the treatment did not necessarily cause the change. If the pretest scores were low, the posttest may show statistically significant differences (higher scores) from the pretest, leading to the conclusion that the treatment caused the change (type I error). If the pretest scores were high, the posttest scores would tend to be lower (because of a tendency to regress toward the mean) even with no treatment. In this situation, the researcher may mistakenly conclude that the treatment did not cause a change (type II error).
Selection: Selection addresses the process by which subjects are chosen to take part in a study and how subjects are grouped within a study. A selection threat is more likely to occur in studies in which randomization is not possible. In some studies, people selected for the study may differ in some important way from people not selected for the study. In other studies, the threat is due to differences in subjects selected for study groups. For example, people assigned to the control group could be different in some important way from people assigned to the experimental group. This difference in selection could cause the two groups to react differently to the treatment; in this case, the treatment would not have caused the differences in group responses.
Mortality: The mortality threat is due to subjects who drop out of a study before completion. Mortality becomes a threat when (1) those who drop out of a study are a different type of person from those who remain in the study or (2) there is a difference between the kinds of people who drop out of the experimental group and the people who drop out of the control group.
Interactions with Selection: The aforementioned threats can interact with selection to further complicate the validity of the study. The threats most likely to interact with selection are history, maturation, and instrumentation. For example, if the control group you selected for your study has a different history from that of the experimental group, responses to the treatment may be due to this interaction rather than to the treatment.
Ambiguity about the Direction of Causal Influence: Ambiguity about the direction of a causal influence occurs most frequently in correlational studies that address causality. In a study in which variables are measured simultaneously and only once, it may be impossible to determine whether A caused B, B caused A, or the two variables interact in a noncausal way.
Diffusion or Imitation of Treatments: The control group may gain access to the treatment intended for the experimental group (diffusion) or a similar treatment available from another source (imitation). For example, suppose your study examined the effect of teaching specific information to hypertensive patients as a treatment and then measured the effect of the teaching on blood pressure readings and adherence to treatment protocols. Suppose that the control group patients shared the teaching information with the experimental patients (treatment diffusion). This sharing changed the behavior of the control group. The control group patients’ responses to the outcome measures may show no differences from those of the experimental group even though the teaching actually did make a difference (type II error).
Compensatory Equalization of Treatments: When the experimental group receives a treatment seen as desirable, such as a new treatment for acquired immunodeficiency syndrome, administrative people and other health professionals may not tolerate the difference and may insist that the control group also receive the treatment. The researcher therefore no longer has a control group and cannot document the effectiveness of the treatment through the study. In health care, both giving and withholding treatments have ethical implications.
Compensatory Rivalry by Respondents Receiving Less Desirable Treatments: For some studies, the design and plan of the study are publicly known. The control group subjects then know the expected difference between their group and the experimental group and may attempt to reduce or reverse the difference. This phenomenon may have occurred in the national hospice study funded by the Health Care Financing Administration (now CMS [Centers for Medicare/Medicaid Studies]) and conducted by Brown University (Greer, Mor, Sherwood, Morris, & Birnbaum, 1983). In this study, 26 hospices were temporarily reimbursed through Medicare while researchers compared the care given at hospices with that given at hospitals. The study made national headlines and was widely discussed in Congress. Health policy decisions related to the reimbursement of hospice care hinged on the findings of the study. The study found no significant differences in care between the two groups, although there were cost differentials. In addition to a selection threat (hospitals providing poor care to dying cancer patients were unlikely to agree to participate in the study), health care professionals in the hospitals selected may have been determined to counter the criticism that the care they provided was poor. This rivalry could have influenced the outcomes of the study and thus threatened its validity.
Resentful Demoralization of Respondents Receiving Less Desirable Treatments: If control group subjects believe that they are receiving less desirable treatment, they may withdraw, give up, or become angry. Changes in behavior resulting from this reaction rather than from the treatment can lead to differences that cannot be attributed to the treatment.
Construct Validity
Construct validity examines the fit between the conceptual definitions and operational definitions of variables. Theoretical constructs or concepts are defined within the framework (conceptual definitions). These conceptual definitions provide the basis for the operational definitions of the variables. Operational definitions (methods of measurement) must validly reflect the theoretical constructs. (Theoretical constructs were discussed in Chapter 7; conceptual and operational definitions of concepts and variables were discussed in Chapter 8.)
Is use of the measure a valid inference about the construct? By examining construct validity, we can determine whether the instrument actually measures the theoretical construct it purports to measure. The process of developing construct validity for an instrument often requires years of scientific work. When selecting methods of measurement, the researcher must determine the previous development of instrument construct validity. (Instrument construct validity is discussed in Chapter 15.) The threats to construct validity are related both to previous instrument development and to the development of measurement techniques as part of the methodology of a particular study. Threats to construct validity are described here.
Inadequate Preoperational Clarification of Constructs: Measurement of a construct stems logically from a concept analysis of the construct, either by the theorist who developed the construct or by the researcher. The conceptual definition should emerge from the concept analysis, and the method of measurement (operational definition) should clearly reflect both. A deficiency in the conceptual or operational definition leads to low construct validity. See Importance of a Conceptual Definition: An Example, in Chapter 7, which discusses the conceptual definition of caring.
Mono-Operation Bias: Mono-operation bias occurs when only one method of measurement is used to assess a construct. When only one method of measurement is used, fewer dimensions of the construct are measured. Construct validity greatly improves if the researcher uses more than one instrument. For example, if anxiety were a dependent variable, more than one measure of anxiety could be used. It is often possible to apply more than one measurement of the dependent variable with little increase in time, effort, or cost.
Monomethod Bias: In monomethod bias, the researcher uses more than one measure of a variable, but all the measures use the same method of recording. Attitude measures, for example, may all be paper and pencil scales. Attitudes that are personal and private, however, may not be detected through the use of paper and pencil tools. Paper and pencil tools may be influenced by feelings of nonaccountability for responses, acquiescence, or social desirability. For example, construct validity would improve if anxiety were measured by a paper and pencil test, verbal messages of anxiety, the galvanic skin response, and the observer’s recording of incidence and frequency of behaviors that have been validly linked with anxiety.
Hypothesis Guessing within Experimental Conditions: Hypothesis guessing occurs when subjects within a study guess the hypotheses of the researcher. The validity concern relates to behavioral changes that may occur in the subjects as a consequence of knowing the hypothesis. The extent to which this issue modifies study findings is not currently known.
Evaluation Apprehension: Subjects want researchers to see them in a favorable light. They want to be seen as competent and psychologically healthy. Evaluation apprehension occurs when the subject’s responses in the experiment are due to this desire rather than the effects of the independent variable.
Experimenter Expectancies (Rosenthal Effect): The expectancies of the researcher can bias the data. For example, experimenter expectancy occurs if a researcher expects a particular intervention to relieve pain. The data he or she collects may be biased to reflect this expectation. If another researcher who does not believe the intervention would be effective had collected the data, results could have been different. The extent to which this effect actually influences studies is not known. Because of their concern about experimenter expectancy, some researchers are not involved in the data collection process. In other studies, data collectors do not know which subjects are assigned to treatment and control groups.
Another way to control this threat is to design the study so that the various data collectors have different expectations. If the sample size is large enough, the researcher could compare data gathered by the different data collectors. Failing to determine a difference in the data collected by the two groups would give evidence that the construct is valid.
Confounding Constructs and Levels of Constructs: When developing the methodology of a study, you must decide about the intensity of the variable that will be measured or provided as a treatment. This intensity influences the level of the construct that will be reflected in the study. These decisions can affect validity, because the method of measuring the variable influences the outcome of the study and the understanding of the constructs in the study framework.
For example, in reviewing your research, you might find that variable A does not affect variable B when, in fact, it does, but either not at the level of A that was manipulated or not at the level of B that was measured. This issue is a particular problem when A is not linearly related to B or when the effect being studied is weak. To control this threat, you will need to include several levels of A in the design and will have to measure many levels of B. For example, in a study in which A is preoperative teaching and B is anxiety, (1) the instrument being used to measure anxiety measures only high levels of anxiety or (2) the preoperative teaching is provided for 15 minutes but 30 minutes or an hour of teaching is required to cause significant changes in anxiety.
In some cases, there is confounding of variables, which leads to mistaken conclusions. Few measures of a construct are pure measures. Rather, a selected method of measuring a construct can measure a portion of the construct as well as other related constructs. Thus, the measure can lead to confusing results, because the variable measured does not accurately reflect the construct.
Interaction of Different Treatments: The interaction of different treatments is a threat to construct validity if subjects receive more than one treatment in a study. For example, your study might examine the effectiveness of pain relief measures, and subjects might receive medication, massage, distraction, and relaxation strategies. In this case, each one of the treatments interacts with the others, and the effect of any single treatment on pain relief would be impossible to extract. Your study findings could not be generalized to any situation in which patients did not receive all four pain treatments.
Interaction of Testing and Treatment: In some studies, pretesting the subject is thought to modify the effect of the treatment. In this case, the findings can be generalized only to subjects who have been pretested. Although there is some evidence that pretest sensitivity does not have the impact that was once feared, it must be considered in examining the validity of the study. The Solomon Four-Group Design (discussed in Chapter 11) tests this threat to validity. Repeated posttests can also lead to an interaction of testing and treatment.
Restricted Generalizability Across Constructs: When designing studies, the researcher must consider the impact of the findings on constructs other than those originally conceived in the problem statement. Often, including another measure or two will enable you to generalize the findings to clinical settings, and the translation back to theoretical dimensions will be broader.
External Validity
External validity is concerned with the extent to which study findings can be generalized beyond the sample used in the study. With the most serious threat, the findings would be meaningful only for the group being studied. To some extent, the significance of the study depends on the number of types of people and situations to which the findings can be applied. Sometimes, the factors influencing external validity are subtle and may not be reported in research papers; however, the researcher must be responsible for these factors. Generalization is usually more narrow for a single study than for multiple replications of a study using different samples, perhaps from different populations in different settings. The threats to the ability to generalize the findings (external validity) in terms of study design are described here.
Interaction of Selection and Treatment: Seeking subjects who are willing to participate in a study can be difficult, particularly if the study requires extensive amounts of time or other investments by subjects. If a large number of the persons approached to participate in a study decline to participate, the sample actually selected will be limited in ways that might not be evident at first glance. Only the researcher knows the subjects well. Subjects might be volunteers, “do-gooders,” or those with nothing better to do. In this case, generalizing the findings to all members of a population, such as all nurses, all hospitalized patients, or all persons experiencing diabetes, is not easy to justify.
The study must be planned to limit the investment demands on subjects and thereby improve participation. The researcher must report the number of persons who were approached and refused to participate in the study so that those who are examining the study can judge any threats to external validity. As the percentage of those who decline to participate increases, external validity decreases. Sufficient data must be collected on the subjects to allow the researcher to be familiar with the characteristics of subjects and, to the extent possible, the characteristics of those who decline to participate. Handwritten notes of verbal remarks made by those who decline and observations of behavior, dress, or other significant factors can be useful in determining selection differences.
Interaction of Setting and Treatment: Bias exists in types of settings and organizations that agree to participate in studies. This bias has been particularly evident in nursing studies. For example, some hospitals welcome nursing studies and encourage employed nurses to conduct studies. Others are resistant to the conduct of nursing research. These two types of hospitals may be different in important ways; thus, there might be an interaction of setting and treatment that limits the generalizability of the findings. As a researcher, you must consider this factor when making statements about the population to which your findings can be generalized.
Interaction of History and Treatment: The circumstances in which a study was conducted (history) influence the treatment and thus the generalizability of the findings. Logically, one can never generalize to the future; however, replicating the study during various periods strengthens the usefulness of findings over time. In critically analyzing studies, you must always consider the period of history during which the study was conducted and the effect of nursing practice and societal events during that period on the reported findings.
Elements of a Good Design
The purpose of design is to set up a situation that maximizes the possibilities of obtaining accurate responses to objectives, questions, or hypotheses. Select a design that is (1) appropriate to the purpose of the study, (2) feasible given realistic constraints, and (3) effective in reducing threats to validity. In most studies, comparisons are the basis of obtaining valid answers. A good design provides the subjects, the setting, and the protocol within which those comparisons can be clearly examined. The comparisons may focus on differences or relationships or both. The study may require that comparisons be made between or among individuals, groups, or variables. A comparison may also be made of measures taken before a treatment (pretest) and measures taken after a treatment (posttest). After these comparisons have been made, you can compare the sample values with statistical tables reflecting population values. In some cases, the study may involve comparing group values with population values.
Designs were developed to reduce threats that might invalidate the comparisons. However, some designs are more effective in reducing threats than others. It may be necessary to modify the design to reduce a particular threat. Before selecting a design, you must identify the threats that are most likely to invalidate your study.
Strategies for reducing threats to validity are sometimes addressed in terms of control. Selecting a design involves decisions related to control of the environment, sample, treatment, and measurement. Increasing control (to reduce threats to validity) will require you to carefully think through every facet of your design. An excellent description of one research team’s efforts to develop a good design and control threats to validity is McGuire et al.’s (2000) study, “Maintaining Study Validity in a Changing Clinical Environment.” (This paper is available in full text on CINAHL.)
Controlling the Environment
The study environment has a major effect on research outcomes. An uncontrolled environment introduces many extraneous variables into the study situation. Therefore, the study design may include strategies for controlling that environment. In many studies, it is important that the environment be consistent for all subjects. Elements in the environment that may influence the application of a treatment or the measurement of variables must be identified and, when possible, controlled.
Controlling Equivalence of Subjects and Groups
When comparisons are made, it is assumed that the individual units of the comparison are relatively equivalent except for the variables being measured. The researcher does not want to be comparing “apples and oranges.” To establish equivalence, the researcher defines sampling criteria. Deviation from this equivalence is a threat to validity. Deviation occurs when sampling criteria have not been adequately defined or when unidentified extraneous variables increase variation in the group.
The most effective strategy for achieving equivalence is random sampling followed by random assignment to groups. However, this strategy does not guarantee equivalence. Even when randomization has been used, the researcher must examine the extent of equivalence by measuring and comparing characteristics for which the groups must be equivalent. This comparison is usually reported in the description of the sample.
Contrary to the aforementioned need for equivalence, groups must be as different as possible in relation to the research variables. Small differences or relationships are more difficult to distinguish than large differences. These differences are often addressed in terms of effect size. Although sample size plays an important role, effect size is maximized by a good design. Effect size is greatest when variance within groups is small.
Control Groups: If the study involves an experimental treatment, the design usually calls for a comparison: Outcome measures for individuals who receive the experimental treatment are compared with outcome measures for those who do not receive the experimental treatment. This comparison requires a control group, subjects who do not receive the experimental treatment.
One threat to validity is the lack of equivalence between the experimental and control groups. This threat is best controlled by random assignment to groups. Another strategy is for the subjects to serve as their own controls. With this design strategy, pretest and posttest measures are taken of the subjects in the absence of a treatment, as well as before and after the treatment. In this case, the timing of measures must be comparable between control and treatment conditions.
Controlling the Treatment
In a well-designed experimental study, the researcher has complete control of any treatment provided. The first step in achieving control is to make a detailed description of the treatment. The next step is to use strategies to ensure consistency in implementing the treatment. Consistency may involve elements of the treatment such as equipment, time, intensity, sequencing, and staff skill.
Variations in the treatment reduce the effect size. It is likely that subjects who receive fewer optimal applications of the treatment will have a smaller response, resulting in more variance in posttest measures for the experimental group. To avoid this problem, the treatment is administered to each subject in exactly the same way. This consideration requires the researcher to think carefully through every element of the treatment to reduce variation wherever possible.
For example, if information is being provided as part of the treatment, some researchers videotape the information, present it to each subject in the same environment, and attempt to decrease variation in the subject’s experience before and during the viewing of the videotape. Variations include elements such as time of day, mood, anxiety, experience of pain, interactions with others, and amount of time spent waiting.
In many nursing studies, the researcher does not have complete control of the treatment. It may be costly to control the treatment carefully, it may be difficult to persuade staff to be consistent in the treatment, or the time required to implement a carefully controlled treatment may seem prohibitive. In some cases, the researcher may be studying causal outcomes of an event occurring naturally in the environment.
Regardless of the reason for the researcher’s decision, internal validity is reduced when the treatment is inconsistently applied. The risk of a type II error is higher owing to greater variance and a smaller effect size. Thus, studies with uncontrolled treatments need larger samples to reduce the risk of a type II error. External validity may improve if the treatment is studied as it typically occurs clinically. If the study does not reveal a statistically significant difference, then perhaps the typical clinical application of the treatment does not have an important effect on patient outcomes. The question then becomes whether a difference might have been found if the treatment had been consistently applied.
Counterbalancing: In some studies, each subject receives several different treatments sequentially (e.g., relaxation, distraction, and visual imagery) or various levels of the same treatment (e.g., different doses of a drug or varying lengths of relaxation time). Sometimes the application of one treatment can influence the response to later treatments, a phenomenon referred to as a carryover effect. If a carryover effect is known to occur, it is not advisable for a researcher to use this design strategy for the study. However, even when no carryover effect is known, the researcher may take precautions against the possibility that this effect will influence outcomes. In one such precaution, known as counterbalancing, the various treatments are administered in random order rather than being provided consistently in the same sequence.
Controlling Measurement
Measurements play a key role in the validity of a study. Measures must have documented validity and reliability. When measurement is crude or inconsistent, variance within groups is high, and it is more difficult to detect differences or relationships among groups. Thus, the study does not provide a valid test of the hypotheses. However, the consistent implementation of measurements enhances validity. For example, each subject must receive the same instructions about completing scales. Data collectors must be trained and observed for consistency. Designs define the timing of measures (e.g., pretest, posttest). Sometimes, the design calls for multiple measures over time. The researcher must specify the points in time during which measures will be taken. The research report must include a rationale for the timing of measures.
Controlling Extraneous Variables
When designing a study, you must identify variables not included in the design (extraneous variables) that could explain some of the variance that occurs when the study variables are measured. In a good design, the effect of these variables on variance is controlled. The extraneous variables commonly encountered in nursing studies are age, education, gender, social class, severity of illness, level of health, functional status, and attitudes. For a specific study, you must think carefully through the variables that could have an impact on that study.
Design strategies used to control extraneous variables include random sampling, random assignment to groups, selecting subjects that are homogeneous in terms of a particular extraneous variable, selecting a heterogeneous sample, blocking, stratification, matching subjects between groups in relation to a particular variable, and statistical control. Table 10-1 summarizes some nursing studies and the various strategies they have used to control extraneous variables.



Random Sampling: Random sampling increases the probability that subjects with various levels of an extraneous variable are included and are randomly dispersed throughout the groups within the study. This strategy is particularly important for controlling unidentified extraneous variables. Whenever possible, however, extraneous variables must be identified, measured, and reported in the description of the sample.
Random Assignment: Random assignment enhances the probability that subjects with various levels of extraneous variables are equally dispersed in treatment and control groups. Whenever possible, however, this dispersion must be evaluated rather than assumed.
Homogeneity: Homogeneity is a more extreme form of equivalence in which the researcher limits the subjects to only one level of an extraneous variable to reduce its impact on the study findings. To use this strategy, you must have previously identified the extraneous variables. You might choose to include subjects with only one level of an extraneous variable in the study. For example, only subjects between the ages of 20 and 30 years may be included, or only subjects with a particular level of education. The study may include only breast cancer patients who have been diagnosed within 1 month, are at a particular stage of disease and are receiving a specific treatment for cancer. The difficulty with this strategy is that it limits generalization to the types of subjects included in the study. Findings could not justifiably be generalized to types of people excluded from the study.
Heterogeneity: In studies in which random sampling is not used, the researcher may attempt to obtain subjects with a wide variety of characteristics (or who are heterogeneous) to reduce the risk of biases. When using the strategy of heterogeneity, you make seek subjects from multiple diverse sources. The strategy is designed to increase generalizability. Characteristics of the sample must be described in the research report.
Blocking: In blocking, the researcher includes subjects with various levels of an extraneous variable in the sample but controls the numbers of subjects at each level of the variable and their random assignment to groups within the study. Designs using blocking are referred to as randomized block designs. The extraneous variable is then used as an independent variable in the data analysis. Therefore, the extraneous variable must be included in the framework and the study hypotheses.
Using this strategy, you might randomly assign equal numbers of subjects in three age categories (younger than 18 years, 18 to 60 years, and older than 60 years) to each group in the study. You could use blocking for several extraneous variables. For example, you could block the study in relation to both age and ethnic background (African American, Hispanic, Caucasian, and Asian). Table 10-2 summarizes an example of this approach.
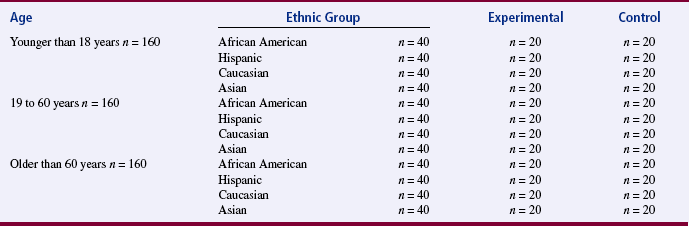
During data analysis for the randomized block design, each cell in the analysis is treated as a group. Therefore, you must evaluate the cell size for each group and the effect size to ensure adequate power to detect differences. A minimum of 20 subjects per group is recommended. The example described for Table 10-2 would require a minimal sample of 480 subjects.
Stratification: Stratification involves the distribution of subjects throughout the sample, using sampling techniques similar to those used in blocking, but the purpose of the procedure is even distribution throughout the sample. The extraneous variable is not included in the data analysis. Distribution of the extraneous variable is included in the description of the sample.
Matching: To ensure that subjects in the control group are equivalent to subjects in the experimental group, some studies are designed to match subjects in the two groups. Matching is used when a subject in the experimental group is randomly selected and then a subject similar in relation to important extraneous variables is randomly selected for the control group. Clearly, the pool of available subjects would have to be large to accomplish this goal. In quasi-experimental studies, matching may be performed without randomization.
Statistical Control: In some studies, it is not considered feasible to control extraneous variables through the design. However, the researcher recognizes the possible impact of extraneous variables on variance and effect size. Therefore, measures are obtained for the identified extraneous variables. Data analysis strategies that have the capacity to remove (partial out) the variance explained by the extraneous variable are performed before the analysis of differences or relationships between or among the variables of interest in the study. One statistical procedure commonly used for this purpose is analysis of covariance, described in Chapter 22. Although statistical control seems to be a quick and easy solution to the problem of extraneous variables, its results are not as satisfactory as those of the various methods of design control.
Triangulation
There has been much controversy among researchers about the relative validity of various approaches to research. Designing quantitative experimental studies with rigorous controls may provide strong external validity but questionable or limited internal validity. Qualitative studies may have strong internal validity but questionable external validity. A single approach to measuring a concept may be inadequate to justify a claim that it is a valid measure of a theoretical concept. Testing a single theory may leave the results open to the challenge of rival hypotheses from other theories.
Researchers have been exploring alternative design strategies that might increase the overall validity of studies. The strategy generating the most interest is triangulation. First used by Campbell and Fiske in 1959, triangulation is the combined use of two or more theories, methods, data sources, investigators, or analysis methods in the study of the same phenomenon. Denzin (1989) identified the following four types of triangulation: (1) data triangulation, (2) investigator triangulation, (3) theoretical triangulation, and (4) methodological triangulation. Kimchi, Polivka, and Stevenson (1991) have suggested a fifth type, analysis triangulation. Multiple triangulation is the combination of more than one of these types.
Data Triangulation
Data triangulation involves the collection of data from multiple sources for the same study. For the collection to be considered triangulation, the data must all have the same foci. The intent is to obtain diverse views of the phenomenon under study for purposes of validation (Kimchi et al., 1991). These data sources provide an opportunity for researchers to examine how an event is experienced by different individuals, groups of people, or communities; at different times; or in different settings (Mitchell, 1986).
Longitudinal studies are not a form of triangulation because their purpose is to identify change. When time is triangulated, the purpose is to validate the congruence of the phenomenon over time. For a multisite study to be triangulated, data from the settings must be cross-validated for multisite consistency. When person triangulation is used, data from individuals might be compared for consistency with data obtained from groups. The intent is to use data from one source to validate data from another source (Kimchi et al., 1991).
Investigator Triangulation
In investigator triangulation, two or more investigators with diverse research training backgrounds examine the same phenomenon (Mitchell, 1986). For example, a qualitative researcher and a quantitative researcher might cooperatively design and conduct a study of interest to both. Kimchi et al. (1991, p. 365) have held that investigator triangulation has occurred when “(a) each investigator has a prominent role in the study, (b) the expertise of each investigator is different, and (c) the expertise (disciplinary bias) of each investigator is evident in the study.” The use of investigator triangulation removes the potential for bias that may occur in a single-investigator study (Denzin, 1989; Duffy, 1987). Kimchi et al. (1991) suggested that investigator triangulation is difficult to discern from published reports. They advised that, in the future, authors should claim that they have performed investigator triangulation and describe how they achieved it in their study.
Theoretical Triangulation
Theoretical triangulation is the use of all the theoretical interpretations “that could conceivably be applied to a given area” (Denzin, 1989, p. 241) as the framework for a study. Using this strategy, the researcher critically examines various theoretical points of view for utility and power. The researcher then develops competing hypotheses on the basis of the different theoretical perspectives, which are tested using the same data set. We can then place greater confidence in the accepted hypotheses because they have been pitted against rival hypotheses (Denzin, 1989; Mitchell, 1986). This is a tougher test of existing theory in a field of study because alternative theories are examined rather than a single test of a proposition or propositions from one theory. Theoretical triangulation can lead to the development of more powerful substantive theories that have some scientific validation. Denzin (1989) recommended the following steps to achieve theoretical triangulation:
1. A comprehensive list of all possible interpretations in a given area is constructed. This will involve bringing a variety of theoretical perspectives to bear upon the phenomena at hand (including interactionism, phenomenology, Marxism, feminist theory, semiotics, cultural studies, and so on).
2. The actual research is conducted, and empirical materials are collected.
3. The multiple theoretical frameworks enumerated in Step 1 are focused on the empirical materials.
4. Those interpretations that do not bear on the materials are discarded or set aside.
5. Those interpretations that map and make sense of the phenomena are assembled into an interpretive framework that addresses all of the empirical materials.
6. A reformulated interpretive system is stated based at all points on the empirical materials just examined and interpreted.” (Denzin, 1989, p. 241)
Currently, few nursing studies meet Denzin’s criteria for theoretical triangulation, although some frameworks for nursing studies are developed to compare propositions from more than one theory. For example, Yarcheski, Mahon, and Yarcheski (1999) conducted an empirical test of alternative theories of anger in early adolescents. Kushner and Morrow (2003) proposed triangulating grounded theory, feminist theory, and critical theory.
Methodological Triangulation
Methodological triangulation is the use of two or more research methods in a single study (Mitchell, 1986). The difference can be at the level of design or of data collection. Researchers frequently use methodological triangulation, the most common type of triangulation, to examine complex concepts. Complex concepts of interest in nursing include caring, sustaining hope during terminal illness, coping with chronic illness, and promoting health.
There are two types of methodological triangulation: within-method triangulation and across-method triangulation (Denzin, 1989). Within-method triangulation, the simpler form, is used when the phenomenon being studied is multidimensional. For example, two or three different quantitative instruments might be used to measure the same phenomenon. Conversely, two or more qualitative methods might be used (Annells, 2006). Examples of different data collection methods are questionnaires, physiological instruments, scales, interviews, and observation techniques. Between-method triangulation involves combining research strategies from two or more research traditions in the same study. For example, methods from qualitative research and quantitative research might be used in the same study (Duffy, 1987; Mitchell, 1986; Morse, 1991; Porter, 1989). From these research traditions, different types of designs, methods of measurement, data collection processes, or data analysis techniques might be used to examine a phenomenon to try to achieve convergent validity.
Mitchell (1986) identified the following four principles that should be applied with methodological triangulation:
(1) The research question must be clearly focused; (2) the strengths and weaknesses of each chosen method must complement each other; (3) the methods must be selected according to their relevance to the phenomenon being studied; and (4) the methodological approach must be monitored throughout the study to make sure the first three principles are followed. (pp. 22–23)
Analysis Triangulation
In analysis triangulation, the same data set is analyzed with the use of two or more differing analyses techniques. The purpose is to evaluate the similarity of findings. The intent is to provide a means of cross-validating the findings (Kimchi et al., 1991).
Pros and Cons of Triangulation
Triangulation may become the research trend of the future. However, before jumping on this bandwagon, we would be prudent to consider the implications of using these strategies. Some are concerned that triangulation will be used in studies for which it is not appropriate. An additional concern is that the popularization of the method will generate a number of triangulated studies that have been poorly conducted. Sohier (1988, p. 740) pointed out that “multiple methods will not compensate for poor design or sloppy research. Ill-conceived measures will compound error rather than reduce it. Unclear questions will not become clearer.”
The suggestion that qualitative and quantitative methods be included in the same study has generated considerable controversy in the nursing research community (Clarke & Yaros, 1988; Mitchell, 1986; Morse, 1991; Phillips, 1988a, 1988b; Sims & Sharp, 1998). Myers and Haase (1989) believe that the integration of these two research approaches is inevitable and essential. Clarke and Yaros (1988) have suggested that combining methods is the first step in the development of new methodologies, which are greatly needed to investigate nursing phenomena. Hogan and DeSantis (1991) believe that triangulation of qualitative and quantitative methods will lead to the development of substantive theory. Phillips (1988a, 1988b) has held the position that the two methods are incompatible because they are based on different worldviews. If a single investigator attempted to use both methods in one study, he or she would have to interpret the meaning of the data from two philosophical perspectives. Because researchers tend to acquire their training within a particular research tradition, it may be difficult for them to incorporate another research tradition. As Sandelowski (1995, p. 569) has stated, “a misplaced ecumenicism, definitional drift, and conceptual misappropriation are evident in discussions of triangulation, which has become a technique for everything.”
Mitchell (1986) identified a number of problems that investigators may encounter when using this method. These strategies require many observations and result in large volumes of data for analysis. The investigator must have the ability and the desire to deal with complex design, measurement, and analysis issues with limited resources. Mitchell (1986) identified the following issues that the investigator must consider during the data analysis:
• How to combine numerical (quantitative) data and linguistic or textual (qualitative) data
• How to interpret divergent results from numerical data and linguistic data
• What to do with overlapping concepts that emerge from the data and are not clearly differentiated from one another
• Whether and how to weight data sources
• Whether each different method used should be considered equally sensitive and weighted equally
Myers and Haase (1989) provided the following guidelines, which they believe are necessary when one is merging qualitative and quantitative methods. These guidelines are based on the assumption that at least two investigators (one qualitative and one quantitative) are involved in any study combining these two methods.
1. The world is viewed as a whole, an interactive system with patterns of information exchange between subsystems or levels of reality.
2. Both subjective and objective data are recognized as legitimate avenues for gaining understanding.
3. Both atomistic and holistic thinking are used in design and analysis.
4. The concept of research “participant” includes not only those who are the subjects of the methodology but also those who administer or operate the methodology.
5. Maximally conflicting points of view are sought with provision for systematic and controlled confrontation. Respectful, honest, open confrontation on points of view between investigators is essential. Here, conflict is seen as a positive value because it offers potential for expanding questioning and consequent understanding. Confrontation occurs between co-investigators with differing expertise who recognize that both approaches are equally valid and vulnerable. Ability to consider participants’ views which may differ from the investigator’s perspective is equally important.” (Myers & Haase, 1989, p. 300)
Morse (1991) stated that qualitative and quantitative methods cannot be equally weighted in a research project. The project either (1) is theoretically driven by qualitative methods and incorporates a complementary quantitative component or (2) is theoretically driven by the quantitative method and incorporates a complementary qualitative component. However, each method must be complete in itself and must meet appropriate criteria for rigor. For example, if qualitative interviews are conducted, “the interviews should be continued until saturation is reached, and the content analysis conducted inductively, rather than forcing the data into some preconceived categories to fit the quantitative study or to prove a point” (Morse, 1991, p. 121).
Morse (1991) also noted that the greatest threat to validity of methodological triangulation is not philosophical incompatibility but the use of inadequate or inappropriate samples. The quantitative requirement for large, randomly selected samples is inconsistent with the qualitative requirement that subjects be selected according to how well they represent the phenomena of interest, and sample selection ceases when saturation of data is reached. Morse (1991) did not consider it necessary, however, for the two approaches to use the same samples for the study. In all aspects of a methodologically triangulated study, Morse (1991) observed that strategies must be implemented to maintain the validity for each method. Overall, Morse supported the use of methodological triangulation, believing that it “will strengthen research results and contribute to theory and knowledge development” (Morse, 1991, p. 122).
Duffy (1987, p. 133) held that triangulation, “when used appropriately, combines different methods in a variety of ways to produce richer and more insightful analyses of complex phenomena than can be achieved by either method separately.” Coward (1990) opined that the combining of qualitative and quantitative methods will increase support for validity:
Construct validity is enhanced when results are stable across multiple measures of a concept. Statistical conclusion validity is enhanced when results are stable across many data sets and methods of analysis. Internal validity is enhanced when results are stable across many potential threats to causal inference. External validity is supported when results are stable across multiple settings, populations, and times.” (p. 166)
Sandelowski (1995) recommended that
the concept of triangulation ought to be reserved for designating a technique for conformation employed within paradigms in which convergent and consensual validity are valued and in which it is deemed appropriate to use information from one source to corroborate another. Whether triangulation [is used] or not, the purpose, method of execution, and assumptions in forming any research combinations should be clearly delineated. (p. 573)
SUMMARY
• Research design is a blueprint for the conduct of a study that maximizes the researcher’s control over factors that could interfere with the desired outcomes.
• Before selecting a design, the researcher must understand certain concepts: causality, bias, manipulation, control, and validity.
• The purpose of design is to set up a situation that maximizes the possibilities of obtaining valid answers to research questions or hypotheses.
• A good design provides the subjects, the setting, and the protocol within which these comparisons can be clearly examined.
• Designs were developed to reduce threats to the validity of the comparisons. However, some designs are more effective in reducing threats than others.
• In designing the study, the researcher must identify variables not included in the design (extraneous variables) that could explain some of the variance in measurement of the study variables.
• Triangulation is the combined use of two or more theories, methods, data sources, investigators, or analysis methods to study the same phenomenon.
REFERENCES
Anells, M. Triangulation of qualitative approaches: Hermeneutical phenomenology and grounded theory. Journal of Advanced Nursing. 2006;56(1):55–61.
Campbell, D.T., Fiske, D.W. Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin. 1959;56(2):81–105.
Clarke, P.N., Yaros, P.S. Research blenders: Commentary and response. Nursing Science Quarterly. 1988;1(4):147–149.
Cook, T.D, Campbell, D.T. Quasi-experimentation: Design and analysis issues for field settings. Chicago: Rand McNally, 1979.
Coward, D.D. Critical multiplism: A research strategy for nursing science. Image: Journal of Nursing Scholarship. 1990;22(3):163–167.
Denzin, N.K. The research act: A theoretical introduction to sociological methods, (3rd ed.). New York: McGraw-Hill, 1989.
Duffy, M.E. Methodological triangulation: A vehicle for merging quantitative and qualitative research methods. Image: Journal of Nursing Scholarship. 1987;19(3):130–133.
Goodwin, L.D. Increasing efficiency and precision of data analysis: Multivariate vs. univariate statistical techniques. Nursing Research. 1984;33(4):247–249.
Greer, D.S., Mor, V., Sherwood, S., Morris, J.M., Birnbaum, H. National hospice study analysis plan. Journal of Chronic Disease. 1983;36(11):737–780.
Hogan, N., DeSantis, L. Development of substantive theory in nursing. Nursing Education Today. 1991;11(3):167–171.
Kimchi, J., Polivka, B., Stevenson, J.S. Triangulation: Operational definitions. Nursing Research. 1991;40(6):364–366.
Kushner, K.E., Morrow, R. Grounded theory, feminist theory, critical theory: Toward theoretical triangulation. Advances in Nursing Science. 2003;26(1):30–43.
McGuire, D.B., DeLoney, V.G., Yeager, K.A., Owen, D.C., Peterson, D.E., Lin, L.S., et al. Maintaining study validity in a changing clinical environment. Nursing Research. 2000;49(4):231–235.
Mitchell, E.S. Multiple triangulation: A methodology for nursing science. Advances in Nursing Science. 1986;8(3):18–26.
Morse, J.M. Approaches to qualitative-quantitative methodological triangulation. Nursing Research. 1991;40(1):120–123.
Myers, S.T., Haase, J.E. Guidelines for integration of quantitative and qualitative approaches. Nursing Research. 1989;38(5):299–301.
Phillips, J.R. Research issues: Research blenders. Nursing Science Quarterly. 1988;1(1):4–5.
Porter, E.J. The qualitative-quantitative dualism. Image: Journal of Nursing Scholarship. 1989;21(2):98–102.
Sandelowski, M. Triangles and crystals: On the geometry of qualitative research. Research in Nursing & Health. 1995;18(6):569–574.
Sims, J., Sharp, K. A critical appraisal of the role of triangulation in nursing research. International Journal of Nursing Studies. 1998;35(1/2):23–31.
Sohier, R. Multiple triangulation and contemporary nursing research. Western Journal of Nursing Research. 1988;10(6):732–742.
Yarcheski, A., Mahon, M.E., Yarcheski, T.J. An empirical test of alternate theories of anger in early adolescents. Nursing Research. 1999;48(6):317–323.