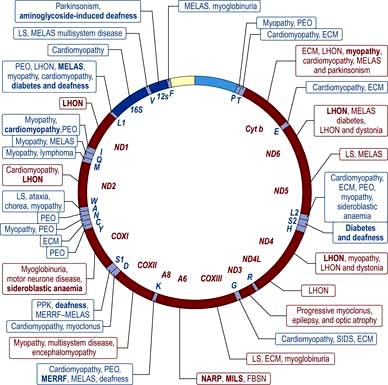
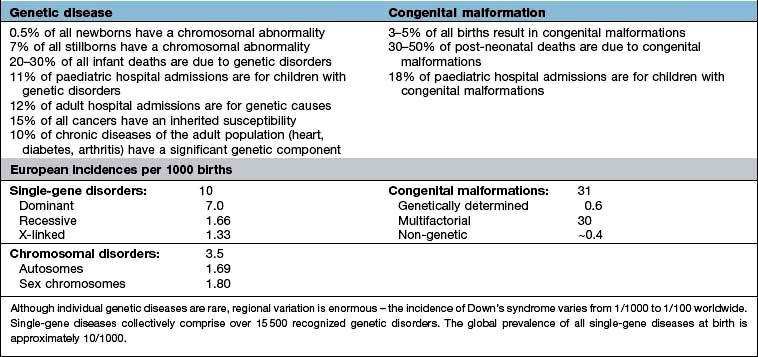
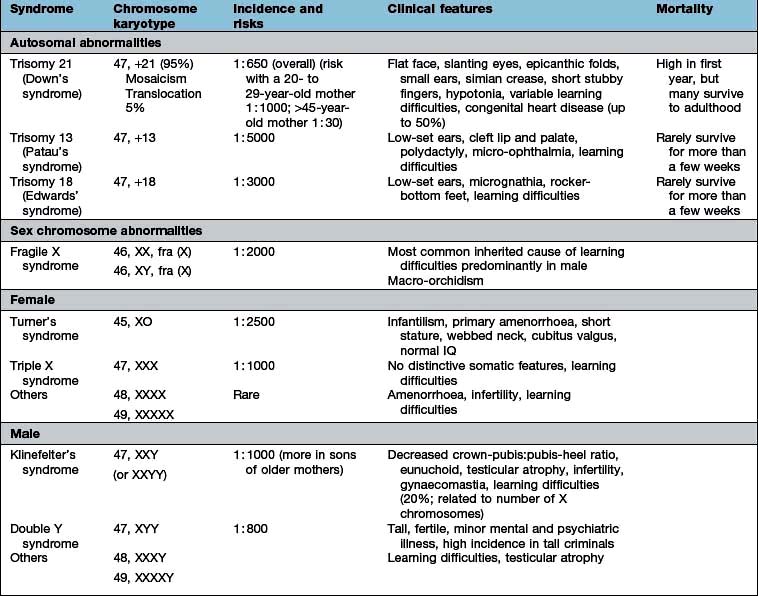
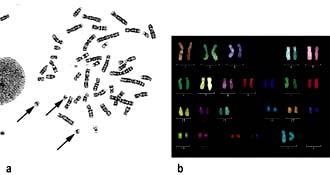
Chapter 2 Molecular cell biology and human genetics
Cell biology
Cells consist of cytoplasm enclosed within a lipid sheath (the plasma membrane). The cytoplasm contains a variety of organelles (sub-cellular compartments enclosed within their own membranes) in a mixture of salts and organic compounds (the cytosol). These are held within an adaptive internal scaffold (the cytoskeleton) that radiates from the nucleus outwards to the cell surface (Fig. 2.1). Many cells have special functions and their size, shape and behaviour adapt to meet their physiological roles. Cells can be organized into tissues and organs in which the individual component cells are in contact and able to send and receive messages, both directly and indirectly. Coordinated cellular responses can be achieved through systemic signalling, e.g. via hormones.
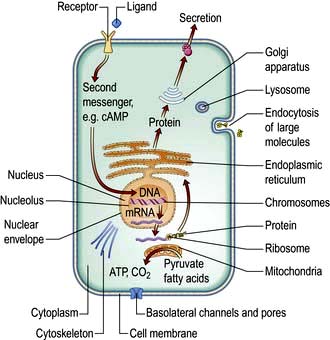
Figure 2.1 Diagrammatic representation of the cell, showing the major organelles and receptor activation, intracellular messengers, protein formation and secretion, endocytosis of large molecules and production of ATP.
Cell structure
Cellular membranes
 Lipid bilayers separate the cell contents from the external environment and compartmentalize distinct cellular activities into organelles. These consist of a large variety of glycerophospholipids and sphingolipids. Membrane lipids usually have two hydrophobic acyl chains linked via glycerol or serine, to polar hydrophilic head groups (Fig. 2.2). This amphiphilic nature, with a ‘water-loving’ head and a ‘water-hating’ tail, means that in aqueous solution membrane lipids self-associate into a tail-to-tail bilayer with their hydrophobic chains separated from the aqueous phase by their polar head groups.
Lipid bilayers separate the cell contents from the external environment and compartmentalize distinct cellular activities into organelles. These consist of a large variety of glycerophospholipids and sphingolipids. Membrane lipids usually have two hydrophobic acyl chains linked via glycerol or serine, to polar hydrophilic head groups (Fig. 2.2). This amphiphilic nature, with a ‘water-loving’ head and a ‘water-hating’ tail, means that in aqueous solution membrane lipids self-associate into a tail-to-tail bilayer with their hydrophobic chains separated from the aqueous phase by their polar head groups.
Liposomes are spheres enclosed within a lipid bilayer. This is the most energetically favourable form for membrane lipids in solution. These have been used clinically to deliver more hydrophilic cargo, such as drugs or DNA, to cells.
Plasma membranes are more complicated than liposomes. Their lipids are organized asymmetrically in the bilayer. For example, the outer leaflet of the plasma membrane is enriched in phosphatidyl-choline (PC) and the sphingolipids, whereas the inner leaflet is enriched in phosphatidyl-serine (PS) and phosphatidyl-ethanolamine (PE). This arrangement is necessary in normal physiology and in disease, not just for barrier function. For example, PC is extracted from the outer-leaflet of the canalicular membrane of hepatocytes to form the lipid/bile-salt micelles of bile. One of the sphingolipids, GM1-ganglioside, is the receptor for cholera toxin. The appearance of PS in the outer leaflet of the membrane is an early step in the apoptotic pathway and signals to macrophages to clear the dying cell, while PE, once cleaved by phospholipase, produces two signalling molecules as second messengers (see p. 25). Cholesterol is also an essential component of the plasma membrane and cannot be substituted by plant sterols, which have a subtly different shape. For this reason, the liver secretes plant sterols back into the gut.
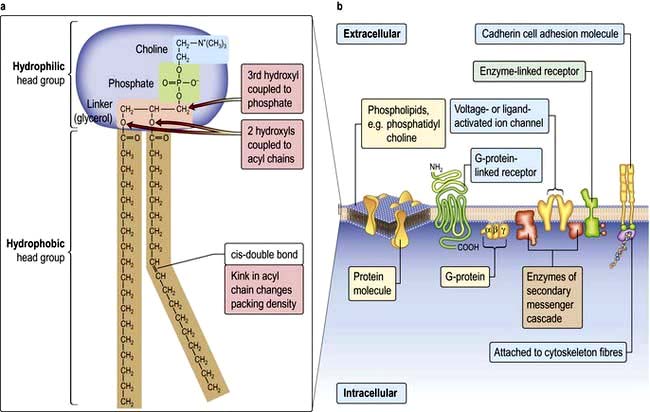
Figure 2.2 (a) Membrane lipid phosphatidyl-choline structure. The phospholipid structure is expanded to show its detail. (b) Cell membrane showing lipid structures and a selection of integral proteins such as receptors, G-proteins, channels, secondary messenger enzyme complexes and cell adhesion molecules.
Membrane proteins
Cells can absorb gases or small hydrophobic compounds directly across the plasma membrane by passive diffusion, but membrane proteins are required to take-up hydrophilic nutrients or secrete hydrophilic products, to mediate cell–cell communication and to respond to endocrine signals. Membrane proteins can be integral to the membrane (i.e. their protein chain traverses the membrane one or multiple times) or they can be anchored to the membrane by an acyl chain (Fig. 2.2).
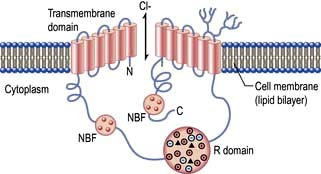
Membrane channel proteins (Fig. 2.3): membrane proteins that form solute channels through the membrane can only work downhill and only to equilibrium. Solute actually moves down its electrochemical gradient, which is the combined force of the electric potential and the solute concentration gradient across the membrane. The bulk flow can be very high, the opening and closing of the channel can be regulated, and they can be selective for specific solutes. For example, the cystic fibrosis transmembrane regulator (CFTR; Fig. 2.22), the protein whose malfunction causes cystic fibrosis, is a chloride channel found on the apical surface of epithelial cells. CFTR functions to regulate the fluidity of the extra-epithelial mucous layer. When the channel opens, millions of negatively-charged chloride ions flow out of the cell down their electrochemical gradient. This induces positively-charged sodium ions to flow between the cells of the epithelium (via a paracellular pathway) to balance the electrical charge. Water follows the efflux of sodium chloride by osmosis, thus maintaining the fluidity of the mucus.
Transporters (Fig. 2.3): in contrast to channels, transporters have a low capacity and work by binding solute on one side of the membrane which induces a conformational change that exposes the solute binding site on the other side of the membrane for release.
Receptors: there are three major receptor categories: receptors that mediate endocytosis, anchorage receptors (e.g. integrins, see p. 23) and signalling receptors (see cell signalling p. 24). There are two forms of receptor-mediated endocytosis:
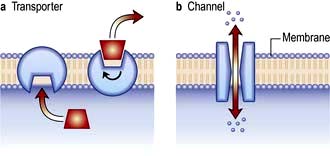
Figure 2.3 The difference between a transporter and a channel. (a) Transporters expose specific solute binding sites alternately on different sides of the membrane. They can function uphill if coupled to an energy source (active transport) or be downhill only (facilitated diffusion). They are low capacity. (b) Channels form a continuous pore through the membrane. They can be regulated and selective and only work downhill; bulk flow is high.
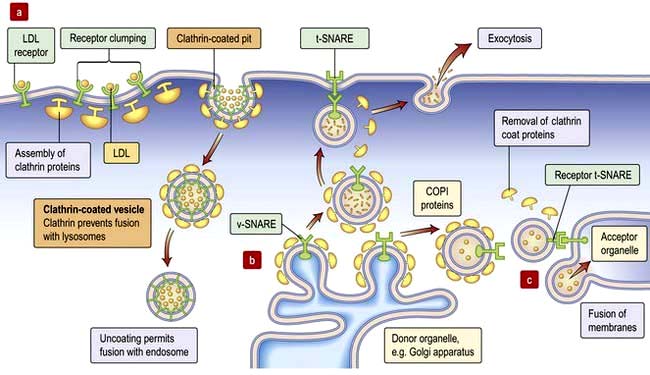
Figure 2.4 Intracellular transport. (a) Receptor-mediated endocytosis or pinocytosis. (b) Trafficking of vesicles containing synthesized proteins to the cell surface (e.g. hormones). (c) Traffic between organelles is also mediated by v- and t-SNARE-containing organelles. v-SNARE, vesicle-specific SNARE; t-SNARE, target-specific SNARE. COPI, coat protein; LDL, low density lipoprotein.
Organelles
Cytoplasmic organelles
Endoplasmic reticulum (ER) is an array of interconnecting tubules or flattened sacs (cisternae) that is contiguous with the outer nuclear membrane (Fig. 2.1). There are three types of ER:
Golgi apparatus has flattened cisternae similar to those of the ER but arranged in a stack (Fig. 2.1). Vesicles that bud from the ER with cargo destined for secretion, for the plasma membrane or for other organelles, fuse with the Golgi stack. The proteins, lipids and sterols synthesized in the ER are exported to the Golgi apparatus to complete maturation (e.g. the final stages of membrane protein glycosylation occurs here). The mature products are then sorted into vesicles that bud from the Golgi for transport to their final destination (Fig. 2.4b,c). Mutation in the Golgin protein GMAP-210, with a probable role in tethering of the Golgi cisternae, causes achondrogenesis type 1A, where Golgi architecture is disrupted, particularly in bone cells.
Lysosomes mature from vesicles (endosomes) that bud from the Golgi. They contain digestive enzymes such as lipases, proteases, nucleases and amylases that work in an acidic environment. The membrane of the lysosome therefore includes a proton ATPase pump to acidify the lumen of the organelle. Lysosomes fuse with phagocytotic vesicles to digest their contents. This is crucial to the function of macrophages and polymorphs (neutrophils and eosinophils) in killing and digesting infective agents, in tissue remodelling during development, and osteoclast remodelling of bone. Not surprisingly, many metabolic disorders result from impaired lysosomal function (p. 1040).
Peroxisomes contain enzymes for the catabolism of long-chain fatty acids and other organic substrates like bile acids and D-amino acids. Hydrogen peroxide (H2O2), a by-product of these reactions, is a highly reactive oxidizing agent, so peroxisomes also contain catalase to detoxify the peroxide. Catalase can reduce H2O2 to water while oxidizing harmful phenols and alcohols thus beginning their detoxification. Peroxisome dysfunction can lead to rare metabolic disorders such as leukodystrophies and rhizomelic dwarfism.
Mitochondria are the engines of the cell, providing energy in the form of ATP. Mitochondria can be small, discrete and few in number in cells with low energy demand, or large and abundant in cells with a high energy demand like hepatocytes or muscle cells. The mitochondrion has its own genome encoding 13 proteins. The other proteins (~1000) required for mitochondrial function are encoded by the nuclear genome and imported into the mitochondrion. The mitochondrion has a double membrane surrounding a central matrix. The central matrix contains the enzymes for the Krebs cycle, which accepts the products of sugar and fatty acid catabolism and uses it to produce cofactors that donate their electrons into the electron transport chain of the inner membrane (see pp. 20, 31). The inner membrane is highly folded into cristae to increase its effective surface area. The protein complexes of the electron transport chain accept and donate electrons in redox reactions, releasing energy to efflux protons (H+) into the inter-membrane space. ATP synthase, another integral membrane protein, uses this H+ electrochemical gradient to drive formation of ATP. Mitochondria have many additional functions, including roles in apoptosis (see p. 32) and supply of substrates for biosynthesis. Mitochondria are also necessary for the synthesis of porphyrin, deficiency of which causes a range of diseases collectively called porphyrias (p. 1043).
Nucleus
The most prominent cellular organelle, the nucleus, has a double membrane (the outer membrane is continuous with the ER) enclosing the human genome. The double membrane contains nuclear pores through which gene regulatory proteins, transcription factors and RNA that has been transcribed from the DNA, are transported. The nuclear matrix is highly organized. Microscopically dense regions of heterochromatin represent highly compacted chromosomal DNA which tends to be transcriptionally repressed. Lighter regions of euchromatin contain extended chromosomes which tend to be transcriptionally active. The most prominent nuclear compartment, the nucleolus, is where ribosomal RNA (rRNA) is synthesized and ribosomal subunits are assembled.
The cytoskeleton
A complex network of structural proteins regulates the shape, strength and movement of the cell, and the traffic of internal organelles and vesicles. The major components are microtubules, intermediate filaments and microfilaments.
Microtubules (20–25 nm diameter) are polymers of α and β tubulin. These tubular structures resist bending and stretching, and are polar with plus and minus ends. They emanate from the microtubule organizing centre (MTOC), a complex of centrioles, γ-tubulin and other proteins, with their plus ends extending into the cell. At their plus ends repeated cycles of assembly and disassembly permit rapid changes in length. Microtubules form a ‘highway’, transporting organelles and vesicles through the cytoplasm. The two major microtubule-associated motor proteins (kinesin and dynein) allow movement of cargo to the plus and minus ends, respectively. During cell division the MTOC forms the mitotic spindle (see p. 28). Drugs that disrupt microtubule assembly (e.g. colchicine and vinca alkaloids) or stabilize microtubules (taxanes) preferentially kill dividing cells by preventing mitosis.
Intermediate filaments (~10 nm) form a network around the nucleus extending to the periphery of the cell. They make cell-to-cell contacts with adjacent cells via desmosomes, and with basement matrix via hemidesmosomes (Fig. 2.5; see also Fig. 24.27). Their function appears to be structural integrity; they are prominent in cellular tissues under stress and their disruption in genetic disease can cause structural defects or cell collapse. More than 40 different types of proteins polymerize to form intermediate filaments specific to particular cell types. For example keratin intermediate fibres are only found in epithelial cells whilst vimentin is in mesothelial (fibroblastic) cells. However, lamin intermediate filaments form the nuclear membrane skeleton in most cells.
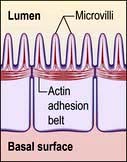
Microfilaments (3–6 nm) are polymers of actin, one of the most abundant proteins in all cells. The actin microfilament network controls cell shape, prevents cellular deformation, is involved in cell–cell and cell–matrix adhesion, in cell movements such as crawling and cytokinesis (cell division), and in intracellular vesicle transport. Bundles of actin filaments form the structural core of cellular protrusions such as microvilli, lamellipodia and filopodia (see below). Actin microfilament bundles within the cell can associate with myosin II to form contractile stress fibres, similar to muscle sarcomeres. Stress fibres are often found as circumferential belts around the apical surfaces of epithelial cells where cells associate with adjacent cells via adherens junctions, permitting reaction to external stresses as a cellular sheet. Stress fibres also form where actin interacts via accessory proteins with the extracellular matrix at sites of focal adhesion (see Fig. 2.8c). This occurs during cell movements during inflammation, wound healing and metastasis. During cytokinesis actin-myosin II bundles form the contractile ring separating dividing cells. Like microtubules, microfilaments are polar, so can be used to transport secretory vesicles, endosomes and mitochondria, powered by motor proteins, including myosin I and V.
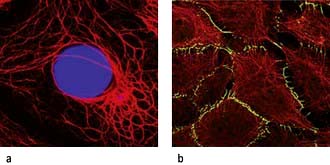
Figure 2.5 Cytoskeleton of epithelial cells. (a) Keratin red, nuclei stained in blue. (b) Keratin filaments (in red) and a desmosomal plaque component desmoplakin in green.
(Reproduced with permission from Moll R, Divo M, Langbein L. The human keratins: biology and pathology. Histochemistry and Cell Biology 2008; 129:705–733.)
Cell shape and motility
The cytoskeleton determines cell shape and surface structures.
Microvilli. The apical surface of some epithelial cells is covered in tiny microvilli (~1 µm long) forming a brush border of thousands of small finger-like projections of the plasma membrane that increase the surface area for uptake or efflux (Fig. 2.6). At their core are 20–30 cross-linked actin microfilaments.

Figure 2.6 Cilia and microvilli in trachea. (a) Scanning electron microscopy image of longer cilia bearing cells with adjacent microvilli-bearing cells. (b) Transmission electron microscope image of section.
(Courtesy of Louisa Howard, Dartmouth EM Facility.)
Motile cilia are also fine, finger-like protrusions but these are longer (~10–20 µm long) (Fig. 2.6). At their core is an axoneme, a bundle of nine cross-linked tubulin microtubule doublets surrounding a central pair. The action of the motor domain dynein serves to bend the cilium. Neighbouring cilia tend to beat in unison generating waves of motion that move fluid over the cell surface in the gut and airways (see Fig. 15.9), and also in the fallopian tubes.
Non-motile or primary cilia. Most cells also have a single primary cilium. These cilia have a variant axoneme with no central pair of microtubules and while they have dynein they are non-motile (the dynein is used to traffic cargo along the axoneme). Primary cilia are used for signalling during development and in the adult. Other related non-motile cilia are found in specialized cells, e.g. in the photoreceptors of the retina, the sensory neurones of the olfactory system, and in the sensory hair cells of the cochlea. A range of human ciliopathies (Fig. 2.7) have been described with pleiotropic symptoms depending on which cilia are affected. These include polycystic kidney disease, Bardet–Biedl syndrome (p. 1007), Joubert’s syndrome and Ellis–van Creveld syndrome.
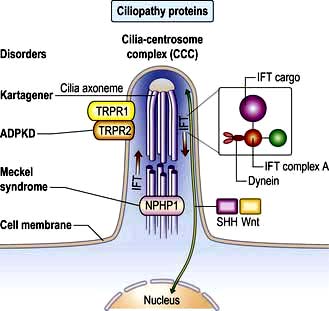
Figure 2.7 Structure of a cilium showing ciliopathy proteins and intraflagellar transport (IFT). Some single-gene ciliopathies are shown along with their gene products situated in the cilia centrosome complex (CCC). Receptors on cilia receive external cell signals which are processed via sonic hedgehog (SHH) and Wnt pathways. The gene mutation can act during morphogenesis (e.g. Meckel’s syndrome) or during tissue maintenance and repair leading to degenerative disorders. The IFT system transports axoneme and membrane compounds in raft macromolecular particles (IFT cargo and complex). Retrograde transport occurs via cytoplasmic dynein. NPHP1, nephronophthisis type 1; TRPR1 and 2, polycystin 1 and 2.
(Adapted from Hildebrandt F, Benzing T, Katsanis N. Ciliopathies. New England Journal of Medicine 2011; 364:1533–1543.)
Flagella. The single flagellum found on sperm is structurally related to cilia but is longer (~40 µm) and has a whip-like motion.
Cell motility is essential during development and in the adult when macrophages migrate to sites of infection, keratinocytes migrate to close wounds, osteoclasts and osteoblasts tunnel into and remodel bone, and fibroblasts migrate to sites of injury to repair the extracellular matrix. Most cell motility in the adult human takes the form of cell crawling which is dependent on remodelling of the actin cytoskeleton. How the actin cytoskeleton is remodelled determines the mode of migration:
Filopodia: if remodelled essentially in one dimension into a long actin filament, the leading edge of the plasma membrane is pushed forward as spikes, similar to long thin villi.
Lamellipodia: if remodelled in two dimensions to form a network of cross-linked actin microfilaments, a broad flat skirt or lamellipodium is formed.
Pseudopodia: are more three-dimensional projections as the actin cytoskeleton is remodelled into a gel-like lattice.
Movement. A similar mechanism involving the coordinated remodelling of the cytoskeleton and the formation and release of cell adhesions underlies all three modes of migration. Essentially, actin is polymerized at the leading edge extending the plasma membrane forward. New adhesions are formed with the substratum (cells and/or extracellular matrix) at the leading edge to provide purchase. Release of attachments and depolymerization of the actin filaments at the trailing edge then allows the cell to move forward. Myosin and myosin motor proteins may also be involved at the trailing edge providing the tractive force to pull the cell body forward. The complex coordination of these processes is controlled via signalling pathways involving members of the Rho protein family of GTPases (see p. 21). Key signalling targets are the WASp family of proteins which stimulate actin polymerization. The significance of cell motility in humans is illustrated by mutation of the WASp expressed in blood cell lineages, which causes Wiskott–Aldrich syndrome (p. 66), and is characterized by severe immunodeficiency and thrombocytopenia (platelet deficiency).
The cell and its environment
Most cells differentiate or specialize to perform particular functions within tissues where they interact with the extracellular matrix (ECM) or other cells. The major tissue types are epithelia and connective tissues as well as muscle and neural tissue:
Epithelial tissues comprise layers of cells held tightly together by intercellular junctions and are usually separated from underlying tissue by specialized ECM called basal lamina. Epithelia cover surfaces (e.g. epidermis, tongue surface) and line passageways (airways, digestive tract, blood vessels), providing protection and regulating absorption and secretion.
Connective tissues provide support to other tissues and give organs shape. They comprise cells (fibroblasts) embedded within ECM such as the matrix of bone, dermis of skin and the fluid matrix of blood.
Extracellular matrix
The ECM is the gel matrix outside the cell, usually secreted by fibroblasts. ECM determines tissue properties, e.g. in bone it is calcified; in tendons it is tough and rope-like; and in neural tissue it is almost absent. However, ECM is more than just a support matrix. It affects cell shape, migration, cell-cell communication and signalling, proliferation and survival.
The gel or ground substance of the ECM is made from polysaccharides (glycosaminoglycans or GAGs), usually bound to proteins to form proteoglycans (p. 494). These are a diverse group of molecules conferring different matrix properties in different tissues. They form hydrated gels which can resist compression yet permit diffusion of metabolites and signalling molecules.
Hyaluronan, a very large hydrated GAG, is secreted into the joint space in synovial joints (p. 493), where it aids lubrication and helps reduce compressive forces.
Aggrecan, a very large proteoglycan, forms part of the articular cartilage of joints (p. 494) also contributing to compression resistance.
Decorin is a much smaller proteoglycan from loose connective tissue of skin with both structural and signalling function (through binding and regulating growth factor activity).
Fibrous proteins of ECM (p. 495) include collagens and tropoelastin, which polymerize into collagen and elastin fibres, and fibronectin which is insoluble in many tissues but soluble in plasma. Collagen provides tensile strength, elastin confers elasticity, while the widely distributed fibronectin adheres to both cells and ECM, and thus positions cells within the ECM. Collagens, the most abundant proteins in the body, are widely distributed and play a structural role in skin and bone, where collagen defects and disorders often manifest. Elastin fibres are abundant in arteries, lung and skin. Elastic fibres have a fibrillin sheath and fibrillin mutations underlie Marfan’s syndrome (p. 760). The ECM can be degraded and remodelled by proteins of the matrix metalloproteinase (MMP) family. These are needed for angiogenesis and morphogenesis and are also involved in the pathophysiology of cancer, cirrhosis and arthritis.
Basal lamina or basement membrane (lamina propria) is a specialized form of ECM, which separates cells from underlying tissue and provides a supportive, anchoring and protective role. Basal lamina can also act as molecular filters (e.g. glomerular filtration barrier, p. 636) and mediate signalling between adjacent tissues (e.g. epidermal-dermal signalling in skin). Type IV collagen, heparan sulphate proteoglycan, laminin and nidogen are key basal lamina proteins. Inherited abnormalities in these proteins cause skin blistering diseases (see Fig. 24.27). Breach of the basal lamina by invading cancer cells is a key stage in progression of epithelial carcinoma in situ to a malignant carcinoma.
Cell–cell adhesion
Cells need to interact directly for barrier function, tissue strength and to communicate. This is mediated by several types of proteins that form junctions between cells.
Cell–cell adhesion proteins (Fig. 2.8a)
As well as adhesion via multiprotein junctions, intercellular adhesion is achieved by individual transmembrane proteins.
Immunoglobulin-like cell adhesion molecules (iCAMs or CAMs) (Fig. 2.8a) are structurally related to antibodies. The neural cell adhesion molecule (N-CAM) is found predominantly in the nervous system. It mediates a homophilic (like-like) adhesion. When bound to an identical molecule on another cell, N-CAM can also associate laterally with a fibroblast growth factor receptor and stimulate its tyrosine kinase activity to induce neurite growth thus triggering cellular responses by indirect activation of the recipient.
Selectins. Unlike most adhesion molecules which bind to other proteins, the selectins interact with carbohydrate ligands or mucin complexes on leucocytes and endothelial cells (vascular and haematological systems). Leucocyte-selectin (CD62L) mediates the homing of lymphocytes to lymph nodes. Endothelial-selectin (CD62E) is expressed after activation by inflammatory cytokines; the small basal amount of E-selectin in many vascular beds appears to be necessary for the migration of leucocytes. Platelet-selectin (CD62P) is stored in the alpha granules of platelets and the Weibel–Palade bodies of endothelial cells, but it moves rapidly to the plasma membrane upon stimulation of these cells. All three selectins play a part in leucocyte rolling (p. 63).
Integrins are membrane glycoproteins with α and β subunits which exist as active and inactive forms. The amino acid sequence arginine–glycine–aspartic acid (RGD) is a potent recognition system for integrin binding
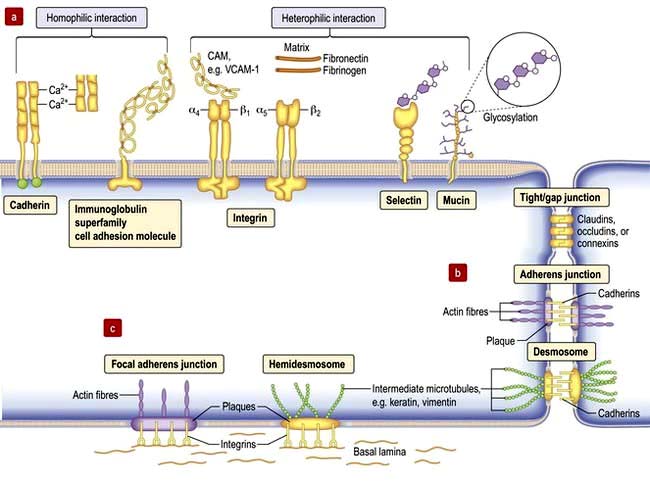
Tight junctions (zonula occludens)
These are mediated by the integral membrane proteins, claudins and occludens; they hold cells together. They form at the top (apical) side of epithelial cells including intestinal, skin and kidney cells, and endothelial cells of blood vessels (Fig. 2.8) to provide a regulated barrier to the movement of ions and solutes through the epithelia or endothelia but also between cells (paracellular transport). Tight junctions also confer polarity to cells by acting as a gate between the apical and the baso-lateral membranes, preventing diffusion of membrane lipids and proteins. Twenty-four claudins (the protein in the junction) are differentially expressed in different cell types to regulate paracellular transport. For example, changes in claudin expression in the kidney nephron correlate with permeability changes. Mutations in claudins 16 (previously named parcellin-1) and 19, expressed in the thick ascending limb in the loop of Henle in the kidney, cause an inherited renal disorder, familial hypomagnesaemia with hypercalciuria and nephrocalcinosis (FHHNC; p. 657).
Gap junctions
Gap junctions (Fig. 2.8) allow low molecular weight substances to pass directly between cells, permitting metabolic and electric coupling (e.g. in cardiomyocytes). Protein channels made of six connexin proteins (as well as claudins and occludens) are aligned between adjacent cells and allow the passage of solutes up to 1000 kDa (e.g. amino acids, sugars, ions, chemical messengers). The channels are regulated by many factors such as intracellular Ca2+, pH, voltage. Gap junctions form in almost all interacting cells, but connexin family members are differentially expressed. Mutant connexins cause many inherited disorders, such as the X-linked form of Charcot–Marie–Tooth disease (GJB1; p. 1147) and are also a major cause of genetic hearing loss (GJB2).
Adherens junctions
Adherens junctions are multiprotein intercellular adhesive structures, prominent in epithelial tissues (Fig. 2.8b). They attach principally to actin microfilaments inside the cell with the aid of multiple additional proteins, and also attach and stabilize microtubules. At the apical sides of epithelial cells a prominent type of adherens junction, the zonula adherens, attaches to the circumferential actin stress fibres. The fascia adherens in cardiac muscle is also an adherens junction. Transmembrane proteins of the cadherin family provide the adhesion through interaction of their extracellular domains. Downregulation of cadherins is a feature of cancer progression in many cells.
Desmosomes (macula adherens)
Desmosomes provide strong attachment between cells and are prominent in tissues subject to stress such as skin and cardiac muscle (see Fig. 2.5, Fig. 2.8b and Fig. 24.1). Like adherens junctions, they are multiprotein complexes, where adhesion is provided by transmembrane cadherin proteins, desmogleins and desmocollins. However, within the cell desmosomes interact principally with intermediate filaments rather than microfilaments and microtubules. Germline mutations in genes encoding desmosomes are a cause of cardiomyopathy with/without cutaneous features and in pemphigus vulgaris and pemphigus foliaceus (p. 1222).
Basement membrane adhesion
Cells adhere (Fig. 2.8c) to non-basal lamina ECM via secreted proteins such as fibronectin and collagen, and to basal lamina proteins via focal adhesion and hemidesmosome multiprotein complexes (e.g. keratin or vimentin). Here, integrins replace cadherins as surface adhesion molecules as the key adhesive proteins. Integrins are transmembrane sensors or receptors, which change shape upon binding to ECM, a process called ‘outside-in’ signalling. Inside the cell, integrins interact with the cytoskeleton and a complex array of over 150 proteins that influence intracellular signalling pathways affecting proliferation, survival, shape, mobility and gene expression.
Outside-in signalling: forms the basis for anoikis or apoptotic death, such as occurs in cancer cells that inappropriately lose cell-substratum adhesion.
Inside-out signalling: intracellular changes can also be communicated extracellularly via integrins whereby intracellular changes cause integrins to change from an inactive to an actively adhesive conformation. This ‘inside-out’ signalling occurs when platelet integrins glycoprotein IIb-IIIa (GPIIb-IIa) are activated to bind fibrinogen at sites of vessel injury, resulting in platelet aggregation (p. 415 and Fig. 8.41).
Defective integrins are associated with many immunological and clotting disorders such as Bernard–Soulier syndrome and Glanzmann’s thrombasthenia (p. 420).
FURTHER READING
De Matteis MA, Luini A. Mendelian disorders of membrane trafficking. N Engl J Med 2011; 365:927–928.
Jean C, Gravelle P, Fournie JJ et al. Influence of stress on extracellular matrix and integrin biology. Oncogene 2011; 30:2697–2706.
Thomason HA, Scothern A, McHarg S et al. Desmosomes: adhesive strength and signalling in health and disease. Biochem J 2010; 429:419–433.
Cellular mechanisms
Cell signalling
Signalling or communication between cells is often via extracellular molecules or ligands which can be proteins (e.g. hormones, growth factors), small molecules (e.g. lipid-soluble steroid hormones such as oestrogen and testosterone) or dissolved gases such as nitric oxide. The signal is usually received by membrane protein receptors, although some signals such as steroid hormones, enter the target cell where they interact with intracellular receptors (Fig. 2.9). Some signalling, especially in the immune system, relies on cell–cell contact, where the signalling molecule (ligand) and receptor are on adjacent cells.
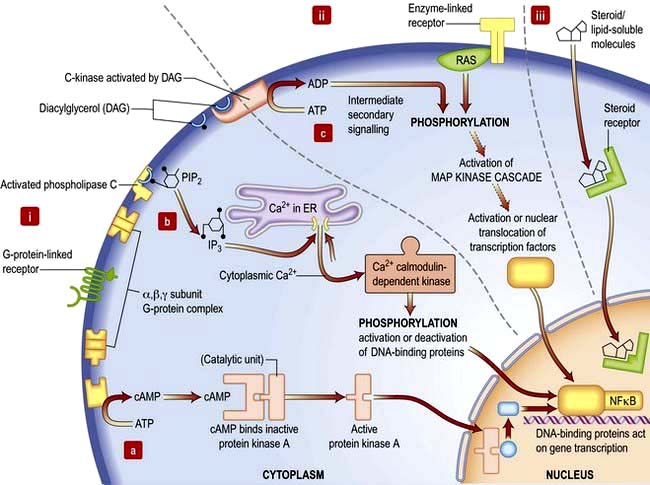
Figure 2.9 Cell signalling. (i) G-protein receptor binds ligand (e.g. hormone) and activates G-protein complex. The G-protein complex can activate three different secondary messengers: (a) cAMP generation; (b) inositol 1,4,5-trisphosphate (IP3) and release of Ca2+; (c) diacylglycerol (DAG) activation of C-kinase and subsequent protein phosphorylation. (ii) Enzyme-linked receptors often dimerize upon ligand binding. Intracellular domains cross-phosphorylate and link to the phosphorylation cascades such as the MAP kinase cascade, via molecules such as Ras. (iii) Lipid-soluble molecules, e.g. steroids, pass through the cell membrane and bind to cytoplasmic receptors, which enter the nucleus and bind directly to DNA.
Receptors transduce signals across the membrane to an intracellular pathway or second messengers to change cell behaviour, often ultimately affecting gene expression (Figs 2.9, 2.10). The membrane-bound receptors fall into three main groups based on downstream signalling pathways:
Ion channel linked receptors (voltage or ligand activated ion channels; see Fig. 2.3). At synaptic junctions between neurones (Fig. 22.1), these receptors open in response to neurotransmitters such as glutamate, epinephrine (adrenaline) or acetylcholine to cause a rapid depolarization of the membrane.
G-protein-linked receptors such as the odorant and light (opsin) family of receptors belong to a large family of seven-pass transmembrane proteins (see Figs 2.2 and 2.9). On activation by ligand G-protein-linked receptors bind a GTP-binding protein (G-protein), which activates adjacent enzyme complexes or ion channels (Figs 2.9 and 22.1). The adjacent enzymes can be adenylcyclase (see below).
Enzyme-linked receptors (Figs 2.2 and 2.9) typically have an extracellular ligand-binding domain, a single transmembrane-spanning region, and a cytoplasmic domain that has intrinsic enzyme activity or which will bind and activate other membrane-bound or cytoplasmic enzyme complexes. This group of receptors is highly variable but many have kinase activity or associate with kinases, which act by phosphorylating substrate proteins usually on a tyrosine (e.g. the platelet-derived growth factor (PDGF) receptor) or a serine/threonine (e.g. the transforming growth factor-beta (TGF-β) receptor).
Signal transduction
Signal transduction from the receptor to the site of action in the cell is mediated by small signalling molecules called second messengers, or by signalling proteins (Fig. 2.9). Changes to activity of signalling proteins by acquired mutation occur in cancer, and many anti-cancer drugs target signalling pathways. For example, the Hedgehog pathway is involved in human development, tissue repair and cancer (Fig. 2.10). Inhibitors of this pathway are being developed for therapeutic interventions. The Wnt pathway is also involved in bone formation (p. 550).
Second messengers include cAMP and lipid-derived inositol triphosphate (IP3) and diacylglycerol (Fig. 2.9). These molecules diffuse from the receptor to bind and change the activity of downstream proteins propagating the signal. cAMP triggers a protein signalling cascade by activating a cAMP-dependent protein kinase. Diacylglycerol activates protein kinase C while IP3 mobilizes calcium from intracellular stores (e.g. from the ER; Fig. 14.9).
G-proteins or GTP-binding proteins are signalling proteins which switch between an active state when GTP is bound and an inactive state when bound to GDP. The most well-known members are the Ras superfamily, comprising Ras, Rho, Rab, Arf and Ran families. Activation of Ras members by somatic mutation is found in ~33% of human cancers. Ras members are often bound downstream of tyrosine kinase receptors, where they transmit signals by activating a cascade of downstream protein kinase activity (Fig. 2.9). Ras signalling molecules have roles in many cellular activities, including regulation of cell cycle, intracellular transport, and apoptosis.
Kinase and phosphatase signalling proteins are enzymes that phosphorylate or dephosphorylate residues on downstream proteins to alter their activity. Chains of kinase activity (phosphorylation cascades) consisting of sequential phosphorylation of proteins can transduce signals from the membrane receptor to the site of action in the cell. The tyrosine kinase receptors phosphorylate each other when ligand binding brings the intracellular receptor components into close proximity (see Fig. 2.9). The inner membrane and cytoplasmic targets of these activated receptor complexes are ras, protein kinase C and ultimately the MAP (mitogen-activated protein) kinase, Janus-Stat pathways or phosphorylation of IκB causing it to release its DNA-binding protein, nuclear factor kappa B (NFκB). For example, activated Ras binds and activates the kinase Raf, the first of a set of three mitogen-activated protein (MAP) kinases, which transmit signals by successive phosphorylation of target proteins which can ultimately effect transcription (Fig. 2.9). Kinases and phosphatases are frequently mutated in cancers. Somatic mutations in one Raf member, B-Raf, occur in ~60% of malignant melanomas (usually the mutation V600E) and are common in other cancers (p. 1225).
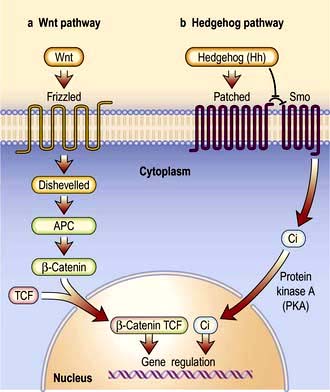
Figure 2.10 Signal transduction showing the Hedgehog and Wnt signalling pathways. (a) Wnt signalling has three pathways: the canonical (β catenin), Wnt/Ca2+ and planar cell polarity pathways. Wnt binds to the frizzled protein and then disheveilled activity via other pathways inhibits phosphorylation of β catenin. This alters gene transcription. TCF, T-cell factor. (b) Hedgehog ligand (Hh) binds to a 12-transmembrane protein receptor Patched (Ptc). This acts as an inhibitor of smoothened (Smo), another transmembrane protein related to the Frizzled family of Wnt receptors. In the presence of Hh the inhibitory effects of Ptc on Smo are removed and Smo is phosphorylated by protein kinase A and other kinases. This prevents cleavage of Ci which enters the nucleus inducing the transcription of Hh target genes. Ci, cubitus interruptus, a zinc finger protein.
Nuclear control
DNA and RNA structure
Hereditary information is contained in the sequence of the building blocks of double-stranded deoxyribonucleic acid (DNA) (Fig. 2.11). Each strand of DNA is made up of a deoxyribose-phosphate backbone and a series of purine (adenine (A) and guanine (G)) and pyrimidine (thymine (T) and cytosine (C)) bases, and because of the way the sugar phosphate backbone is chemically coupled, each strand has a polarity with a phosphate at one end (the 5′ end) and a hydroxyl at the other (the 3′ end). The two strands of DNA are held together by hydrogen bonds between the bases. A can only pair with T, and G can only pair with C, therefore each strand is the antiparallel complement of the other (Fig. 2.11b). This is key to DNA replication because each strand can be used as a template to synthesize the other.
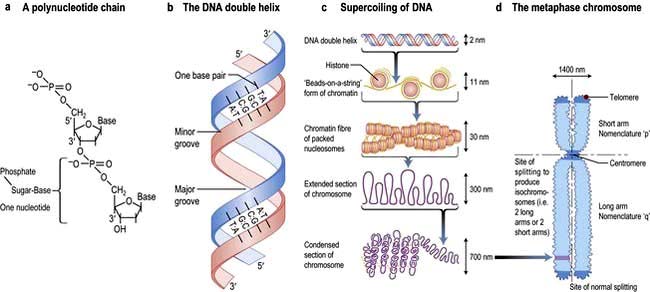
Figure 2.11 DNA and its structural relationship to human chromosomes. (a) A polynucleotide strand with the position of the nucleic bases indicated. Individual nucleotides form a polymer linked via the deoxyribose sugars. The 5′ carbon of the heterocyclic sugar structure is coupled to a phosphate molecule. The 3′ carbon couples to the phosphate on the 5′ carbon of ribose of the next nucleotide forming the sugar-phosphate backbone of the nucleic acid. The 5′ to 3′ linkage gives orientation to a sequence of DNA. (b) Double-stranded DNA. The two strands of DNA are held together by hydrogen bonds between the bases. T always pairs with A, and G with C. The orientation of the complementary single strands of DNA (ssDNA) is thus complementary and anti-parallel, i.e. one will be 5′ to 3′ while the partner will be 3′ to 5′. The helical 3D structure has major and minor grooves and a complete turn of the helix contains 12 base-pairs. These grooves are structurally important, as DNA-binding proteins predominantly interact with the major grooves. (c) Supercoiling of DNA. The large stretches of helical DNA are coiled to form nucleosomes and further condensed into the chromosomes that can be seen at metaphase. DNA is first packaged by winding around nuclear proteins – histones – every 180 bp. This can then be coiled and supercoiled to compact nucleosomes and eventually visible chromosomes. (d) At the end of the metaphase DNA replication results in a twin chromosome joined at the centromere. This picture shows the chromosome, its relationship to supercoiling, and the positions of structural regions: centromeres, telomeres and sites where the double chromosome can split. Chromosomes are assigned a number or X or Y, plus short arm (p) or long arm (q). The region or subregion is defined by the transverse light and dark bands observed when staining with Giemsa (hence G-banding) or quinacrine and numbered from the centromere outwards. Chromosome constitution = chromosome number + sex chromosomes + abnormality; e.g. 46XX = normal female; 47XX+21 = Down’s syndrome; (trisomy 21) 46XYt (2;19) (p21; p12) = male with a normal number of chromosomes but a translocation between chromosome 2 and 19 with breakages at short-arm bands 21 and 12 of the respective chromosomes.
The two strands twist to form a double helix with a major and a minor groove, and the large stretches of helical DNA are coiled around histone proteins to form nucleosomes (Fig. 2.11c). They can be condensed further into the chromosomes that can be visualized by light microscopy at metaphase (see below; Fig. 2.11, Fig. 2.19).
To express the information in the genome, cells first transcribe the code into the single strand ribonucleic acid (RNA). RNA is similar to DNA in that it comprises four bases A, G and C but with uracil (U) instead of T, and a sugar phosphate backbone with ribose instead of deoxyribose. Several types of RNA are made by the cell. Messenger RNA (mRNA) codes for proteins that are translated on ribosomes. Ribosomal RNA (rRNA) is a key catalytic component of the ribosome and amino acids are delivered to the nascent peptide chain on transfer RNA (tRNA) molecules. There are also a variety of RNAs that regulate gene expression or RNA processing. These include microRNA (miRNA) and small interfering RNA (siRNA) (see p. 27) that typically bind to a subset of mRNAs and inhibit their translation, or initiate their degradation, respectively. Other non-coding RNAs are involved in X-inactivation and telomere maintenance or RNA splicing and maturation.
DNA transcription
A gene is a length of DNA (usually 20–40 kb but the muscle protein dystrophin is encoded by 2.4 Mb) that contains the codes for a polypeptide sequence. Three adjacent nucleotides (a codon) specify a particular amino acid, such as AGA for arginine. There are only 20 common amino acids, but 64 possible codon combinations make up the genetic code. This redundancy means that most amino acids are encoded by more than one triplet and other codons are used as signals for initiating or terminating polypeptide-chain synthesis.
RNA is transcribed from the DNA template by an enzyme complex of more than one hundred proteins including RNA polymerase, transcription factors and enhancers. Promoter regions upstream of the gene dictate the start point and direction of transcription. The complex binds to the promoter region, the nucleosomes are remodelled to allow access, and a DNA helicase unwinds the double helix. RNA, like DNA, is synthesized in the 5′ to 3′ direction as ribonucleotides are added to the growing 3′ end of a nascent transcript. RNA polymerase does this by base-pairing the ribonucleotides to the DNA template strand running in the 3′ to 5′ direction. Messenger RNA is modified as it is synthesized (Fig. 2.12). It is capped at the 5′ end with a modified guanine that is required for efficient processing of the mRNA and efficient translation, and introns are spliced from the nascent chain. Finally, the 3′ of the mRNA is modified with up to 200 A nucleotides by the enzyme poly-A polymerase. This 3′ poly-A tail is essential for nuclear export (through the nuclear pores), stability and efficient translation into protein by the ribosome.
Human protein coding sequences (exons) are interrupted by intervening sequences that are non-coding (introns) at multiple positions (Fig. 2.12). These have to be spliced from the nascent message in the nucleus by an RNA/protein complex called a spliceosome. Differential splicing describes the process by which two or more introns and their intervening exons are spliced from the mRNA. This contributes significantly to the complexity of the human transcriptome as proteins translated from these messages lack particular domains. This exon skipping can produce different protein activities.
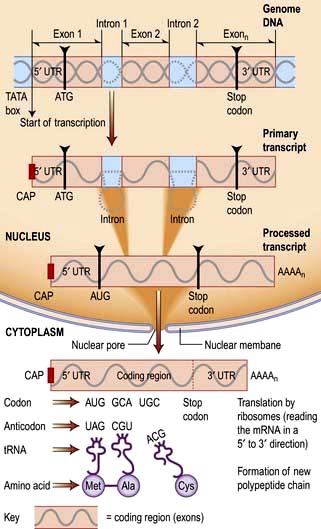
Figure 2.12 Transcription and translation (DNA to RNA to protein). RNA polymerase creates an RNA copy of the DNA gene sequence. This primary transcript is processed: capping of the 5′ free end of the mRNA precursor involves the addition of an inverted guanine residue to the 5′ terminal which is subsequently methylated, forming a 7-methylguanosine residue.
The 3′ end of mRNA defined by the sequence AAUAAA acts as a cleavage signal for an endonuclease, which cleaves the growing transcript about 20 bp downstream from the signal. The 3′ end is further processed by a poly-A polymerase which adds adenosine residues to the 3′ end, forming a poly-A tail (polyadenylation).
Splicing out of the introns then produces the mature mRNA, which is trafficked out of the nucleus via nuclear pores. Ribosomal subunits assemble on the mRNA moving along 5′ to 3′.
With the transport of amino acids to their active sites by specific tRNAs, the complex translates the code, producing the peptide sequence.
Control of gene expression
The genome of all cells in the body encodes the same genetic information, yet different cell types express a very different subset of proteins and respond to external signals to switch on a new set of genes or to switch off a pathway. Gene expression can be controlled at many steps from transcription to protein degradation. However, for many genes transcription is the key point of regulation. This is controlled primarily by proteins which bind to short sequences within the promoter regions that either repress or activate transcription, or to more distant sequences where proteins bind to enhance expression. These transcription factors and enhancers are often the end points of signalling pathways that transduce extracellular signals to changes in gene expression (Fig. 2.9).
Often this involves the translocation of an activated factor from the cytoplasm to the nucleus. In the nucleus the DNA binding proteins recognize the shape and position of hydrogen bond acceptor and donor groups within the major and minor grooves of the double helix (i.e. the double helix does not need to be unwound). There are several classes of DNA binding protein that differ in the protein structural motif that allows them to interact with the double helix. These primarily include helix-turn-helix, zinc finger and leucine zipper motifs, although protein loops and β-sheets are used by some proteins. More permanent control of gene expression patterns can be achieved epigenetically. These are modifications (typically methylation and/or acetylation) of the DNA, or the histones of the nucleosome, that silence genes. Epigenetic modification is also heritable meaning that a dividing liver cell, for example, can give rise to two daughter cells with the same epigenetic signals such that they express the appropriate transcriptome for a liver cell. Epigenetic change forms the basis of genetic imprinting (see p. 42).
Most of the genome is transcribed but only a minority of transcripts encode proteins (see Human Genetics, p. 34). The non-coding RNAs (ncRNAs) include a group that regulate gene expression (see DNA and RNA structure). miRNAs and siRNAs are short ncRNAs (19–29 bp) that are known to regulate expression of approximately 30% of genes by degradation of transcripts or repression of protein synthesis. With further annotation of the genome a growing range of additional regulatory ncRNA classes are being identified, many of which control gene expression by epigenetic mechanisms.
The cell cycle and mitosis
The cell duplication cycle has four phases, G1, S, G2 and mitosis (Fig. 2.13), and takes about 20–24 hours to complete for a rapidly dividing adult cell. G1, S and G2 are collectively known as interphase during which the cells double in mass (the two gap phases are used for growth) and duplicate their 46 chromosomes (S phase). Mitosis describes, in four sub-phases (prophase, metaphase, anaphase and telophase), the process of chromosome separation and nuclear division before cytokinesis (division of the cytoplasm into two daughter cells).
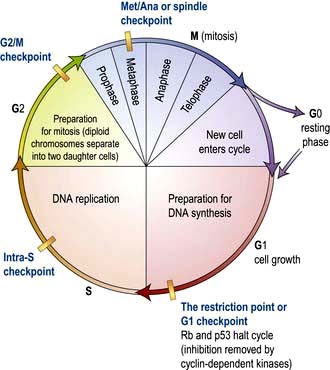
Figure 2.13 The cell cycle. Cells are stimulated to leave non-cycle G0 to enter G1 phase by growth factors. During G1, transcription of the DNA synthesis molecules occurs. Rb is a ‘checkpoint’ (inhibition molecule) between G1 and S phases and must be removed for the cycle to continue. This is achieved by the action of the cyclin-dependent kinase produced during G1. During the S phase, any DNA defects will be detected and p53 will halt the cycle (see p. 46). Following DNA synthesis (S phase), cells enter G2, a preparation phase for cell division. Mitosis takes place in the M phase. The new daughter cells can now either enter G0 and differentiate into specialized cells, or re-enter the cell cycle.

Phases of mitosis. DNA is in blue and the microtubules of the cytoskeleton and mitotic spindle in green. The red marker CENP-V labels kinetochores in prometaphase and metaphase, the mid-zone in anaphase and the mid-body in cytokinesis.
(Courtesy of Tadeu AM, Ribeiro S, Johnston J et al. CENP-V is required for centromere organization, chromosome alignment and cytokinesis. The EMBO Journal 2008; 27:2510–2522.)
Synthesis phase; DNA replication
DNA synthesis is initiated simultaneously at multiple replication forks in the genome and is catalysed by a multienzyme complex. The key components of the replication machinery are:
DNA helicase which hydrolyses ATP to unwind the double helix and expose each strand as a template for replication. The two strands are antiparallel, and because DNA can only be extended by addition of nucleotide triphosphates to the 3′-hydroxyl end of the growing chain, replication of each strand must be treated differently. For one strand, called the leading template strand, the replication fork is moving in a 3′ to 5′ direction along the template, meaning that the newly synthesized strand is being synthesized in a 5′ to 3′ direction.
DNA primase synthesizes a short (~10 nucleotide) RNA molecule annealed to the DNA template which acts as a primer for DNA polymerase.
DNA polymerase extends the primer by adding nucleotides to the 3′-end. For the leading template strand, the RNA primer is only required to initiate synthesis once and polymerization continues just behind the replication fork. For the antiparallel strand, the template is being exposed in a 5′ to 3′ direction and DNA primase is required to synthesize RNA primers every ~200 nucleotides to prime DNA synthesis in the opposite direction to the replication fork. To allow for this, the synthesis against this template is delayed and so it is called the lagging strand and requires more of the strand to be exposed for DNA primase and DNA polymerase to engage.
Single-strand DNA binding proteins are required to bind to the exposed single-strand DNA and stabilize it in single-strand form. Once DNA polymerase has extended the new strand to cover the 200 nucleotides between each RNA primer (the single-strand RNA/DNA hybrid is called an Okazaki fragment).
The phases of mitosis
Prophase. The two sister chromatids (the replicated chromosomes held together by a protein complex called a kinetochore) condense in the nucleus. The two centrosomes between which the microtubules of the mitotic spindle will form move apart in the cytoplasm. At the end of prophase (sometimes known as prometaphase), the nuclear membrane breaks down and the spindle microtubules attach to the kinetochores.
Metaphase. The chromosomes are aligned on a central plane with the two centrosomes at opposite poles. The sister chromatids are attached to microtubules from different centrosomes via the kinetochore.
Anaphase. The sister chromatids separate and are pulled in opposite directions as the microtubules shorten towards their respective spindle poles.
Telophase. Each set of daughter chromosomes are held at a spindle pole and the nuclear envelope reforms around the genome of each new daughter cell.
Cytokinesis
Binary fission of the cytoplasm begins in telophase before the completion of mitosis with the appearance of a ring of actin and myosin filaments around the equator of the cell. Cytokinesis is completed as the ring contracts to create a cleavage furrow and separate the two daughter cells.
Control of the cell cycle and checkpoints
Cells can exit the cell cycle and become quiescent. Indeed most terminally-differentiated adult cells are in a phase termed G0 in which the cycling machinery is switched off. In some cell types the switch is irreversible (e.g. in neurones), but others, like hepatocytes, retain the ability to re-enter the cell cycle and proliferate. This gives the liver a significant ability to regenerate following damage.
Cyclin-dependent kinases (Cdks), Retinoblastoma (Rb) and p53
Progression through the cell cycle is tightly controlled and punctuated by three key checkpoints when the cell interprets environmental and cellular signals to determine whether it is appropriate or safe to proceed (Fig. 2.13). The switches that allow progression beyond these checkpoints are a family of small protein complexes called cyclin-dependent kinases (Cdks) that phosphorylate serines or threonines in key target proteins at each stage. It is the regulatory cyclin subunit of the Cdks that oscillates during the cell cycle (the actual kinase domain may be present throughout but only activated by the transient expression of its cognate cyclin).
Checkpoints
The restriction point (G1 checkpoint)
The restriction point works to ensure the cell cycle does not progress into S-phase unless growth conditions are favourable and the genomic DNA is undamaged. The cyclin-cdk complexes active early in S-phase are denoted S-Cdk (cyclin A with Cdk1 or Cdk2).
to phosphorylate their target proteins to initiate helix unwinding of the DNA at origins of replication allowing the replication complex to begin DNA synthesis
to prevent re-initiation at the same origin during the same cell cycle (because it would be deleterious to copy parts of the genome more than once).
S-Cdks are themselves subject to regulation by G1-Cdk (cyclin D1–3 with Cdk4 or Cdk5) and G1/S-Cdk (cyclin E with Cdk2), both of which can stimulate cyclin A synthesis. Two major cancer pathways converge on this checkpoint via the cyclin-Cdks:
G1-Cdk responds positively to mitogenic (progrowth) environmental signals like platelet-derived growth factor (PDGF) or epidermal growth factor (EGF). Activated G1-Cdk phosphorylates and inactivates the retinoblastoma (Rb) protein which releases the transcription factor E2F to stimulate G1/S-Cdk and S-Cdk synthesis that are necessary for progression.
G1/S-Cdk and S-Cdk are also responsive to DNA damage via the p53 pathway. On DNA damage, the transcription factor p53 is phosphorylated and stimulates transcription of the p21 gene. p21 protein is an inhibitor of both G1/S-Cdk and S-Cdk. Both the Rb and p53 are regulators of the restriction-point. Loss of function of either disables aspects of the negative control pathways. Rb and p53 are commonly mutated in cancer and both are therefore considered ‘tumour suppressor genes’ (see p. 46).
G2/M checkpoint
The G2/M checkpoint prevents entry into mitosis in the presence of DNA damage or non-replicated DNA. M-Cdk (cyclin B with Cdk1) accumulates towards the end of G2 but is inactive. Activation of M-Cdk is complex and includes dephosphorylation of M-Cdk by the phosphatase Cdc25. Activated M-Cdk has three roles at the G2/M checkpoint:
To achieve this M-Cdk phosphorylates a number of proteins at this checkpoint. The phosphorylation of condensin is probably necessary to coil the DNA and initiate chromosome condensation, phosphorylation of nuclear pore and lamina proteins probably initiates breakdown of the nuclear membrane, and phosphorylation of microtubule-associated proteins and catastrophe factors are both required for assembly of the mitotic spindle. DNA damage and the presence of non-replicated DNA negatively regulate M-Cdk and prevent entry into mitosis. The kinases that phosphorylate p53 in response to DNA damage and block progression through the restriction point can also phosphorylate and inhibit Cdc25, inactivating M-Cdk. Thus DNA damage also blocks cell cycle progression at this checkpoint.
Met/Ana checkpoint
The metaphase to anaphase checkpoint is regulated by protein degradation. The anaphase-promoting complex APC/C, which is activated by Cdc20, is a ubiquitin ligase that transfers a small protein, ubiquitin, to other proteins marking them for degradation. The primary targets are securin, and the S- and M-cyclins of the cyclin-Cdks present at the start of mitosis.
Securin is an inhibitor of a protease called ‘separase’, which, on release, digests the cohesin that holds the two sister chromatids together allowing them to be pulled apart by the mitotic spindle. APC/C activity is tightly controlled but the complete mechanism remains obscure. It includes a negative feedback loop involving M-Cdk which phosphorylates APC/C and increases its affinity for Cdc20. Thus M-Cdk induces its own inactivation by activating the ligase that ensures degradation of its own cyclin. APC/C is also negatively-regulated via an unknown pathway by kinetochores that remain unattached to the mitotic spindle, thus chromatid separation is inhibited until all 46 duplicated chromosomes are on the spindle.
Synthesis and secretion
Protein translation
The mature mRNA is transported through the nuclear pore into the cytoplasm for translation into protein by ribosomes (Fig. 2.12).
The two subunits of ribosomes (the 40S and 60S) are formed in the nucleolus from multiple proteins and several rRNAs, before transport to the cytoplasm.
In the cytoplasm, the two subunits interact on an mRNA molecule, usually via ribosome binding sites encoded in the untranslated 5′ region of the message. The mRNA is then pulled through the ribosome until a translation initiation codon is encountered (usually an AUG coding for methionine).
The triplets of adjacent bases of the mRNA (codons) are exposed and recognized by complementary sequences, or anti-codons, in tRNA molecules that dock on the ribosome.
Each tRNA molecule carries an amino acid specific to the anti-codon. As the mRNA is pulled through the ribosome in the 5′ to 3′ direction, amino acids are transferred from tRNA molecules and sequentially linked to the carboxy-terminus of the growing polypeptide by the peptidyl transferase activity of the ribosome.
The poly-A tail of the mRNA is not translated (3′ untranslated region) and is preceded by a translational stop codon, UAA, UAG or UGA.
Translation of secreted or integral membrane proteins is different. Typically, the first few amino acids of the amino terminus of the nascent polypeptide exit the ribosome and are recognized by a signal recognition particle (SRP) that stops translation until the complex is docked onto the ER via the SRP receptor. Translation then continues and the protein is translocated into or through the ER membrane via the Sec61 translocation complex as it is being synthesized (co-translational transport).
Protein structure
The amino acid sequence of a polypeptide chain (its primary structure) ultimately determines its shape. The weak bonds (hydrogen bonds, electrostatic and van der Waals interactions) formed between the side chains and/or the peptide backbone of the different amino acids provide the secondary structure (α-helices, β-strands, loops). These are in turn folded into a three-dimensional, tertiary structure to provide functional protein domains of 40–350 amino acids. The modular nature of domains allows their functionality to be combined in protein complexes of different proteins or, by gene fusion and/or exon skipping, into new multidomain single polypeptides. This final level of organization is the quaternary structure.
In cells, the folding of polypeptides into fully functional proteins is facilitated by an assortment of molecular chaperones, e.g. heat shock proteins (HSP), which bind to partially folded polypeptides and prevent the formation of inappropriate bonds.
Lipid synthesis
Fatty acids, molecules with a hydrocarbon chain with 4–28 carbons, are central to cellular life and human metabolism. They form the hydrophobic moiety of membrane lipids (see p. 17), they are precursors for short-lived, near acting lipid paracrines such as leukotrienes and prostaglandins, and they are energy stores particularly in the form of triglycerides.
Fatty acids as an energy store
Long chain fatty acids can be incorporated into triglycerides, which are relatively inert and lipophilic compounds that can be stored as fat droplets in cells (particularly adipocytes). When blood glucose is low, these triglycerides are hydrolysed, secreted into the bloodstream as free fatty acids, and distributed as an energy source for the cells of the body. In the recipient cell, fatty acids are metabolized in the mitochondrion to produce acetyl-CoA for the Krebs cycle (see p. 31). This is a particularly efficient storage system as gram for gram, triglyceride produces six times the amount of energy than glycogen and occupies less volume in the cell.
Essential fatty acids
Unsaturated fatty acids (UFAs) have carbon–carbon double bonds that are introduced by desaturase enzymes by removal of the hydrogens. The remaining hydrogens on either side of the double bond can be on the same side of the chain (cis) or on opposite sides (trans). The acyl chain of cis UFAs is kinked, which influences the packing of membrane lipids and the function of the membrane barrier. Humans have desaturases that can introduce some double bonds but lack a desaturase required to make linoleic acid or alpha-linolenic acid. These fatty acids have double bonds 6 and 3 carbons from their respective omega ends (the methyl end of the chain). Omega-6 and omega-3 UFAs are essential fatty acids that must be obtained from the diet (see Ch. 5). They are precursors of arachidonic acid and eicosapentaenoic acid, respectively, from which cyclo-oxygenase 1 and 2 (cox-1 and 2) (see p. 826) produce the paracrines that play a role in inflammation, pain, fever, and airway constriction.
Intracellular trafficking, exocytosis (secretion) and endocytosis
The molecular composition, the lipids, proteins and cargo of each type of organelle is different and distinct from the plasma membrane, yet there is a continuous flux of material between many of the different compartments. Much of this flow is via vesicles that bud from one compartment to fuse with another. It is regulated by an array of lipids and membrane proteins (coat proteins, adaptors, signalling molecules and fusion proteins).
Budding of vesicles involves recruitment of coat proteins and adaptors to the membrane. Thus, a receptor on binding to its ligand may stimulate a kinase to phosphorylate neighbouring phosphatidyl-inositol, or activate an associated small GTPase (Arf or SarI), increasing their affinities for a coat protein or adaptor. The coat protein (clathrin at the plasma membrane, COPI at the Golgi, COPII in the ER) forms a mesh around the developing vesicle (Fig. 2.4). Fully-formed vesicles normally shed their coat (often triggered by GTP hydrolysis by the GTPase), leaving the adaptor/receptor/lipid combination to identify the vesicle.
Targeting and trafficking is mediated by a different family of GTPases (Rab proteins) that recognize the combination of vesicle surface markers and targets them appropriately. Once activated by GTP, the Rab proteins are lipid-anchored to the vesicle where they engage with a diverse pool of Rab effectors. These can be motor proteins that traffic the vesicle along the microfilament and microtubule fibres of the cytoskeleton, or tethering proteins on the target membrane.
Fusion is accomplished by membrane-fusion SNARES (Fig. 2.4). The v-SNARE protein on the vesicle (often associated with the Rab effector) interacts with the t-SNARE on the target membrane to facilitate fusion of the two compartments (distinct combinations of v-SNARE and t-SNARE specify particular pathways).
Vesicles that fuse with the plasma membrane replenish membrane lipids and proteins and also release cargo extracellularly (exocytosis; Fig. 2.4). Clathrin-coated vesicles are also used to recycle protein from the plasma membrane, and import extracellular cargo to internal compartments called endosomes. From endosomes cargo such as receptors is recycled back to the membrane, or cargo is sent for degradation in the lysosome in the process called endocytosis.
Pinocytosis and phagocytosis (see p. 19) are forms of endocytosis. Endocytosis can also occur via plasma membrane microdomains or lipid rafts called caveolae which pinch in to form uncoated vesicles that fuse with endosomes. Endocytosed vesicles can also be transported across the cell in a process called transcytosis. For example, cargo can be endocytosed at the apical surface of an epithelial cell and exocytosed across the basolateral membrane.
Energy production
As food is catabolized, cells temporarily store the energy released in carrier molecules. These include reduced nicotinamide adenine dinucleotide and reduced nicotinamide adenine dinucleotide phosphate (NADH and NADPH, respectively) that release energy as they are oxidized to NAD+ and NADP+. The molar ration of NAD+ to NADH is typically high in a cell because NAD+ is used as an oxidizing agent in catabolic pathways. In contrast, the molar ratio of NADP+ to NADPH is typically low because NAPH is used as a reducing agent in anabolic reactions. The most versatile carrier is adenosine triphosphate (ATP). ATP can be hydrolysed to ADP and phosphate (Pi) and the release of energy used to power less favourable reactions.
The lipids and polysaccharides provide the most energy in a human diet, although protein can also be used. Enzymes secreted into the gut break down these polymers to their respective building blocks of fatty acids and sugars that are absorbed by the apical membrane of the gut epithelium (the transporters involved in the transcellular transport of glucose across the enterocyte are described in Figure 6.24). Fatty acids and sugars are further catabolized by enzyme pathways inside the cell to produce an array of activated carrier molecules.
Glycolysis
The six-carbon glucose is primarily catabolized in 10 steps by enzymes of the glycolytic pathway (see Fig. 8.25) to produce two three-carbon molecules of the carboxylic acid pyruvate. Glycolysis occurs in the cytosol and the first three steps actually consume energy (2×ATP), but the remaining six steps generate 4×ATP and 2×NADH, giving a net return of 2×ATP and 2×NADH.
Pyruvate is central to metabolism. It can be catabolized as fuel for the Krebs cycle and oxidative phosphorylation. It can regulate the cellular redox state by dehydration to lactate and regeneration of NADH. It can be a precursor for anabolism of fuels (glucose, glycogen and fatty acids) or amino acids, via conversion to alanine. The fate of pyruvate depends on the environmental conditions and needs of the cell.
Under anaerobic conditions, e.g. in skeletal muscle following prolonged exercise where NAD+ must be regenerated (because it is needed as an oxidizing reagent in the catabolism of glucose), pyruvate is reduced to lactate as NADH is oxidized to NAD+ in a ‘redox’ reaction catalysed by lactate dehydrogenase. This allows the muscle to continue to catabolize glucose to generate ATP under conditions in which metabolic oxygen is limiting. The lactate is secreted into the bloodstream and is ultimately metabolized by the liver back into glucose by gluconeogenesis consuming 6×ATP in the process. This cycle of anaerobic respiration that produces lactate in muscle, which is released into the bloodstream to be taken up by the liver for reconversion to glucose is known as the Cori cycle.
Krebs cycle
Under aerobic conditions, the fate of pyruvate is different. It is transported into the mitochondrion, where it is decarboxylated to acetyl-CoA and NADH, with CO2 released as a waste product. The acetyl-CoA formed from pyruvate (or from catabolism of amino acids or β-oxidation of fatty acids) enters the Krebs cycle in the matrix of the mitochondrion, where it is condensed with the 4-carbon oxaloacetate to form the 6-carbon citric acid. Citric acid has three carboxylate groups providing the alternative names for the Krebs cycle (the citric acid or tricarboxylic acid cycle). In eight reactions, the Krebs cycle oxidizes two of the four carbons of citric acid to 2×CO2, regenerates oxaloacetate to enter the next cycle, and in the process, provides enough energy to produce 1×GTP, 3×NADH and 1× reduced flavin adenine dinucleotide (FADH2, a carrier of electrons much like NADH). The latter two products feed their electrons into the electron transport chain where they are used to make ATP from ADP and Pi, a process known as oxidative phosphorylation.
In addition to energy production, glycolysis and the Krebs cycle provide precursors for the anabolism of amino acids, cholesterol, fatty acids, nucleotides amino sugars and lipids.
Oxidative phosphorylation
The activated carriers NADH and FADH2 carry high energy electrons as hydride (a proton H+ and two electrons), which are donated to complexes of the electron transport chain, in the process regenerating NAD+ and FAD as oxidizing agents for continued oxidative metabolism. The electrons are passed down the series of inner membrane proteins of the mitochondrion, moving to a lower energy state at each step until they are finally transferred to oxygen to produce water (hence the requirement for molecular oxygen). The energy released by the electrons is used to efflux protons (H+) into the inter-membrane space, setting up an H+ electrochemical gradient, which the ATP synthase (or F0F1 ATPase), another integral membrane protein, uses to drive the formation of ATP from ADP and Pi. Oxidative phosphorylation produces the bulk of the cellular ATP. A single molecule of glucose is able to produce a net yield of approximately 30×ATP. Only two of these come from glycolysis directly.
Cellular degradation and death
Cell dynamics
Cell components are continually being formed and degraded, and most of the degradation steps involve ATP-dependent multienzyme complexes. Old cellular proteins are mopped up by a small cofactor molecule called ‘ubiquitin’, which interacts with these worn proteins via their exposed hydrophobic residues. Ubiquitin is a small 8.5 kDa regulating protein present universally in all living cells. Cells mark the destruction of a protein by attaching molecules to the protein. This ‘ubiquitination’ signals the protein to move to lysosomes or proteosomes for destruction. A complex containing more than five ubiquitin molecules is rapidly degraded by a large proteolytic multienzyme array termed ‘26S proteosome’. Ubiquitin also plays a role in regulation of the receptor tyrosine kinase in the cell cycle and in repair of DNA damage. The failure to remove worn proteins can result in the development of chronic debilitating disorders. For example, Alzheimer’s and frontotemporal dementias are associated with the accumulation of ubiquinated proteins (prion-like proteins), which are resistant to ubiquitin-mediated proteolysis. Similar proteolytic-resistant ubiquinated proteins give rise to inclusion bodies found in myositis and myopathies. This resistance can be due to point mutation in the target protein itself (e.g. mutant p53 in cancer; see p. 46) or as a result of an external factor altering the conformation of the normal protein to create a proteolytic-resistant shape, as in the prion protein of variant Creutzfeldt–Jakob disease (vCJD). Other conditions include von Hippel–Lindau syndrome (p. 634) and Liddle’s syndrome (p. 653).
Free radicals
A free radical is any atom or molecule which contains one or more unpaired electrons, making it more reactive than the native species. The major free radical species produced in the human body are the hydroxyl radical (OH), the superoxide radical (O2–) and nitric oxide (NO).
Free radicals have been implicated in a large number of human diseases. The hydroxyl radical is by far the most reactive species but the others can generate more reactive species as breakdown products. When a free radical reacts with a non-radical, a chain reaction ensues which results in direct tissue damage by membrane lipid peroxidation. Furthermore, hydroxyl radicals can cause genetic mutations by attacking purines and pyrimidines. Superoxide dismutases (SOD) convert superoxide to hydrogen peroxide and are thus part of an inherent protective antioxidant mechanism. Patients with dominant familial forms of amyotrophic lateral sclerosis (motor neurone disease) have mutations in the gene for Cu-Zn SOD-1 catalases. Glutathione peroxidases are enzymes that remove hydrogen peroxide generated by SOD in the cell cytosol and mitochondria.
Free radical scavengers bind reactive oxygen species. Alpha-tocopherol, urate, ascorbate and glutathione remove free radicals by reacting directly and non-catalytically. Severe deficiency of α-tocopherol (vitamin E deficiency) causes neurodegeneration. There is evidence that cardiovascular disease and cancer can be prevented by a diet rich in substances that diminish oxidative damage (p. 211). The principal dietary antioxidants are vitamin E, vitamin C, β-carotene and flavonoids.
Heat shock proteins
The heat shock response is a highly conserved and ancient response to tissue stress (chemical and physical) that is mediated by activation of specific genes leading to the production of specific heat shock proteins (HSPs). The diverse functions of HSPs include the transport of proteins in and out of specific cell organelles, acting as molecular chaperones (the catalysis of protein folding and unfolding) and the degradation of proteins (often by ubiquitination pathways). As well as heat, cytotoxic chemicals and free radicals can trigger HSP expression. The unifying feature, which leads to the activation of HSPs, is the accumulation of damaged intracellular protein. Tumours have an abnormal thermotolerance, which is the basis for the observation of the enhanced cytotoxic effect of chemotherapeutic agents in hyperthermic subjects. The HSPs are expressed in a wide range of human cancers and have been implicated in tumour cell proliferation, differentiation, invasion, metastasis, cell death and immune response.
Autophagy
Cells continually recycle material. For example, cellular proteins targeted for degradation can be ubiquitinated and degraded by the proteasome (p. 31), and mRNA can be de-tailed and degraded by the exosome or decapping complex. Cells respond to stresses like starvation by degrading much of their cytoplasmic contents in order to recycle components and survive.
Cells achieve this by autophagy, during which everything from sugars, lipids, protein aggregates, ribosomal particles and organelles are enclosed in a double membrane (a vesicle forms a cup shape to extend around the material). The new autophagosome then fuses with a lysosome leading to degradation of the contents by acid hydrolysis. Autophagic induction is complex and still not completely understood, but it has roles in tumour growth, elimination of intracellular microorganisms, and elimination of toxic misfolded proteins such as those that give rise to neurodegenerative disorders. Autophagy can suppress apoptotic cell death induced by chemotherapy, while excessive autophagy in response to starvation can lead to autophagic cell death.
Necrotic cell death
In necrotic cell death, external factors (e.g. hypoxia, chemical toxins, injury) damage the cell irreversibly. Necrotic cell death is associated with ischaemia and stroke, cardiac failure, neurodegeneration, pathogen infection and occurs in the centre of tumours deprived of a blood supply. Characteristically, there is an influx of water and ions, after which the cell and its organelles swell and rupture. Lysosomal proteases released into the cytosol cause widespread degradation. There is a rise in cytosolic calcium, increased reactive oxygen species (ROS), intracellular acidification and ATP depletion. Necrosis is regulated and the cellular processes and activated pathways are still being investigated. Necrotic cell lysis induces acute inflammatory responses owing to the release of lysosomal enzymes into the extracellular environment.
Apoptotic cell death
Most terminally-differentiated cells can no longer replicate and eventually die by apoptosis, a type of programmed cell death. Apoptosis occurs through the deliberate activation of cellular pathways, which function to cause cell suicide. In contrast to necrosis, apoptosis is orderly. Cells are destroyed and their remains phagocytosed by adjacent cells and macrophages without inducing inflammation. Apoptosis is essential for many life processes, including tissue maintenance in the adult, tissue formation in embryogenesis, and normal metabolic processes such as autodestruction of the thickened endometrium to cause menstruation in a non-conception cycle. Cells which have accumulated irreparable DNA damage from toxins or ultraviolet radiation also trigger apoptosis via p53 protein to prevent replication of mutations or progression to cancer. Many chemotherapy and radiotherapy regimens work by triggering apoptotic pathways in the tumour cell.
Apoptosis has characteristic features:
Shrinkage of the cell and its nucleus
Chromatin aggregation into membrane-bound vesicles called apoptotic bodies
Apoptosis requires proteases called caspases whose action is very tightly regulated. Caspases not only destroy cell organelles, they cleave nuclear lamin causing collapse of the nuclear envelope and activate, through cleavage, nucleases that degrade DNA. Caspase activation can be achieved by:
signals from outside the cell (the extrinsic apoptotic pathway or the death receptor pathway) and
internal signals, such as DNA damage (the intrinsic apoptotic pathway or the mitochondrial pathway) (Fig. 2.14).
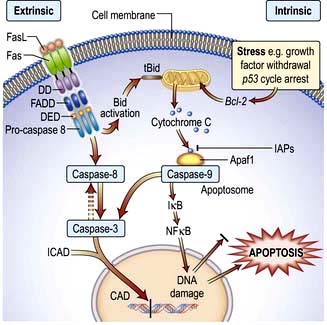
Figure 2.14 Extrinsic and intrinsic apoptotic signalling network. The Fas protein and Fas ligand (FasL) are two proteins that interact to activate an apoptotic pathway. Fas and FasL are both members of the TNF (tumour necrosis factor) family – Fas is part of the transmembrane receptor family and FasL is part of the membrane-associated cytokine family. When the homotrimer of FasL binds to Fas, it causes Fas to trimerize and brings together the death domains (DD) on the cytoplasmic tails of the protein. The adaptor protein, FADD (Fas-associating protein with death domain), binds to these activated death domains and they bind to pro-caspase 8 through a set of death effector domains (DED). When pro-caspase 8s are brought together, they transactivate and cleave themselves to release caspase 8, a protease that cleaves protein chains after aspartic acid residues. Caspase 8 then cleaves and activates other caspases, which eventually leads to activation of caspase 3. Caspase 3 cleaves ICAD, the inhibitor of CAD (caspase activated DNase), which frees CAD to enter the nucleus and cleave DNA. Although caspase 3 is the pivotal execution caspase for apoptosis, the processes can be initiated by intrinsic signalling, which always involves mitochondrial release of cytochrome C and activation of caspase 9. The release of cytochrome C and mitochondrial inhibitor of lAPs is mediated via Bcl-2 family proteins (including Bax, Bak) forming pores in the mitochondrial membrane. Interestingly, the extrinsic apoptotic signal is aided and amplified by activation of tBid, which recruits Bcl-2 family members and hence also activates the intrinsic pathway. Apaf1, apoptotic protease activating factor 1; Bid, family member of Bcl-2 protein; IAPs, inhibitor of apoptosis proteins.
The extrinsic pathway is required for tissue remodeling and induction of immune self-tolerance. Cells marked for apoptosis express a member of the tumour necrosis factor (TNF) death receptor family, such as Fas, on their surfaces. Ligand binding (e.g. by Fas ligand expressed on lymphocytes) causes activation of adaptor proteins which produce a cascade of caspase activation. The extrinsic pathway can be amplified by induction of the intrinsic pathway (see below).
The intrinsic pathway centres on increased mitochondrial permeability and release of pro-apoptotic proteins like cytochrome C. Cellular stresses such as growth factor withdrawal, p53-dependent cell cycle arrest, DNA damage, and intracellular reactive oxygen species induce expression of pro-apoptotic Bcl-2 proteins, Bax and Bak. These enter the outer mitochondrial membrane forming pores that release cytochrome C which forms a complex (the apoptosome) with other proteins. The apoptosome activates a caspase cascade.
Stem cells
Following fertilization, the newly formed fertilized cell (the zygote) and those following the first few divisions are totipotent, meaning that they can differentiate into any cell type in the adult body. At the blastula stage of embryonic development, these cells undergo a primary differentiation event to become either the trophectoderm or the inner cell mass (ICM). The trophectoderm gives rise to the fetal cells of the placenta, while the ICM are pluripotent and give rise to all other cell types of the body (except those of the placenta), and are more commonly called embryonic stem (ES) cells. Stem cells have two properties:
Self renewal: the ability to divide indefinitely without differentiating.
Pluri- or toti-potency: the capability to differentiate, given the appropriate signals, into any cell type (except fetal placental cells).
As they begin to differentiate, their ability to self renew and their potency is reduced but there remain adult progenitor cells (sometimes erroneously referred to as stem cells), that have a limited ability to self renew and can differentiate into multiple related lineages (multipotent, like haematopoietic ‘stem cells’) or single lineages (unipotent, like muscle satellite cells). The body uses these partially differentiated progenitor cells to continually replace or repair damaged cells and tissues.
Stem cells have great therapeutic potential and can be obtained from blood from the umbilical cord, which contains embryonic-like stem cells (not as primitive as ES cells but can differentiate into many more cells types than adult progenitor cells) or by reprogramming adult cells to regain stem-like properties (induced pluripotent stem cells, IPSC).
FURTHER READING
Ben-David U, Benvenisty N. The tumorigenicity of human embryonic and induced pluripotent stem cells. Nat Rev Cancer 2011; 11(4):268–277.
Clevers H. The cancer stem cell: premises, promises and challenges. Nat Med 2011; 17(3):313–319.
Forraz N, McGuckin CP. The umbilical cord: a rich and ethical stem cell source to advance regenerative medicine. Cell Prolif 2011; 44(Suppl 1):60–69.
Robbins RD, Prasain N, Maier BF et al. Inducible pluripotent stem cells: not quite ready for prime time? Curr Opin Organ Transplant 2010; 15:61–67.
Wu SM, Hochedlinger K. Harnessing the potential of induced pluripotent stem cells for regenerative medicine. Nat Cell Biol 2011; 13:497–505.
Cancer ‘stem cells’
Only a very small proportion (<1%) of the individual cells from a cancer can form a cancer in a recipient immunodeficient mouse. These cells equate with the population that exclude the fluorescent drug Hoescht 3342 due to presence of a primary active (ABC) drug transporter on their cell surface. They have the characteristics of adult progenitor cells. The high relapse rate of many cancers may well be due to the persistence of these cancer ‘stem cells’ and new therapies are required to target these in the initial treatment regimen.
 Box 2.1
Box 2.1